Rust入门秘籍(更新中)
这是一本Rust的入门书籍,相比官方书籍《The Rust Programming Language》,本书要更详细、更具系统性,本书也尽量追求准确性。
但本人能力有限、见识有限、时间有限,我也不敢保证所写内容完全准确,如有发现错误之处,还请在博客www.junmajinlong.com/rust/index/的评论中指出,在此先行谢过。
本书目前还在不断更新中
本书目前(2022-09)随机更新:不定时更新、不定内容更新,抱歉了各位。
Rust入门第一课
注:本节暂时没有具体内容,是留在最后来补写的,目前只是列了一些todo
Rust是静态、编译、内存安全、可完全0运行时环境、可脱离操作系统、可编写操作系统的语言。同时也是非常严格的语言。学习Rust和写Rust代码都非常消耗脑力。
编译器是最好的资料、最严格的老师,程序员绝大多数时候都在和编译器对抗。它,亦师亦友亦敌。
- main(){}
- rustc
- cargo run –release
- cargo build –release
- 注释:// ///
- 分号结尾,表示这是一行Rust代码,Rust以行为最小单位来解析代码
- print!()
- println!() {} {:?} {:p}
- assert!()、assert_eq!()
Rust是基于表达式的语言
Rust是基于表达式的语言
Rust是基于表达式的语言,几乎所有代码都可以看作是表达式。
表达式计算后有返回值,例如3+4是一个表达式,它返回计算结果7。
与表达式对应的概念是语句,语句没有返回值或者不关心其返回值。例如Rust中变量赋值的代码let a=3;是语句。
在Rust中,可以在表达式结尾加上分号;来将表达式转换为【语句】。例如:
fn main(){
3 + 4;
}编译器发现表达式后有分号结尾时,在编译期间会自动修改代码,它会在分号的后面加上一个小括号()。单独的小括号是一个特殊的值,表示什么也不做。
所以,以上代码实际上等价于:
fn main(){
3+4;()
}带有分号表示这是一行Rust代码,Rust会先执行3+4得到7,然后忽略或丢弃该表达式的返回值7,再然后执行下一行代码,即一个单独的小括号,小括号表示什么也不做,直接跳过。
所以,代码3+4;从原本的表达式转变成了不关心返回值的【语句】。
除了在表达式尾部加分号的代码是语句之外,还有另外一种情况的代码是语句而非表达式:用于声明或定义的代码都是语句。例如let声明变量、fn定义函数、struct声明结构体等。
Rust很多地方都会结合表达式和语句来做变量赋值。例如,if结构也是一个表达式,所以它有返回值,可以将if的返回值赋值给变量,而它的返回值来自于它的大括号:当大括号最后执行的一条代码不加分号结尾时,该代码的计算结果就是if结构的返回值。
例如:
#![allow(unused)]
fn main() {
let x = if true {
println!("true");
33 // 分支的最后一条代码计算结果赋值给x,不能分号结尾
} else {
println!("false");
44 // 分支的最后一条代码计算结果赋值给x,不能分号结尾
}; // 这个结尾分号表示let语句的结尾分号
}上面的else分支不能缺少,不能缺少else的原因留待后面的章节再解释。
变量声明和函数定义
本章将介绍Rust中使用变量的细节以及定义函数的基础知识。
理解Rust中的变量赋值
理解Rust中的变量赋值
Rust中使用let声明变量:
fn main(){
// 声明变量name并初始化赋值
let name = "junmajinlong.com";
println!("{}", name); // println!()格式化输出数据
}Rust会对未使用的变量发出警告信息。如果确实想保留从未被使用过的变量,可在变量名前加上_前缀。
fn main(){
let name = "junmajinlong.com";
println!("{}", name);
let gender = "male"; // 警告,gender未使用
let _age = 18; // 加_前缀的变量不被警告
}Rust允许声明未被初始化(即未被赋值)的变量,但不允许使用未被赋值的变量。多数情况下,都是声明的时候直接初始化的。
fn main() {
let name; // 只声明,未初始化
// println!("{}", name); // 取消该行注释,将编译错误
name = "junmajinlong.com";
println!("{}", name);
}Rust允许重复声明同名变量,后声明的变量将遮盖(shadow)前面已声明的变量。需注意的是,遮盖不是覆盖,被遮盖的变量仍然存在,而如果是被覆盖则不再存在(也即,覆盖时,原数据会被销毁)。
fn main() {
let name = "junmajinlong.com";
// 注释下行,将警告:name变量未被使用
// 因为name仍然存在,只是被遮盖了
println!("{}", name);
let name = "gaoxiaofang.com"; // 遮盖已声明的name变量
println!("{}", name);
}变量遮盖示意图:
注:下图内存布局并不完全正确,此图仅为说明变量遮盖
+---------+ +--------------------+
| Stack | | Heap |
+---------+ +--------------------+
name --> | 0x56789 | ---> | "gaoxiaofang.com" |
| | +--------------------+
name --> | 0x01234 | ---> | "junmajinlong.com" |
+---------+ +--------------------+
变量初始化后,默认不允许再修改该变量。注意,修改变量是直接给变量赋值,而不是再次let声明该变量,再次声明变量是允许的,它会遮盖原变量。
fn main() {
let name = "junmajinlong.com";
// 取消下行注释将编译错误,默认不允许修改变量
// name = "gaoxiaofang.com";
let name = "gaoxiaofang.com"; // 再次声明变量,遮盖变量
println!("{}", name);
}如果想要修改变量的值,需要在声明变量时加上mut标记(mutable)表示该变量是可修改的。
fn main() {
let mut name = "junmajinlong.com";
println!("{}", name);
name = "gaoxiaofang.com"; // 修改变量
println!("{}", name);
}Rust不仅对未被使用过的变量发出警告,还对赋值过但未被使用过的值发出警告。比如变量赋值后,尚未读取该变量,就重新赋值了。
fn main() {
let mut name = "junmajinlong.com"; // 警告值未被使用过
name = "gaoxiaofang.com";
println!("{}", name);
}Rust是静态语言,声明变量时需指定该变量将要保存的值的数据类型,这样编译器编译时才知道为该变量将要保存的数据分配多少内存、允许存放什么类型的数据以及如何存放数据。但Rust编译器会根据所保存的值来推导变量的数据类型,推导得到确定的数据类型之后(比如第一次为该变量赋值之后),就不再允许存放其他类型的数据。
fn main() {
// 根据保存的值推导数据类型
// 推导结果:变量name为 &str 数据类型
let mut name = "junmajinlong.com";
//name = 32; // 再让name保存i32类型的数据,报错
}当Rust无法推导类型时,或者声明变量时就明确知道该变量要保存声明类型的数据时,可明确指定该变量的数据类型。
fn main() {
// 指定变量数据类型的语法:在变量名后加": TYPE"
let age: i32 = 32; // 明确指定age为i32类型
println!("{}", name);
// i32类型的变量想存储u8类型数据,不允许
// age = 23_u8;
}虽然Rust是基于表达式的语言,但变量声明的let代码是语句而非表达式。这意味着let操作没有返回值,因此无法使用let来连续赋值。
fn main(){
let a = (let b = 1); // 错误
}可以使用tuple的方式同时为多个变量赋值,并且可以使用下划线_占位表示忽略某个变量的赋值过程。
#![allow(unused)]
fn main() {
// x = 11, y = 22, 忽略33
let (x, y, _) = (11, 22, 33);
}事实上,_占位符比想象中还更会【偷懒】,其他语言中_表达的含义可能是丢弃其赋值结果(甚至不丢弃),但Rust中的_会直接忽略变量赋值的过程。这导致了这样一种看似奇怪的现象:使用普通变量名会导致报错的变量赋值行为,使用_却不会报错。
例如,下面(1)不会报错,而(2)会报错。这里涉及到了后面所有权转移的内容,如果看不懂请先跳过,只需记住结论:_会直接忽略赋值的过程。
#![allow(unused)]
fn main() {
// (1)
let s1 = "junmajinlong.com".to_string();
let _ = s1;
println!("{}", s1); // 不会报错
// (2)
let s2 = "junmajinlong.com".to_string();
let ss = s2;
println!("{}", s2); // 报错
}最后要说明的是,Rust中变量赋值操作实际上是Rust中的一种模式匹配,在后面的章节中将更系统、更详细地介绍Rust模式匹配功能。
定义函数
Rust中定义函数
Rust中使用fn关键字定义函数,定义函数时需指定参数的数据类型,如果有返回值,则需要指明返回值的数据类型。
fn关键字、函数名、函数参数及其类型、返回值类型组成函数签名。例如fn fname(a: i32, b: i32)->i32是一个函数签名。
定义函数参见如下几个简单的示例:
// 没有参数、没有返回值
fn f0(){
println!("first function_0");
println!("first function_1");
}
// 有参数,没有返回值
fn f1(a: i32, b: i32) {
println!("a: {}, b: {}", a, b);
}
// 有参数,有返回值
fn f2(a: i32, b: i32) -> i32 {
return a + b;
}
// 调用函数
fn main(){
f0();
f1(1,2);
f2(3,4);
}函数也可以直接定义在函数内部。例如在函数a中定义函数b,这样函数b就只能在函数a中访问或调用:
fn f0(){
println!("first function_0");
println!("first function_1");
fn f1(a: i32, b: i32) {
println!("a: {}, b: {}", a, b);
}
f1(2,3);
}
fn main(){
f0();
}Rust有两种方式指定函数返回值:
- 使用return来指定返回值,此时return后要加上分号结尾,使得return成为一个语句
- return关键字不指定返回值时,默认返回
()
- return关键字不指定返回值时,默认返回
- 不使用return,将返回最后一条执行的表达式计算结果,该表达式尾部不能带分号
- 不使用return,但如果最后一条执行的是一个分号结尾的语句,则返回
()
- 不使用return,但如果最后一条执行的是一个分号结尾的语句,则返回
参考如下函数定义:
#![allow(unused)]
fn main() {
fn f0(a: i32) -> i32{
if a > 0 {
// 使用return来返回,结尾处必须不能缺少分号
return a * 2;
}
// 最后执行的一条代码,使用表达式的结果作为函数返回值
// 结尾必须不能带分号
a * 2
}
}Rust原始数据类型
官方手册:https://doc.rust-lang.org/beta/std/index.html#primitives。
理解什么是原始数据类型(primitive type)
有些数据就是简简单单的,比如数字3,它就是一个数值3,编译器或解释器不需要任何其他信息来识别它,只要看到3就知道它是一个数值类型。
但是有些数据类型稍微复杂一点,除了要存储数据本身之外,编译器或解释器还需要再多保存一点关于该数据的元数据信息。比如数组类型,除了存储数组中各元素数据之外,还需要额外存储数组的长度信息,这样编译器或解释器才知道数组到哪里结束,这里数组的长度就是数组类型的元数据。
所谓原始数据类型,就是该类型的数据只需要数据本身即可,没有额外元数据。
Rust有很多种原始数据类型(primitive type),这些原始数据类型都是Rust内置的类型(在核心库core中定义而非标准库std中定义的类型)。包括数据大小固定的机器类型(Machine Type)、某些组合类型和其他一些Rust语言必要的内置类型。
包括:
- 机器类型(大小是固定的)
- bool
- u8、u16、u32、u64、u128、usize
- i8、i16、i32、i64、i128、isize
- f32、f64
- char
- 组合类型
- Tuple
- Array
- 其他语言必要类型
- Slice,即切片类型
- str,即字符串切片类型
- !,即never类型
- (),即Unit类型
- reference,即引用类型
- pointer,即裸指针类型
- fn,即函数指针类型
本章会介绍其中一些原始数据类型,还会额外简单地介绍一个非原始数据类型:String类型。
数值类型
Rust的数值类型包括整数和浮点数。有如下几种类型:
| 长度 | 有符号 | 无符号 | 浮点数 |
|---|---|---|---|
| 8-bit | i8 | u8 | |
| 16-bit | i16 | u16 | |
| 32-bit | i32(默认) | u32 | f32 |
| 64-bit | i64 | u64 | f64(默认) |
| 128-bit | i128 | u128 | |
| word | isize | usize |
注: word表示一个机器字长,通常是一个指针的大小,大小和机器有关。64位机器的word是64-bit,32位机器的word是32-bit。
可以在数值字面量后加上类型来表示该类型的数值。例如:
fn main(){
let _a = 33i32; // 直接加类型后缀
let _b = 33_i32; // 使用_分隔数值和类型
let _c = 33_isize;
let _d = 33_f32;
}如果数值较长,可以在任意位置处使用下划线_划分数值,增加可读性。
fn main(){
let _a = 33_333_33_i32;
let _b = 3_333_333_i32;
let _c = 3_333_333f32;
}当不明确指定变量的类型,也不明确指定数值字面量的类型后缀,Rust默认将整数当作i32类型,浮点数当作f64类型。
fn main(){
// 等价于 let _a: i32 = 33_i32;
let _a = 33;
// 等价于let _b: f64 = 64.123_f64;
let _b = 64.123;
}每种数值类型都有所能存储的最大数值和最小数值。当超出类型的有效范围时,Rust将报错(panic)。例如u8类型的范围是0-255,它无法存储256。
fn main() {
let n: i32 = std::i32::MAX; // i32类型的最大值
println!("{}", n + 1); // 编译错误,溢出
}Rust允许使用0b 0o 0x来表示二进制、八进制和十六进制的整数。
fn main(){
let a = 0b101_i32; // 二进制整数,i32类型
let b = 0o17; // 八进制整数,i32类型
let c = 0xac; // 十六进制整数,i32类型
println!("{}, {}, {}", a, b, c); // 5, 15, 172
}数值类型之间默认不会隐式转换,如果需要转换数值类型,可手动使用as进行转换(as主要用于原始数据类型间的类型转换)。例如3_i32 as u8表示将i32类型的3转换为u8类型。需注意,宽类型数值转为窄类型数值时,如果溢出,则从高位截断。
fn main(){
assert_eq!(10_i8 as u16, 10_u16);
assert_eq!(2525_u16 as i16, 2525_i16);
// 有符号类型->有符号类型
assert_eq!(-1_i16 as i32, -1_i32);
// 有符号到无符号类型
assert_eq!(-1_i32 as u8, 255_u8);
// 范围溢出,截断
assert_eq!(1000_i16 as u8, 232_u8);
// 浮点数转整数,小数部分被丢弃
assert_eq!(33.33_f32 as u8, 33_u8);
}Rust数值是一种类型的值,每种类型有自己的方法,因此数值也可以调用它们具有的方法。
fn main(){
// 需注意,下面的数值都加上了类型后缀。
// 这是因为在调用方法的时候,需要知道值的
// 所属类型才能找到这种类型具有的方法
println!("{}", 3_u8.pow(2)); // 9
println!("{}", (-3_i32).abs()); // 3
// 4,计算45的二进制中有多少个1
println!("{}", 45i32.count_ones()); // 4
}Rust将字节字面量存储为u8类型,字节字面量的表示方式为b'X'(b后面使用单引号包围单个ASCII字符)。
例如A的ASCII码为65,那么b'A'完全等价于65u8。
fn main(){
let a = b'A'; // a的类型自动推导为u8
let b = a - 65; // b的类型也自动推导为u8
println!("{}, {}", a, b); // 65, 0
}需注意,某些特殊ASCII字符需要使用反斜线转义,例如b'\n', b'\'', b'\\'。有些控制类的字符无法直接写出来,此时可以使用十六进制法来表示,例如b'\x1b'表示ESC按键的控制符。
布尔类型
Rust中的Boolean类型有两个值:true和false。
类似于if、while等的控制语句以及逻辑运算符|| && !都需要进行条件判断,Rust只允许在条件判断处使用布尔类型。
例如,要判断x是否等于0,在其他语言中可能允许如下写法:
#![allow(unused)]
fn main() {
if x {
...
}
}但在Rust中,不允许上面的写法(除非x的值自身就是true或false)。
Rust中必须得在条件判断处写返回值为true/false的表达式。例如写成如下形式:
#![allow(unused)]
fn main() {
if x == 0 {
...
}
}Rust的布尔值可以使用as操作符转换为各种数值类型,false对应0,true对应1。但数值类型不允许转换为bool值。再次提醒,as操作符常用于原始数据类型之间的类型转换。
fn main() {
println!("{}", true as u32);
println!("{}", false as u8);
// println!("{}", 1_u8 as bool); // 编译错误
}char类型
char类型
char官方手册:https://doc.rust-lang.org/beta/std/primitive.char.html
char类型是Rust的一种基本数据类型,用于存放单个unicode字符,占用4字节空间(32bit)。
在存储char类型数据时,会将其转换为UTF-8编码的数据(即Unicode代码点)进行存储。
char字面量是单引号包围的任意单个字符,例如'a'、'我'。注意:char和单字符的字符串String是不同的类型。
允许使用反斜线对某些特殊字符转义:
字符名 字节字面量
--------------------
单引号 '\''
反斜线 '\\'
换行符 '\n'
换页符 '\r'
制表符 '\t'
Rust不会自动将char类型转换为其他类型,但可以进行显式转换:
- 可使用
as将char转为各种整数类型,目标类型小于4字节时,将从高位截断 - 可使用
as将u8类型转char- 之所以不支持其他整数类型,是因为其他整数类型的值可能无法转换为char(即不在UTF-8编码表范围的整数值)
- 可使用
std::char::from_u32将u32整数类型转char,返回值Option<char>- 如果传递的u32数值不是有效的Unicode代码点,则
from_u32返回None - 否则返回
Some(c),c就是char类型的字符
- 如果传递的u32数值不是有效的Unicode代码点,则
- 可使用
std::char::from_digit(INT, BASE)将十进制的INT转换为BASE进制的char- 如果INT参数不是有效的进制数,返回None
- 如果BASE超出进制数的合理范围
[1,36],将panic - 否则返回
Some(c),c就是char类型的字符
例如:
#![allow(unused)]
fn main() {
// char -> Integer
println!("{}", '我' as i32); // 25105
println!("{}", '是' as u16); // 26159
println!("{}", '是' as u8); // 47,被截断了
// u8 -> char
println!("{}", 97u8 as char); // a
// std::char
use std::char;
println!("{}", char::from_u32(0x2764).unwrap()); // ❤
assert_eq!(char::from_u32(0x110000), None); // true
println!("{}", char::from_digit(4,10).unwrap()); // '4'
println!("{}", char::from_digit(11,16).unwrap()); // 'b'
assert_eq!(char::from_digit(11,10),None); // true
}字符串:str和String
字符串
Rust中的字符串是一个难点,此处先简单介绍关于字符串的一部分内容,更多细节和用法留到后面再单独解释。
Rust有两种字符串类型:str和String。其中str是String的切片类型,也就是说,str类型的字符串值是String类型的字符串值的一部分或全部。
字符串字面量
字符串字面量使用双引号包围。
fn main(){
let s = "junmajinlong.com";
println!("{}", s);
}上面赋值变量时进行了变量推导,推导出的变量数据类型为&str。因此,上述代码等价于:
fn main(){
let s: &str = "junmajinlong.com";
println!("{}", s);
}实际上,字符串字面量的数据类型均为&str,其中str表示str类型,&表示该类型的引用,即一个指针。因此,&str表示的是一个指向内存中str类型数据的指针,该指针所指向的内存位置处保存了字符串数据"junmajinlong.com"。
至于为什么字符串字面量的类型是&str而不是str,后文再解释。
String类型的字符串
String类型的字符串没有对应的字面量构建方式,只能通过Rust提供的方法来构建。
例如,可以通过字符串字面量(即&str类型的字符串)来构建。
fn main(){
// 类型自动推导为: String
let s = String::from("junmajinlong.com");
let s1 = "junmajinlong".to_string();
println!("{},{}", s, s1);
}String类型的字符串可以原地修改。例如:
fn main(){
let mut s = String::from("junmajinlong");
s.push('.'); // push()可追加单个char字符类型
s.push_str("com"); // push_str()可追加&str类型的字符串
println!("{}", s); // 输出:junmajinlong.com
}理解str和String的联系和区别
注:这部分内容对刚接触Rust的人来说较难理解,可先跳过,等阅读了后面一些章节再回来看。
str类型的字符串和String类型的字符串是有联系的:str字符串是String类型字符串的切片(slice)类型。关于切片类型,参考Slice类型。
例如,变量s保存了String类型的字符串junma,那么s[0..1]就是str类型的字符串j,s[0..3]就是str类型的字符串jun。
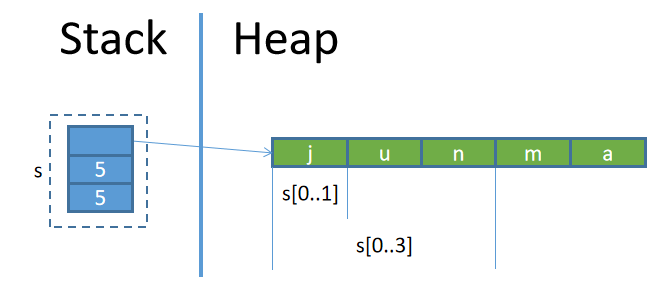
例如:
fn main(){
let s = String::from("junmajinlong.com");
// 自动推导数据类型为&str
// s[0..3]的类型为str
// &s[0..3]的类型为&str
let s_str = &s[0..3]; // 等价于&(s[0..3])而不是(&s)[0..3]
// 现在s_str通过胖指针引用了源String字符串中的局部数据
println!("{}", s_str); // 输出:jun
}前面说过,字符串字面量的类型是&str类型。也就是说,字符串字面量实际上是字符串切片类型的引用类型。
fn main(){
// IDE中可看到下面的变量推导出的数据类型为&str
let s = "hello";
}那么字符串字面量是如何存储的呢?
对于字面量"hello"来说,并不是先在内存中以String类型的方式存储"hello",然后再创建该String数据的引用来得到了一个&str的。
编译器对字符串字面量做了特殊处理:编译器编译的时候直接将字符串字面量以硬编码的方式写入程序二进制文件中,当程序被加载时,字符串字面量被放在内存的某个位置(不在堆中也不在栈中,而是在类似于静态数据区的全局字面量区)。当程序执行到let s="hello";准备将其赋值给变量s时(注:s在栈上),直接将字面量内存区的该数据地址保存到&str类型的s中。
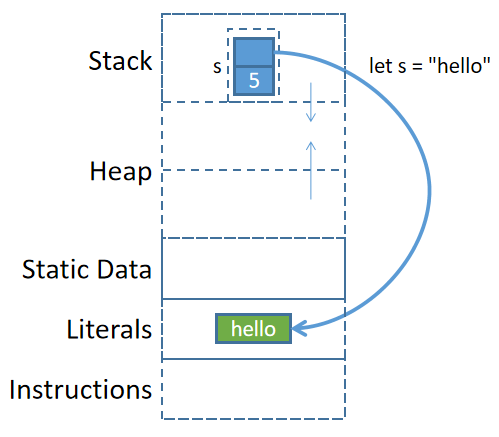
理解了这一点,再理解let s = String::from("hello");这样的代码就很容易了。编译器将"hello"硬编码写入程序二进制文件,程序加载期间字符串字面量被放入字面量内存区,当程序运行到let s = String::from()操作时,从字面量内存区将其拷贝到堆内存中,然后将堆内存中该数据的地址保存到栈内变量s中。
tuple类型
tuple类型
Rust的tuple类型可以存放0个、1个或多个任意数据类型的数据。使用tup.N的方式可以访问索引为N的元素。
#![allow(unused)]
fn main() {
let n = (11, 22, 33);
println!("{}", n.0); // 11
println!("{}", n.1); // 22
println!("{}", n.2); // 33
}注意,访问tuple元素的索引必须是编译期间就能确定的数值,而不能是变量。
#![allow(unused)]
fn main() {
let n = (11, 22, 33);
let a: usize = 2;
println!("{}", n.a); // 错误
}实际上,n.a会被Rust解析为对Struct类型的变量n的a字段的访问。
tuple通常用来作为简单的数据组合体。
例如:
fn main(){
// 表示一个人的name和age
let p_name = "junmajinlong";
let p_age = 23;
println!("{}, {}", p_name, p_age);
// 与其将有关联的数据分开保存到多个变量中,
// 不如保存在一个结构中
let p = ("junmajinlong", 23); // 同时存放&str和i32类型的数据
println!("{}, {}", p.0, p.1);
}Rust中经常会将tuple类型的各元素赋值给各变量,方式如下:
fn main(){
let p = ("junmajinlong", 23);
// 也可以类型推导:let (name,age) = p;
let (name, age): (&str, i32) = p;
// 比 let name = p.0; let age = p.1; 更简洁
println!("{}, {}", name, age);
}有时候tuple里只会保存一个元素,此时必须不能省略最后的逗号:
#![allow(unused)]
fn main() {
let p = ("junmajinlong",);
}unit类型
不保存任何数据的tuple表示为()。在Rust中,它是特殊的,它有自己的类型:unit。
unit类型的写法为(),该类型也只有一个值,写法仍然是()。参考下面的写法应该能搞清楚。
#![allow(unused)]
fn main() {
// 将值()保存到类型为()的变量x中
// 类型 值
let x: () = ();
}unit类型通常用在那些不关心返回值的函数中。在其他语言中,那些不写return语句或return不指定返回内容的的函数,一般表示不关心返回值。在Rust中可将这种需求写为return ()。
Array类型
Array类型
Rust中的数组和其他语言中的数组不太一样,Rust数组长度固定、元素类型相同。
数组的数据类型表示方式为[Type; N],其中:
- Type是该数组要存储什么类型的数据,数组中的所有元素类型都必须是Type
- N是数组的长度,Rust不会自动伸缩数组的长度
数组字面量使用中括号[]表示,例如[1,2,3]。还有一种特殊的表示数组字面量的方式是[val; N],这有点像数组类型的描述方式[Type; N],不过这里表示的是该数组长度为N,并且这N个元素的值都初始化为val。
例如:
fn main(){
// 自动推导类型为:[i32; 4]
let _arr = [11,22,33,44];
let _arr1: [&str; 3] = ["junma", "jinlong", "gaoxiao"];
// 自动推导类型为:[u8; 1024]
// 该数组初始化为1024个u8类型的0
// 可将之当作以0填充的1K的buf空间
let _arr2 = [0_u8; 1024];
}注意,[Type; N]是用来描述数据类型的,所以其中的N必须在编译期间就能确认,因此N不能是一个变量。
fn main(){
let n = 3;
// 编译错误,提示n不是常量值
let _arr1: [&str; n] = ["junma", "jinlong", "gaoxiao"];
}可以迭代数组,不过不能直接for i in arr{},而是for i in &arr{}或者for i in arr.iter(){}。例如:
fn main(){
let arr = [11,22,33,44];
for i in arr.iter() {
println!("{}", i);
}
}数组有很多方法可以使用,例如len()方法可以获取数组的长度。
fn main(){
let arr = [11,22,33,44];
println!("{}", arr.len()); // 4
}实际上,数组的方法都来自Slice类型。Slice类型后面会详细介绍。
Rust中的引用类型
Rust中的引用类型
本节简单介绍Rust中的引用,混个脸熟,后面会专门详细介绍引用以及引用更细节更底层的内容。
Rust中,使用&T表示类型T的引用类型(reference type)。
例如,&String表示String的引用类型,&i32表示i32的引用类型,&&i32表示i32引用的引用类型。
引用类型是一种数据类型,它表示其所保存的值是一个引用。
值的引用写法和引用类型的写法类似。例如&33表示的是33这个值的引用。
引用,通常来说是指向其他数据的一个指针或一个胖指针(有额外元数据的指针)。例如&33表示的是一个指向数据值33的一个指针。
因此,引用类型保存值的引用。
例如:
#![allow(unused)]
fn main() {
let n: &i32 = &33_i32;
}这里变量n的类型是引用类型&i32,它所保存的值必须是i32类型数据的引用,例如上面的&33_i32就是33_i32的引用。
可以将保存了引用的变量赋值给其他变量,这样就有多个变量拥有同一份数据的引用。
fn main(){
let n = 33;
let n_ref1 = &n; // n_ref1指向33
let n_ref2 = n_ref1; // n_ref2也指向33
}可以使用std::ptr::eq()来判断两个引用是否指向同一个地址,即判断所指向的数据是否是同一份数据。
fn main(){
let n = 33;
let n_ref1 = &n;
let n_ref2 = n_ref1;
println!("{}", std::ptr::eq(n_ref1, n_ref2)); // true
}可变引用
直接使用&创建出来的引用是只读的,这意味着可以通过该引用去读取其指向的数据,但是不能通过引用去修改指向的数据。
如果想要通过引用去修改源数据,需要使用&mut v来创建可修改源数据v的可变引用。
注意,想要通过&mut引用去修改源数据,要求原变量是可变的。这很容易理解,&mut是一个对源数据的引用,如果源数据本身就不允许修改,当然也无法通过&mut去修改这份数据。
因此,使用&mut的步骤大致如下:
#![allow(unused)]
fn main() {
let mut x = xxxx;
let x_ref = &mut x;
}例如,下面声明的变量n是不可变的,即使创建&mut n,也无法修改原始数据。实际上,这会导致编译错误。
fn main(){
let n = 33;
let n_ref = &mut n; // 编译错误
}因此,改为如下代码可编译通过:
fn main(){
let mut n = 33;
let n_ref = &mut n;
}解引用
解引用表示解除引用,即通过引用获取到该引用所指向的原始值。
解引用使用*T表示,其中T是一个引用(如&i32)。
例如:
fn main(){
let s = String::from("junma");
let s_ref = &s; // s_ref是指向"junma"的一个引用
// *s_ref表示通过引用s_ref获取其指向的"junma"
// 因此s和*s_ref都指向同一个"junma",它们是同一个东西
assert_eq!(s, *s_ref); // true
}再例如:
fn main(){
let mut n = 33;
let n_ref = &mut n;
n = *n_ref + 1;
println!("{}", n);
}Rust绝大多数时候不会自动地解除引用。但在某些环境下,Rust会自动进行解引用。
自动解引用的情况有(结论先总结在此,混脸熟,以后涉及到时再来):
- (1).使用
.操作符时(包括取属性值和方法调用),会隐式地尽可能解除或创建多层引用 - (2).使用比较操作符时,若比较的两边是相同类型的引用,则会自动解除引用到它们的值然后比较
对于(1),Rust会自动分析func()的参数,并在需要的时候自动创建或自动解除引用。例如以abc.func()有可能会自动转换为&abc.func(),反之,&abc.func()也有可能会自动转换为abc.func()。
对于(2),例如有引用类型的变量n,那么n > &30和*n > 30的效果是一样的。
Slice类型
Slice类型
Slice类型通常翻译为切片,它表示从某个包含多个元素的容器中取得局部数据,这个过程称为切片操作。不同语言对切片的支持有所不同,比如有些语言只允许取得连续的局部元素,而有些语言可以取得离散元素,甚至有些语言可以对hash结构进行切片操作。
Rust也支持Slice操作,Rust中的切片操作只允许获取一段连续的局部数据,切片操作获取到的数据称为切片数据。
Rust常见的数据类型中,有三种类型已支持Slice操作:String类型、Array类型和Vec类型(本文介绍的Slice类型自身也支持切片操作)。实际上,用户自定义的类型也可以支持Slice操作,只要自定义的类型满足一些条件即可,相关内容以后再介绍。
slice操作
有以下几种切片方式:假设s是可被切片的数据
s[n1..n2]:获取s中index=n1到index=n2(不包括n2)之间的所有元素s[n1..]:获取s中index=n1到最后一个元素之间的所有元素s[..n2]:获取s中第一个元素到index=n2(不包括n2)之间的所有元素s[..]:获取s中所有元素- 其他表示包含范围的方式,如
s[n1..=n2]表示取index=n1到index=n2(包括n2)之间的所有元素
例如,从数据s中取第一个元素和取前三个元素的切片示意图如下:

切片操作允许使用usize类型的变量作为切片的边界。例如,n是一个usize类型的变量,那么s[..n]是允许的切片操作。
slice作为数据类型
和其他语言的Slice不同,Rust除了支持切片操作,还将Slice上升为一种原始数据类型(primitive type),切片数据的数据类型就是Slice类型。
Slice类型是一个胖指针,它包含两份元数据:
- 第一份元数据是指向源数据中切片起点元素的指针
- 第二份元数据是切片数据中包含的元素数量,即切片的长度
例如,对于切片操作s[3..5],其起点指针指向s中index=3处的元素,切片长度为2。
Slice类型的描述方式为[T],其中T为切片数据的数据类型。例如对存放了i32类型的数组进行切片,切片数据的类型为[i32]。
由于切片数据的长度无法在编译期间得到确认(比如切片操作的边界是变量时s[..n]),而编译器是不允许使用大小不定的数据类型的,因此无法直接去使用切片数据(比如无法直接将它赋值给变量)。
fn main(){
let arr = [11,22,33,44,55];
let n: usize = 3;
// 编译错误,无法直接使用切片类型
let arr_s = arr[0..n];
}也因此,在Rust中几乎总是使用切片数据的引用。切片数据的引用对应的数据类型描述为&[T]或&mut [T],前者不可通过Slice引用来修改源数据,后者可修改源数据。
注意区分Slice类型和数组类型的描述方式。
数组类型表示为
[T; N],数组的引用类型表示为&[T; N],Slice类型表示为[T],Slice的引用类型表示为&[T]。
例如,对一个数组arr做切片操作,取得它的不可变引用arr_slice1和可变引用arr_slice2,然后通过可变引用去修改原数组的元素。
fn main(){
let mut arr = [11,22,33,44];
// 不可变slice
let arr_slice1 = &arr[..=1];
println!("{:?}", arr_slice1); // [11,22];
// 可变slice
let arr_slice2 = &mut arr[..=1];
arr_slice2[0] = 1111;
println!("{:?}", arr_slice2);// [1111,22];
println!("{:?}", arr);// [1111,22,33,44];
}需要说明的一点是,虽然[T]类型和&[T]类型是有区别的,前者是切片类型,后者是切片类型的引用类型,但因为几乎总是通过切片类型的引用来使用切片数据,所以通常会去混用这两种类型(包括一些书籍也如此),无论是[T]还是&[T]都可以看作是切片类型。
特殊对待的str切片类型
需要特别注意的是,String的切片和普通的切片有些不同。
一方面,String的切片类型是str,而非[String],String切片的引用是&str而非&[String]。
另一方面,Rust为了保证字符串总是有效的Unicode字符,它不允许用户直接修改字符串中的字符,所以也无法通过切片引用来修改源字符串,除非那是ASCII字符(ASCII字符总是有效的unicode字符)。
事实上,Rust只为&str提供了两个转换ASCII大小写的方法来修改源字符串,除此之外,没有为字符串切片类型提供任何其他原地修改字符串的方法。
fn main(){
let mut s = String::from("HELLO");
let ss = &mut s[..];
// make_ascii_lowercase()
// make_ascii_uppercase()
ss.make_ascii_lowercase();
println!("{}", s); // hello
}Array类型自动转换为Slice类型
在Slice的官方手册中,经常会看到将Array的引用&[T;n]当作Slice来使用。
例如:
#![allow(unused)]
fn main() {
let arr = [11,22,33,44];
let slice = &arr; // &arr将自动转换为slice类型
// 调用slice类型的方法first()返回slice的第一个元素
println!("{}", slice.first().unwrap()); // 11
}所以,可以直接将数组的引用当成slice来使用。即&arr和&mut arr当作不可变slice和可变slice来使用。
另外,在调用方法的时候,由于.操作符会自动创建引用或解除引用,因此Array可以直接调用Slice的所有方法。
例如:
#![allow(unused)]
fn main() {
let arr = [11, 22, 33, 44];
// 点运算符会自动将arr.first()转换为&arr.first()
// 而&arr又会自动转换为slice类型
println!("{}", arr.first().unwrap());
}这里需要记住这个用法,但目前请忽略以上自动转换行为的内部原因,其涉及到尚未介绍的类型转换机制。
Slice类型支持的方法
Slice支持很多方法,这里介绍几个比较常用的方法,更多方法可参考官方手册:https://doc.rust-lang.org/std/primitive.slice.html#impl。
注:这些方法都不适用于String Slice,String Slice可用的方法较少,上面给出官方手册中,除了方法名中有“ascii“的方法(如is_ascii()方法)是String Slice可使用的方法外,其他方法都不能被String Slice调用。
一些常见方法:
- len():取slice元素个数
- is_empty():判断slice是否为空
- contains():判断是否包含某个元素
- repeat():重复slice指定次数
- reverse():反转slice
- join():将各元素压平(flatten)并通过指定的分隔符连接起来
- swap():交换两个索引处的元素,如
s.swap(1,3) - windows():以指定大小的窗口进行滚动迭代
- starts_with():判断slice是否以某个slice开头
例如:
#![allow(unused)]
fn main() {
let arr = [11,22,33];
println!("{}", arr.len()); // 3
println!("{:?}", arr.repeat(2)); // [11, 22, 33, 11, 22, 33]
println!("{:?}", arr.contains(&22)); // true
// reverse()
let mut arr = [11,22,33];
arr.reverse();
println!("{:?}",arr); // [33,22,11]
// join()
println!("{}", ["junma","jinlong"].join(" ")); // junma jinlong
println!("{:?}", [[1,2],[3,4]].join(&0)); // [1,2,0,3,4]
// swap()
let mut arr = [1,2,3,4];
arr.swap(1,2);
println!("{:?}", arr); // [1,3,2,4]
// windows()
let arr = [10, 20, 30, 40];
for i in arr.windows(2) {
println!("{:?}", i); // [10,20], [20,30], [30,40]
}
// starts_with(),相关的方法还有ens_with()
let arr = [10, 20, 30, 40];
println!("{}", arr.starts_with(&[10])); // true
println!("{}", arr.starts_with(&[10, 20])); // true
println!("{}", arr.starts_with(&[30])); // false
}Rust操作符和流程控制语句
本章将介绍Rust中的一些操作符以及流程控制结构。
Rust操作符
Rust操作符
操作符(Operator)通常是由一个或多个特殊的符号组成(也有非特殊符号的操作符,如as),比如+ - * / % & *等等,每个操作符都代表一种动作(或操作),这种动作作用于操作数之上。简单来说,就是对操作数执行某种操作,然后返回操作后得到的结果。
比如加法操作3 + 2,这里的+是操作符,加号两边的3和2是操作数,加法符号的作用是对操作数3加上操作数2,得到计算结果5,然后返回5。
此处仅列出一部分操作符并给出它们的含义,剩下其他的操作符将在后面章节涉及到的时候再介绍。
| 操作符类别 | 操作符及描述 | 示例 |
|---|---|---|
| 一元运算符 | -:取负(加负号) | -x |
!:对整数值是位取反,对布尔值是逻辑取反 | !x | |
| 算术运算符 | + - * / %:加、减、乘、除、取模 | x + y |
| 位运算符 | `& | ^ ! << >>`:位与、位或、位异或、位取反、左移、右移 |
| 逻辑运算符 | `& && | |
| 赋值操作符 | = | x = y |
| 复合赋值操作符 | `+= -= *= /= %= &= | = ^= <<= >>=` |
| 等值比较运算符 | == !=:相等和不等 | x == y |
| 大小比较运算符 | < <= > >=:小于、小于等于、大于、大于等于 | x > y |
以上操作符有几点需要说明:
-
各种运算符有优先级,可使用小括号
()来强制改变多个运算符运算时的优先级,如(x + y) * z -
! & |操作符有两种意思,根据上下文决定:- 操作数是整数值时:按位取反、按位与、按位或
- 操作数是布尔值时:逻辑取反、逻辑与、逻辑或
-
& &&都表示逻辑与,但后者会短路计算。同理| ||都表示逻辑或,但后者会短路计算例如,
false & true在知道左边的操作数是false后,仍然会计算右边的操作数,而false && true知道左边是false后,已经能够确定整个表达式的结果是false,它会直接返回false,而不会再计算右边的操作数。#![allow(unused)] fn main() { // 不会panic报错退出,因为不会评估 || 运算符右边的操作数 if true || panic!("not bang!!!") {} // 会panic报错退出,因为会评估 | 运算符右边的操作数 if true | panic!("bang!!!") {} }
范围表达式
范围(Range)表达式
Rust支持范围操作符,有以下几种表示范围的操作符:
| 范围表达式 | 类型 | 表示的范围 |
|---|---|---|
| start..end | std::ops::Range | start ≤ x < end |
| start.. | std::ops::RangeFrom | start ≤ x |
| ..end | std::ops::RangeTo | x < end |
| .. | std::ops::RangeFull | - |
| start..=end | std::ops::RangeInclusive | start ≤ x ≤ end |
| ..=end | std::ops::RangeToInclusive | x ≤ end |
例如,1..5表示1、2、3、4共四个整数,1..=5表示1、2、3、4、5共五个整数。
需注意的是其中表示全范围的表达式..,它表示可以尽可能地生成下一个数,直到无法生成为止。
在生成Slice的时候,需要使用到范围表达式。例如,从数组生成Slice:
#![allow(unused)]
fn main() {
let arr = [11, 22, 33, 44, 55];
let s1 = &arr[0..3]; // [11,22,33]
let s2 = &arr[1..=3]; // [22, 33, 44]
let s3 = &arr[..]; // [11, 22, 33, 44, 55]
}范围表达式也常被用于迭代操作。例如for语句:
#![allow(unused)]
fn main() {
for i in 1..5 {
println!("{}", i); // 1 2 3 4
}
}另外,范围表达式和对应类型的实例是等价的。例如,下面两个表示范围的方式是等价的:
#![allow(unused)]
fn main() {
let x = 0..5;
let y = std::ops::Range {start: 0, end: 5};
}流程控制结构
流程控制结构
流程控制结构包括:
- if条件判断结构
- loop循环
- while循环
- for..in迭代
除此之外,还有其他几种本节暂不介绍的控制结构。
需要说明的是,Rust中这些结构都是表达式,它们都有默认的返回值(),且if结构和loop循环结构可以指定返回值。
注:【这些结构的默认返回值是
()】的说法是不严谨的之所以可以看作是默认返回
(),是因为Rust会在每个分号结尾的语句后自动加上小括号(),使得语句看上去也有了返回值。为了行文简洁,下文将直接描述为默认返回值。
if..else
if语句的语法如下:
#![allow(unused)]
fn main() {
if COND1 {
...
} else if COND2 {
...
} else {
...
}
}其中,条件表达式COND不需要加括号,且COND部分只能是布尔值类型。另外,else if分支是可选的,且可以有多个,else分支也是可选的,但最多只能有一个。
由于if结构是表达式,它有返回值,所以可以将if结构赋值给一个变量(或者其他需要值的地方)。
但是要注意,if结构默认返回Unit类型的(),这个返回值是没有意义的。如果要指定为其他有意义的返回值,要求:
- 分支最后执行的那一行代码不使用分号结尾,这表示将最后执行的这行代码的返回值作为if结构的返回值
- 每个分支的返回值类型相同,这意味着每个分支最后执行的代码都不能使用分号结尾
- 必须要有else分支,否则会因为所有分支条件判断都不通过而直接返回if的默认返回值
()
下面用几个示例来演示这几个要求。
首先是一段正确的代码片段:
#![allow(unused)]
fn main() {
let x = 33;
// 将if结构赋值给变量a
// 下面if的每个分支,其返回值类型都是i32类型
let a = if x < 20 {
// println!()不是该分支最后一条语句,要加结尾分号
println!("x < 20");
// x+10是该分支最后一条语句,
// 不加分号表示将其计算结果返回,返回类型为i32
x + 10
} else if x < 30 {
println!("x < 30");
x + 5 // 返回x + 5的计算结果,返回类型为i32
} else {
println!("x >= 30");
x // 直接返回x,返回类型为i32
}; // if最后一个闭大括号后要加分号,这是let的分号
}下面是一段将if默认返回值()赋值给变量的代码片段:
#![allow(unused)]
fn main() {
let x = 33;
// a被赋值为`()`
let a = if x < 20 {
println!("x < 20");
};
println!("{:?}", a); // ()
}下面不指定else分支,将报错:
#![allow(unused)]
fn main() {
let x = 33;
// if分支返回i32类型的值
// 但如果没有执行if分支,则返回默认值`()`
// 这使得a的类型不是确定的,因此报错
let a = if x < 20 {
x + 3 // 该分支返回i32类型
};
}下面if分支和else if分支返回不同类型的值,将报错:
#![allow(unused)]
fn main() {
let x = 33;
let a = if x < 20 {
x + 3 // i32类型
} else if x < 30 {
"hello".to_string() // String类型
} else {
x // i32类型
};
}由于if的条件表达式COND部分要求必须是布尔值类型,因此不能像其他语言一样编写类似于if "abc" {}这样的代码。但是,却可以在COND部分加入其他语句,只要保证COND部分的返回值是bool类型即可。
例如下面的代码。注意下面使用大括号{}语句块包围了if的COND部分,使得可以先执行其他语句,在语句块的最后才返回bool值作为if的分支判断条件。
#![allow(unused)]
fn main() {
let mut x = 0;
if {x += 1; x < 3} {
println!("{}", x);
}
}这种用法在if结构上完全是多此一举的,但COND的这种用法也适用于while循环,有时候会有点用处。
while循环
while循环的语法很简单:
#![allow(unused)]
fn main() {
while COND {
...
}
}其中,条件表达式COND和if结构的条件表达式规则完全一致。
如果要中途退出循环,可使用break关键字,如果要立即进入下一轮循环,可使用continue关键字。
例如:
#![allow(unused)]
fn main() {
let mut x = 0;
while x < 5 {
x += 1;
println!("{}", x);
if x % 2 == 0 {
continue;
}
}
}根据前文对if的条件表达式COND的描述,COND部分允许加入其他语句,只要COND部分最后返回bool类型即可。例如:
#![allow(unused)]
fn main() {
let mut x = 0;
// 相当于do..while
while {println!("{}", x);x < 5} {
x += 1;
if x % 2 == 0 {
continue;
}
}
}最后,while虽然有默认返回值(),但()作为返回值是没有意义的。因此,不考虑while的返回值问题。
loop循环
loop表达式是一个无限循环结构。只有在loop循环体内部使用break才能终止循环。另外,也使用continue可以直接跳入下一轮循环。
例如,下面的循环结构将输出1、3。
#![allow(unused)]
fn main() {
let mut x = 0;
loop {
x += 1;
if x == 5 {
break;
}
if x % 2 == 0 {
continue;
}
println!("{}", x);
}
}loop也有默认返回值(),可以将其赋值给变量。例如,直接将上例的loop结构赋值给变量a:
#![allow(unused)]
fn main() {
let mut x = 0;
let a = loop {
...
};
println!("{:?}", a); // ()
}作为一种特殊情况,当在loop中使用break时,break可以指定一个loop的返回值。
#![allow(unused)]
fn main() {
let mut x = 0;
let a = loop {
x += 1;
if x == 5 {
break x; // 返回跳出循环时的x,并赋值给变量a
}
if x % 2 == 0 {
continue;
}
println!("{}", x);
};
println!("var a: {:?}", a); // 输出 var a: 5
}注意,只有loop中的break才能指定返回值,在while结构或for迭代结构中使用的break不具备该功能。
for迭代
Rust中的for只具备迭代功能。迭代是一种特殊的循环,每次从数据的集合中取出一个元素是一次迭代过程,直到取完所有元素,才终止迭代。
例如,Range类型是支持迭代的数据集合,Slice类型也是支持迭代的数据集合。
但和其他语言不一样,Rust数组不支持迭代,要迭代数组各元素,需将数组转换为Slice再进行迭代。
#![allow(unused)]
fn main() {
// 迭代Range类型:1..5
for i in 1..5 {
println!("{}", i);
}
let arr = [11, 22, 33, 44];
// arr是数组,&arr转换为Slice,Slice可迭代
for i in &arr {
println!("{}", i);
}
}标签label
可以为loop结构、while结构、for结构指定标签,break和continue都可以指定标签来确定要跳出哪一个层次的循环结构。不仅如此,任何一个独立的{}语句块都可以加上标签,并使用break来提前退出标签。
例如:
#![allow(unused)]
fn main() {
// 'outer和'inner是标签名
'outer: loop {
'inner: while true {
break 'outer; // 跳出外层循环
}
}
}需注意,loop结构中的break可以同时指定标签和返回值,语法为break 'label RETURN_VALUE。
例如:
#![allow(unused)]
fn main() {
let x = 'outer: loop {
'inner: while true {
break 'outer 3;
}
};
println!("{}", x); // 3
}还可以为独立的{}语句块添加标签,并在某些条件下提前退出语句块,在有些场景下非常友好:
#![allow(unused)]
fn main() {
'hello: {
if COND {
CODE1...
break 'hello;
}
// 如果执行了上面的break,就不会执行到下面的代码
CODE2...
}
}理解Rust内存管理
Rust是内存安全、没有GC(垃圾回收)的高效语言。使用Rust,需要正确理解Rust管理内存的方式。
本章简单介绍一些有关于Rust内存的内容,更多细节则分散在其他各知识点中。
Rust没有严格定义其使用的内存模型(即没有相关规范说明),但可以粗略理解为使用下图内存布局:

堆空间和栈空间
堆空间和栈空间
Rust语言区分堆空间和栈空间,虽然它们都是内存中的空间,但使用堆和栈的方式不一样,这也使得使用堆和栈的效率有所区别。
栈空间和栈帧
栈空间和栈帧都是属于操作系统的概念,操作系统负责管理栈空间,负责创建、释放栈帧。
栈空间采用后进先出的方式存放数据(就像叠盘子)。每次调用函数,都会在栈的顶端创建一个栈帧(stack frame),用来保存该函数的上下文数据。比如该函数内部声明的局部变量通常会保存在栈帧中。当该函数返回时,函数返回值也保留在该栈帧中。当函数调用者从栈帧中取得该函数返回值后,该栈帧被释放(实际上不会真的释放栈帧的空间,无效的栈帧可以被复用)。
实际上,有一个ESP寄存器专门用来跟踪栈帧,该寄存器中保存了当前最顶端的栈帧地址。当调用函数创建新的栈帧时(栈帧总是在栈顶创建),ESP寄存器的值更新为此栈帧的地址,当函数返回且返回值已被读取后,该函数栈帧被移除出栈,出栈的方式很简单,只需更新ESP寄存器使其指向上一个栈帧的地址即可。
不仅栈空间中的栈帧是后进先出的,栈帧内部的数据也是后进先出的。比如函数内先创建的局部变量在栈帧的底部,后创建的局部变量在栈帧的顶部。当然,上下顺序并非一定会如此,这和编译器有关,但编写程序时可如此理解。
实际上,有一个EBP寄存器专门用来跟踪调用者栈帧的位置。当在函数a中调用函数b时,首先创建函数a的栈帧,当开始调用函数b时,将在栈顶创建函数b的栈帧,并拷贝上一个ESP的值到EBP,这样EBP寄存器就保存了函数a的栈帧地址,当函数b返回时通过EBP就可以回到函数a的栈帧。
在编写代码的时候,通常不考虑属于操作系统的栈空间和栈帧的概念,而是这样思考:有一块内存,这块内存中存放数据的方式是后进先出。比如,调用函数时,函数内部的局部变量可以说成【存放在栈中或栈空间中】,而不将其具体到【存放在该函数的栈帧中】。也就是说,此时可以混用栈和栈空间的说法,且重在描述(主要是为了将栈和堆区分开来)而不是侧重于其准确性。后文也都如此混用栈和栈空间。
堆内存
不同于栈空间由操作系统跟踪管理,堆内存是一片无人管理的自由内存区,需要时要手动申请,不需要时要手动释放,如果不释放已经无用的堆内存,将导致内存泄漏,内存泄漏过多(比如在某个循环内不断泄漏),可能会耗尽内存。
手动申请、手动释放堆内存是一件非常难的事,特别是程序较大时,判断在何处编写释放内存的代码更是难上加难。所以有一些语言提供了垃圾回收器(GC)来自动管理堆内存的回收。
Rust没有提供GC,也无需手动申请和手动释放堆内存,但Rust是内存安全的。这是因为Rust使用了自己的一套内存管理机制,只要能够编译通过,多数情况下可以保证程序没有内存问题。
其中机制之一是作用域:Rust中所有的大括号都是一个独立的作用域,作用域内的变量在离开作用域时会失效,而变量绑定的数据(无论绑定的是堆内数据还是栈中数据)则自动被释放。
fn main(){
{ // 大括号,一个独立的作用域
let n = 33;
println!("{}", n);
} // 变量n在此失效,其绑定的数据33被释放
// 此处无法再使用变量n
// println!("{}", n); // 编译错误
}关于Rust更多的内存管理机制(如所有权系统、生命周期等),放在后面的章节再解释。
Rust如何使用堆和栈
Rust如何使用堆和栈
有些数据适合存放于堆,有些数据适合存放于栈。
(1).栈适合存放存活时间短的数据。
比如函数内部的局部变量适合存放在栈中,因为函数返回后,该函数中声明的局部变量就没有意义了,随着函数栈帧的释放,该栈中的所有数据也随之消失。
与之对应的,存活时间长的数据通常应该存放在堆空间中。比如多个函数(有不同栈帧)共用的数据应该存放在堆中,这样即使一个函数返回也不会销毁这份数据。
(2).数据要存放于栈中,要求数据所属数据类型的大小是已知的。因为只有这样,Rust编译器才知道在栈中为该数据分配多少内存。
与之对应的,如果无法在编译期间得知数据类型的大小,该数据将不允许存放在栈中,只能存放在堆中。
例如,i32类型的数据存放在栈中,因为i32类型的大小是固定的,无论对它做什么操作,只要它仍然是i32类型,那么它的大小就一定是4字节。而String类型的数据是存放在堆中的,因为String类型的字符串是可变而非固定大小的,最初初始化的时候可能是空字符串,但可以在后期向此空字符串中加入任意长度的字符串,编译器显然无法在编译期间就得知字符串的长度。
(3).使用栈的效率要高于使用堆。
将数据存放于栈中时,因为编译器已经知道将要存放于栈中数据的大小,所以编译器总是在栈帧中分配合适大小的内存来存放数据。另一方面,栈中数据的存放方式是后进先出。这相当于编译器总是找好各种大小合适的盒子来存放数据并将盒子放在栈的顶部,而释放栈中数据的方式则是从栈顶拿走盒子。
与之对应的是将数据存放于堆中时,当程序运行时会向操作系统申请一片空闲的堆内存空间,然后将数据存放进去。但是堆内存空间是无人管理的自由内存区,操作系统想要从堆中找到空闲空间需要做一些额外操作。更严重的是堆中有大量碎片内存的情况,操作系统可能会将多份小的碎片空闲内存通过链表的方式连接起来组成一个大的空闲空间分配给程序,这样的效率是非常低的。
对比堆和栈的使用方式,显然以【盒子】为操作单位且总是跟踪栈顶的栈内存管理方式的效率要远高于堆。
其实,可以将栈理解为将物品放进大小合适的纸箱并将纸箱按规律放进储物间,将堆理解为在储物间随便找一个空位置来放置物品。显然,以纸箱为单位来存取物品的效率要高的多,而直接将物品放进凌乱的储物间的效率要低的多,而且储物间随意堆放的东西越多,空闲位置就越零碎,存取物品的效率就越低,且空间利用率就越低。
用一张图来描述它们:

(4).Rust将哪些数据存放于栈中?
Rust中各种类型的值默认都存储在栈中,除非显式地使用Box::new()将它们存放在堆上。
但数据要存放在栈中,要求其数据类型的大小已知。对于静态大小的类型,可直接存储在栈上。
例如如下类型的数据存放在栈中:
- 裸指针(一个机器字长)、普通引用(一个机器字长)、胖指针(除了指针外还包含其他元数据信息,智能指针也是一种带有额外功能的胖指针,而胖指针实际上又是Struct结构)
- 布尔值
- char
- 各种整数、浮点数
- 数组(Rust数组的元素数据类型和数组长度都是固定不变的)
- 元组
对于动态大小的类型(如Vec、String),则数据部分分布在堆中(被称为allocate buffer),并在栈中留下胖指针(Struct方式实现)指向实际的数据,栈中的那个胖指针结构是静态大小的(换句话说,动态类型以Vec为例,Vec类型的值理应是那些连续的元素,但因为这样的连续内存的大小是不确定的,所以改变了它的行为,它的值是那个栈中的胖指针,而不是存储在allocatge buffer中的实际数据)。
以上分类需要注意几点:
- 将栈中数据赋值给变量时,数据直接存放在栈中。比如i32类型的33,33直接存放在栈内,而不是在堆中存放33并在栈中存放指向33的指针
- 因为类型的值默认都分布在栈中(即便是动态类型的数据,但也通过胖指针改变了该类型的值的表现形式),所以创建某个变量的引用时,引用的是栈中的那个值
- 有些数据是0字节的,不需要占用空间,比如
() - 尽管【容器】结构中(如数组、元组、Struct)可以存放任意数据,但保存在容器中的要么是原始类型的栈中值,要么是指向堆中数据的引用,所以这些容器类型的值也在栈中。例如,对于
struct User {name: String},name字段存储的是String类型的胖指针,String类型实际的数据则在堆中 - 尽管
Box::new(T)可以将类型T的数据放入堆中,但Box类型本身是一个struct,它是一个胖指针(更严格地说是智能指针),它在栈中
实际上,对于理解来说,只有Box才能让数据存放到堆中,但对于实现上,只有调用alloc才能申请堆内存并将数据存放在堆中。比如,自己想实现一个类型,将某些数据明确存放在堆中,那么必须要在实现代码中调用alloc来分配堆内存,但同时,要实现的这个类型本身,它的值是在栈中的。
(5).Rust除了使用堆栈,还使用全局内存区(静态变量区和字面量区)。
Rust编译器会将全局内存区的数据直接嵌入在二进制程序文件中,当启动并加载程序时,嵌入在全局内存区的数据被放入内存的某个位置。
全局内存区的数据是编译期间就可确定的,且存活于整个程序运行期间。
字符串字面量、static定义的静态变量(相当于全局变量)都会硬编码嵌入到二进制程序的全局内存区。
例如:
fn main(){
let _s = "hello"; // (1)
let _ss = String::from("hello"); // (2)
let _arr = ["hello";3]; // (3)
let _tuple = ("hello",); // (4)
// ...
}上面代码中的几个变量都使用了字符串字面量,且使用的都是相同的字面量"hello",在编译期间,它们会共用同一个"hello",该"hello"会硬编码到二进制程序文件中。当程序被加载到内存时,该被放入到全局内存区,它在全局内存区有自己的内存地址,当运行到以上各行代码时:
- 代码(1)、(3)、(4),将根据地址取得其引用,并分别保存到变量
_s、_arr各元素、_tuple元素中 - 代码(2),将根据地址取得数据并将其拷贝到堆中(转换为
Vec<u8>的方式存储,它是String类型的底层存储方式)
(6).Rust中允许使用const定义常量。常量将在编译期间直接以硬编码的方式内联(inline)插入到使用常量的地方。
所谓内联,即将它代表的值直接替换到使用它的地方。
比如,定义了常量ABC=33,在第100行和第300行处都使用了常量ABC,那么在编译期间,会将33硬编码到第100行和第300行处。
Rust中,除了const定义的常量会被内联,某些函数也可以被内联。将函数进行内联,表示将该函数对应的代码体直接展开并插入到调用该函数的地方,这样就没有函数调用的开销(比如没有调用函数时申请栈帧、在寄存器保存某些变量等的行为),效率会更高一些。但只有那些频繁调用的短函数才适合被内联,并且内联会导致程序的代码膨胀。
通过位置和值理解内存模型
Rust位置表达式和值
在Rust中,非常有必要理解的概念是位置表达式和值,或者简化为位置和值,理解这两个概念,对理解Rust的内存布局、引用、指针、变量等等都有很大帮助。
位置就是某一块内存位置,它有自己的地址,有自己的空间,有自己所保存的值。每一个位置,可能位于栈中,可能位于堆中,也可能位于全局内存区。
值就是存储到位置中的数据(即保存在内存中的数据)。值的类型有多种,如数值类型的值、字符类型的值、指针类型的值(包括裸指针和胖指针),等等。
通过示例来理解变量、位置和值的关系
最简单的,let声明变量时,需要产生一个位置来存放数据。
对于下面的代码:
#![allow(unused)]
fn main() {
let n = 33;
}对应的内存如下图左侧所示。
其中:
- n称为变量名。变量名是语言层面上提供的一个别名,它是对内存位置的一个人类可读的代号名称,在编译期间,变量名会被移除掉并替换为更低级的代号甚至替换为内存地址
- 这里的变量名n对应栈中的一个位置,这个位置中保存了值33
- 位置有自己的内存地址,如图中的
0x123 - 有时候,会将这种声明变量时的位置看作是变量(注意不是变量名),或者将变量看作是位置。无论如何看待两者,我们内心需要明确的是,变量或这种位置,是栈中的一块内存
- 每个位置(或变量),都是它所存放的值的所有者。因为每个值都只能存放在一个位置中,所以每个值都只能有一个所有者
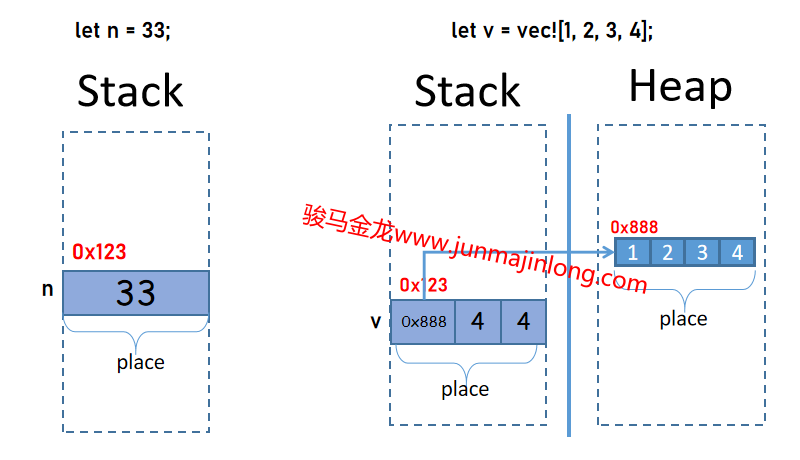
上面是将数值33赋值给变量,Rust中的i32是原始数据类型,默认i32类型的值直接保存在栈中。因此,左图的内存位置中,仅仅只是保存了一个数值33。
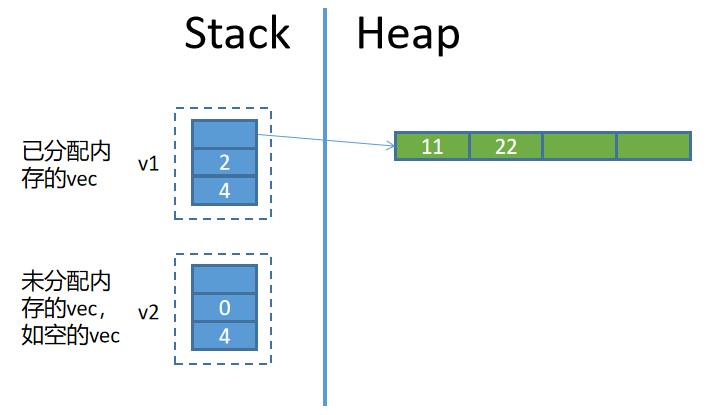
如果赋值给变量的是保存在堆中的数据(例如Vec类型),那么变量中保存的是该数据的胖指针。
#![allow(unused)]
fn main() {
let v = vec![1, 2, 3, 4];
}其内存布局如右图所示。在右图中,有两个位置:一个位置在堆内存中,用于存放实际数据,它是由一连串空间连续的小位置组成的一个大位置,每个小位置存放了对应的值;第二个位置在栈中,它存放的是Vec的胖指针。
这两个位置都有自己的地址,都有自己的值。其中,栈中的那个位置,是变量声明时显式创建的位置,这个位置代表的是Vec类型的变量,而堆中的位置是自动隐式产生的,这个位置和变量没有关系,唯一的关联是栈中的那个位置中有一根指针指向这个堆中的位置。
需要说明的是,对于上面的Vec示例,Vec的值指的是存放在栈中那个位置内的数据,而不是堆中的存放的实际数据。也就是说,变量v的值是那个胖指针,而不是堆中的那串实际数据。更严格地说,Vec类型的值,指的是那个胖指针数据,而不是实际数据,变量v的值是那个胖指针而不是实际数据,变量v是胖指针这个值的所有者,而不是实际数据的所有者。这种变量和值之间的关系和其它某些语言可能有所不同。
理解变量的引用
Rust中的引用是一种指针,只不过Rust中还附带了其它编译期特有的含义,例如是引用会区分是否可变、引用是借用概念的实现形式。
但不管如何,Rust中的引用是一种原始数据类型,它的位置认在栈中,保存的值是一种地址值,这个地址指向它所引用的目标。
关键问题,引用所指向的这个目标是谁呢?这里有几种让人疑惑的指向可能:
- (1).指向它所指向的那个变量(即指向位置)
- (2).指向位置中的值
- (3).指向原始数据
在Rust中,正确的答案是:指向位置。(参考链接:Operator expressions - The Rust Reference (rust-lang.org))
例如:
#![allow(unused)]
fn main() {
let n = 33;
let nn = &n;
}在这个示例中,变量n对应栈中的一个位置,这个位置中保存了数据值33,这个位置有一个地址0xabc,而对于变量nn,它也对应栈中的一个位置,这个位置中保存了一个地址值,这个地址的值为0xabc,即指向变量n的位置。
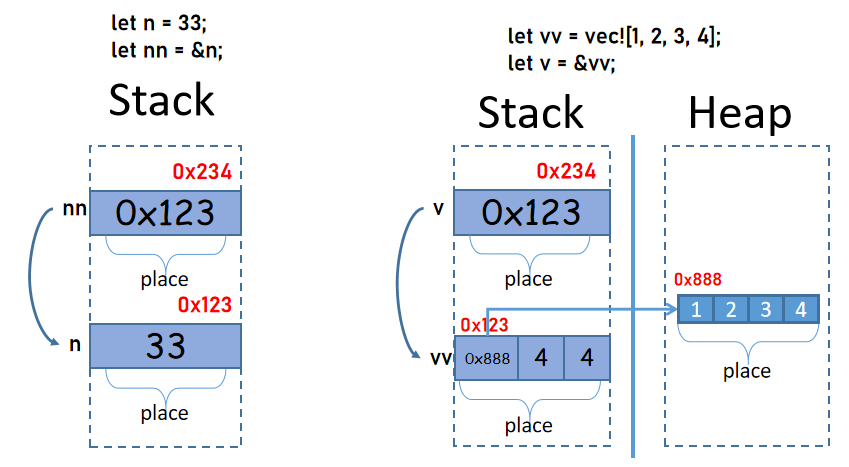
实际上,上面的三种可能中,(1)和(2)没有区别,因为值和位置是绑定的,指向值和指向位置本就是相同的,但是有的地方说是指向值的,理由是不能对未赋值过的的变量进行引用,不能对值被移走的变量进行引用(所以位置和某个值不总是绑定在一起的)。但换一个角度思考,Rust编译器会在建立引用的时候先推断好此刻能否引用,只要能成功建立引用,(1)和(2)就没有区别。
为什么引用中的地址不是指向原始数据呢?例如,对于下面的示例,变量v为什么不是指向堆中的那个位置的?
#![allow(unused)]
fn main() {
let vv = vec![1, 2, 3, 4];
let v = &vv;
}从位置和值的角度来理解。例如上面的let v = &vv;,vv是一个位置,这个位置保存的是Vec的胖指针数据,也就是说,vv的值是这个胖指针而不是堆中的那块实际数据,所以v引用vv时,引用的是vv的位置,而不是实际数据。
此外,Rust的宗旨之一就是保证安全,不允许存在对堆中同一个内存的多个指向,因为这可能会导致重复释放同一块堆内存的危险。换句话说,至始至终,只有最初创建这块堆内存的vv变量才指向堆中这块数据。当然,vv中的值(即栈中位置中保存的值)可能会被移给另外一个变量,那么这个接收变量就会成为唯一一个指向堆中数据的变量。
为什么不允许对堆中同一个内存的多个指向,却允许对栈中同一个数据的多个指向呢?例如,下面的代码中,变量x和变量y中保存的地址都指向变量n的位置:
#![allow(unused)]
fn main() {
let n = 33;
let x = &n;
let y = &n;
}这是因为栈内存由编译器负责维护,编译器知道栈中的某个内存是否安全(比如判断变量是否离开作用域被销毁、判断生命周期),而堆内存是由程序员负责维护,程序员的行为是不安全的。
说了这么多,大概也能体会到一点Rust的行为模式了:尽可能地让涉及到内存安全的概念实现在栈上,尽可能让程序员远离对堆内存的操作。
何时创建位置和值
以下几种常见的情况会产生位置:
- 变量初始化时会产生位置(严格来说,是变量声明后产生位置,但未赋值的变量不能使用,且会被优化掉)
- 调用函数时的参数和返回值会产生位置
- 模式匹配过程中如果使用了变量则也会产生位置
- 引用和解引用也会产生位置
作为总结:
- 会产生变量的时候,就会产生位置
- 需要保存某个值的时候,就会产生位置
- 会产生新值的时候(例如引用会新产生一个地址值,解引用会产生对应的结果值),就会产生位置
- 使用值的时候,就会产生位置
其中有的位置是临时的中间变量,例如引用产生值会先保存在临时变量中。
以上是显式产生位置的方式,还有隐式产生的位置。例如,在初始化一个vec并赋值给变量时,堆内存中的那个位置就是隐式创建的。本文中出现的位置,指的都是栈中的位置,也就是由编译器负责维护的位置,本文完全不考虑堆内存中的位置,因为堆中的位置和我们理解Rust的各种规则没有关系,Rust暴露给程序员的、需要程序员理解的概念,几乎都在栈中。
为什么要理解何时产生位置呢?这涉及到了Move语义和Copy语义。如果不知道何时会产生位置,在对应情况下可能就会不理解为什么会发生移动行为。
例如,match模式匹配时,在分支中使用了变量,可能会发生移动。
#[derive(Debug)]
struct User {
vip: VIP,
}
#[derive(Debug)]
enum VIP {
VIP0,
VIP1,
VIP2,
VIP3,
}
fn main() {
let user = User {vip: VIP::VIP0};
match user.vip {
VIP::VIP0 => println!("not a vip"),
a => println!("vip{:?}", a), // "声明"了变量a,发生move
// ref a => println!(), // 借用而不move
}
println!("{:?}", user); // 报错
}在上面的match匹配代码中,第二个分支使用了变量a,尽管匹配时会匹配第一个分支,但Rust编译器并不知道匹配的结果如何,因此编译器会直接move整个user到这个分支(注:从Rust 2021开始,不会再因为要移动某个内部元素而移动整个容器结构,因此Rust 2021版中,不再move整个user,而是只move单独的user.vip字段)。
位置一旦初始化赋值,就会有一个永远不变的地址,直到销毁。换句话说,变量一旦初始化,无论它之后保存的数据发生了什么变化,它的地址都是固定不变的。也说明了,编译器在编译期间就已经安排好了所有位置的分配。
fn main() {
let mut n = "hello".to_string(); // n是一个栈中的位置,保存了一个胖指针指向堆中数据
println!("n: {:p}", &n); // &n产生一个位置,该位置中保存指向位置n的地址值
let m = n; // 将n中的胖指针移给了m,m保存胖指针指向堆中数据,n变回未初始化状态
println!("m: {:p}", &m); // &m产生一个位置,该位置中保存指向位置m的地址值
n = "world".to_string(); // 重新为n赋值,位置n保存另一个胖指针,但位置n还是那个位置
println!("n: {:p}", &n); // &n产生一个位置,该位置中保存指向位置n的地址值
}输出结果:
n: 0x7ffe71c47d60
m: 0x7ffe71c47dd0
n: 0x7ffe71c47d60
它的内存分布大概如下:

位置和值与Move语义、Copy语义的关联
在Rust中,赋值操作,实际上是一种值的移动:将值从原来的位置移入到目标位置。如果类型实现了Copy trait,则Copy而非Move。
例如:
#![allow(unused)]
fn main() {
let x = 3;
}这个简单的语句实际上会先声明一个变量,刚声明时的变量并未赋值(或者按照某种说法,被初始化为初始值),在某个之后的地方才开始将数值数值3赋值给变量,这里赋值的过程是一个移动操作。
大概过程如下:
#![allow(unused)]
fn main() {
let x i32;
...
x = 3;
}将变量赋值给其它变量,就更容易理解了,要么将源变量位置中的值(注意是位置中的值,不是实际数据)移动到目标位置,要么将位置中的值拷贝到目标位置。
位置的状态标记
比较复杂的是,位置不仅仅只是一个简单的内存位置,它还有各种属性和状态,这些属性和状态都是编译期间由编译器维护的,不会保留到运行期间。
包括且可能不限于如下几种行为:
- 位置具有类型(需注意,Rust中变量有类型,值也有类型)
- 位置保存它的值是否正在被引用以及它是共享引用还是独占引用的标记(borrow operators: The memory location is also placed into a borrowed state for the duration of the reference)
- 还能根据位置的类型是否实现了Copy Trait来决定该位置的值是移走还是拷贝走
更多关于借用和移动语义、拷贝语义,留待后文。
理解Rust的所有权和borrow规则
Rust的所有权系统是保证Rust内存安全最关键的手段之一,例如它使得Rust无需GC也无需手动释放内存。
所有权系统影响整个Rust,它也使得Rust的很多编码方式和其他语言不太一样。因此,需要掌握好Rust的所有权规则,才能写出可运行的、正确的Rust代码,并且越熟悉所有权规则,在编码过程中就越少犯错。
Rust编译器无论在哪方面都是最好且最严格的老师,编译器的borrow checker组件会给出和所有权相关的所有错误。了解所有权规则后,只需跟着编译器的报错,就能知道错在何处,以及如何改正错误。
理解Rust的变量作用域
理解Rust的变量作用域
Rust的所有权系统和作用域息息相关,因此有必要先理解Rust的作用域规则。
在Rust中,任何一个可用来包含代码的大括号都是一个单独的作用域。类似于Struct{}这样用来定义数据类型的大括号,不在该讨论范围之内,本文后面所说的大括号也都不考虑这种大括号。
包括且不限于以下几种结构中的大括号都有自己的作用域:
- if、while等流程控制语句中的大括号
- match模式匹配的大括号
- 单独的大括号
- 函数定义的大括号
- mod定义模块的大括号
例如,可以单独使用一个大括号来开启一个作用域:
#![allow(unused)]
fn main() {
{ // s 在这里无效, 它尚未声明
let s = "hello"; // 从此处起,s是有效的
println!("{}", s); // 使用 s
} // 此作用域已结束,s不再有效
}上面的代码中,变量s绑定了字符串字面值,在跳出作用域后,变量s失效,变量s所绑定的值会自动被销毁。
注:上文【变量s绑定的值会被销毁】的说法是错误的
实际上,变量跳出作用域失效时,会自动调用Drop Trait的drop函数来销毁该变量绑定在内存中的数据,这里特指销毁堆和栈上的数据,而字符串字面量是存放在全局内存中的,它会在程序启动到程序终止期间一直存在,不会被销毁。可通过如下代码验证:
fn main(){ { let s = "hello"; println!("{:p}", s); // 0x7ff6ce0cd3f8 } let s = "hello"; println!("{:p}", s); // 0x7ff6ce0cd3f8 }因此,上面的示例中只是让变量s失效了,仅此而已,并没有销毁s所绑定的字符串字面量。
但一般情况下不考虑这些细节,而是照常描述为【跳出作用域时,会自动销毁变量所绑定的值】。
任意大括号之间都可以嵌套。例如可以在函数定义的内部再定义函数,在函数内部使用单独的大括号,在函数内部使用mod定义模块,等等。
fn main(){
fn ff(){
println!("hello world");
}
ff();
let mut a = 33;
{
a += 1;
}
println!("{}", a); // 34
}虽然任何一种大括号都有自己的作用域,但函数作用域比较特别。函数作用域内,无法访问函数外部的变量,而其他大括号的作用域,可以访问大括号外部的变量。
fn main() {
let x = 32;
fn f(){
// 编译错误,不能访问函数外面的变量x和y
// println!("{}, {}", x, y);
}
let y = 33;
f();
let mut a = 33;
{
// 可以访问大括号外面的变量a
a += 1;
}
println!("{}", a);
}在Rust中,能否访问外部变量称为【捕获环境】。比如函数是不能捕获环境的,而大括号可以捕获环境。
对于可捕获环境的大括号作用域,要注意Rust的变量遮盖行为。
分析下面的代码:
fn main(){
let mut a = 33;
{
a += 1; // 访问并修改的是外部变量a的值
// 又声明变量a,这会发生变量遮盖现象
// 从此开始,大括号内访问的变量a都是该变量
let mut a = 44;
a += 2;
println!("{}", a); // 输出46
} // 大括号内声明的变量a失效
println!("{}", a); // 输出34
}这种行为和其他语言不太一样,因此这种行为需要引起注意。
悬垂引用
在支持指针操作的语言中,一不小心就会因为释放内存而导致指向该数据的指针变成悬垂指针(dangling pointer)。
Rust的编译器保证永远不会出现悬垂引用:引用必须总是有效。即引用必须在数据被销毁之前先失效,而不能销毁数据后仍继续持有该数据的引用。
例如,下面的代码不会通过编译:
fn main(){
let sf = f(); // f()返回值是一个无效引用
}
fn f() -> &String {
let s = String::from("hello");
&s // 返回s的引用
} // s跳出作用域,堆中String字符串被释放该示例报错的原因很明显,函数的返回值&s是一个指向堆中字符串数据的引用(注意,引用是一个实实在在的数据),当函数结束后,s跳出作用域,其保存的字符串数据被销毁,这使得返回值&s变成了一个无效的引用。
这里的悬垂指针非常明显,但很多时候会在非常隐晦的情况下导致悬垂指针,幸好Rust保证了绝不出现悬垂指针的问题。
Rust所有权规则概述
Rust所有权规则概述
Rust的所有权(ownership)规则贯穿整个语言,几乎每行代码都涉及到所有权规则,因此需要对所有权规则非常熟悉才能更好地使用Rust。
Rust所有权规则可以总结为如下几句话:
- Rust中的每个值都有一个被称为其所有者的变量(即:值的所有者是某个变量)
- 值在任一时刻有且只有一个所有者
- 当所有者(变量)离开作用域,这个值将被销毁
这里对第三点做一些补充性的解释,所有者离开作用域会导致值被销毁,这个过程实际上是调用一个名为drop的函数来销毁数据释放内存。在前文解释作用域规则时曾提到过,销毁的数据特指堆栈中的数据,如果变量绑定的值是全局内存区内的数据,则数据不会被销毁。
例如:
fn main(){
{
let mut s = String::from("hello");
} // 跳出作用域,栈中的变量s将被销毁,其指向的堆
// 中数据也被销毁,但全局内存区的字符串字面量仍被保留
}谁是谁的所有者
Rust中每个值都有一个所有者,但这个说法比较容易产生误会。
例如:
#![allow(unused)]
fn main() {
let s = String::from("hello");
}多数人可能会误以为变量s是堆中字符串数据hello的所有者,但实际上不是。
前面介绍内存的文章中解释过,String字符串的实际数据在堆中,但是String大小不确定,所以在栈中使用一个胖指针结构来表示这个String类型的数据,这个胖指针中的指针指向堆中的String实际数据。也就是说,变量s的值是那个胖指针,而不是堆中的实际数据。
因此,变量s是那个胖指针的所有者,而不是堆中实际数据的所有者。
但是,由于胖指针是指向堆中数据的,多数时候为了简化理解简化描述方式,也经常会说s是那个堆中实际数据的所有者。但无论如何描述,需要理解所有者和值之间的真相。
Rust中数据的移动
在其他语言中,有深拷贝和浅拷贝的概念,浅拷贝描述的是只拷贝数据对象的引用,深拷贝描述的是根据引用递归到最终的数据并拷贝数据。
在Rust中没有深浅拷贝的概念,但有移动(move)、拷贝(copy)和克隆(clone)的概念。
看下面的赋值操作,在其他语言中这样赋值是正确的,但在Rust中这样的赋值会报错。
fn main(){
let s1 = String::from("hello");
let s2 = s1;
// 将报错error: borrow of moved value: `s1`
println!("{},{}", s1, s2);
}上面的示例中,变量s1绑定了String字符串数据(再次提醒,String数据是胖指针结构而不是指堆中的那些实际数据),此时该数据的所有者是s1。
当执行let s2 = s1;时,将不会拷贝堆中数据赋值给s2,也不会像其他语言一样让变量s2也绑定堆中数据(即,不会拷贝堆数据的引用赋值给s2)。
因此,下图的内存引用方式不适用于Rust。

如果Rust采用这种内存引用方式,按照Rust的所有权规则,变量在跳出作用域后就销毁堆中对应数据,那么在s1和s2离开作用域时会导致二次释放同一段堆内存,这会导致内存污染。
Rust采用非常直接的方式,当执行let s2 = s1;时,直接让s1无效(s1仍然存在,只是变成未初始化变量,Rust不允许使用未初始化变量,可重新为其赋值),而是只让s2绑定堆内存的数据。也就是将s1移动到s2,也称为值的所有权从s1移给s2。
如图:
所有权移动后修改数据
定义变量的时候,加上mut表示变量可修改。当发生所有权转移时,后拥有所有权的变量也可以加上mut。
#![allow(unused)]
fn main() {
let mut x = String::from("hello");
// x将所有权转移给y,但y无法修改字符串
let y = x;
// y.push('C'); // 本行报错
let a = String::from("hello");
// 虽然a无法修改字符串,但转移所有权后,b可修改字符串
let mut b = a;
b.push('C'); // 本行不报错
}移动真的只是移动吗?
比如下面的示例:
#![allow(unused)]
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}上面已经分析过,值的所有权会从变量s1转移到变量s2,所有权的转移,涉及到的过程是拷贝到目标变量,同时重置原变量到未初始状态,整个过程就像是进行了一次数据的移动。但注意,上面示例中拷贝的是栈中的胖指针,而不是拷贝堆中的实际数据,因此这样的拷贝效率是相对较高的。
所有权转移之后,将只有新的所有者才会指向堆中的实际数据,而原变量将不再指向堆中实际数据,因此所有权转移之后仍然只有一个指针指向堆中数据。
Move不仅发生在变量赋值过程中,在函数传参、函数返回数据时也会Move,因此,如果将一个大对象(例如包含很多数据的数组,包含很多字段的struct)作为参数传递给函数,是否会让效率很低下?
按照上面的结论来说,确实如此。但Rust编译器会对Move语义的行为做出一些优化,简单来说,当数据量较大且不会引起程序正确性问题时,它会传递大对象的指针而非内存拷贝。
此外,对于胖指针类型的变量(如Vec、String),即使发生了拷贝,其性能也不差,因为拷贝的只是它的胖指针部分。
总之,Move虽然发生了内存拷贝,但它的性能并不会太受影响。
此处部分结论参考:https://stackoverflow.com/questions/30288782/what-are-move-semantics-in-rust。
Copy语义
默认情况下,在将一个值保存到某个位置时总是进行值的移动(实际上是拷贝),使得只有目标位置才拥有这个值,而原始变量将变回未初始化状态,也就是暂时不可用的状态。这是Rust的移动语义。
Rust还有Copy语义,和Move语义几乎相同,唯一的区别是Copy后,原始变量仍然可用。
前面说过,Move实际上是进行了拷贝,只不过拷贝后让原始变量变回未初始化状态了,而Copy的行为,就是保留原始变量。
但Rust默认是使用Move语义,如果想要使用Copy语义,要求要拷贝的数据类型实现了Copy Trait。
例如,i32默认就已经实现了Copy Trait,因此它在进行所有权转移的时候,会自动使用Copy语义,而不是Move语义。
#![allow(unused)]
fn main() {
let x = 3; // 3是原始数据类型,它直接存储在栈中,所以x变量的值是3,x拥有3
let n = x; // Copy x的值(即3)到变量n,n现在拥有一个3,但x仍然拥有自己的3
}Rust中默认实现了Copy Trait的类型,包括但不限于:
- 所有整数类型,比如u32
- 所有浮点数类型,比如f64
- 布尔类型,bool,它的值是true和false
- 字符类型,char
- 元组,当且仅当其包含的类型也都是Copy的时候。比如
(i32, i32)是Copy的,但(i32, String)不是 - 共享指针类型或共享引用类型
对于那些没有实现Copy的自定义类型,可以手动去实现Copy(要求同时实现Clone),方式很简单:
#![allow(unused)]
fn main() {
#[derive(Copy, Clone)]
struct Abc(i32, i32);
}下面是实现了Copy和未实现Copy时的一个对比示例:
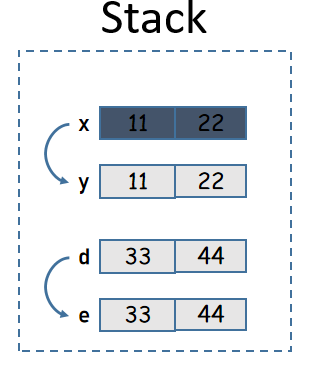
#[derive(Debug)]
struct Xyz(i32, i32);
#[derive(Copy, Clone, Debug)]
struct Def(i32, i32);
fn main() {
let x = Xyz(11, 22);
let y = x;
// println!("x: {}", x); // 报错
println!("y: {:?}", y);
let d = Def(33, 44);
let e = d;
println!("d: {:?}", d);
println!("e: {:?}", e);
}
克隆数据
虽然实现Copy Trait可以让原变量继续拥有自己的值,但在某些需求下,不便甚至不能去实现Copy。这时如果想要继续使用原变量,可以使用clone()方法手动拷贝变量的数据,同时不会让原始变量变回未初始化状态。
fn main(){
let s1 = String::from("hello");
// 克隆s1,克隆之后,变量s1仍然绑定原始数据
let s2 = s1.clone();
println!("{},{}", s1, s2);
}但不是所有数据类型都可以进行克隆,只有那些实现了Clone Trait的类型才可以进行克隆(Trait类似于面向对象语言中的接口,如果不了解可先不管Trait是什么),常见的数据类型都已经实现了Clone,因此它们可以直接使用clone()来克隆。
对于那些没有实现Clone Trait的自定义类型,需要手动实现Clone Trait。在自定义类型之前加上#[derive(Clone)]即可。例如:
#![allow(unused)]
fn main() {
#[derive(Clone)]
struct Abc(i32, i32);
}这样Abc类型的值就可以使用clone()方法进行克隆。
要注意Copy和Clone时的区别,如果不考虑自己实现Copy trait和Clone trait,而是使用它们的默认实现,那么:
- Copy时,只拷贝变量本身的值,如果这个变量指向了其它数据,则不会拷贝其指向的数据
- Clone时,拷贝变量本身的值,如果这个变量指向了其它数据,则也会拷贝其指向的数据
也就是说,Copy是浅拷贝,Clone是深拷贝,Rust会对每个字段每个元素递归调用clone(),直到最底部。
例如:
fn main() {
let vb0 = vec!["s1".to_string()];
let v = vec![vb0];
println!("{:p}", &v[0][0]); // 0x21c43a20c50
let vc = v.clone();
println!("{:p}", &vc[0][0]); // 0x21c43a20b70
}所以,使用Clone的默认实现时,clone()操作的性能是较低的。但可以自己实现自己的克隆逻辑,也不一定总是会效率低。比如Rc,它的clone用于增加引用计数,同时只拷贝少量数据,它的clone效率并不低。
函数参数和返回值的所有权移动
函数参数类似于变量赋值,在调用函数时,会将所有权移动给函数参数。
函数返回时,返回值的所有权从函数内移动到函数外变量。
例如:
fn main(){
let s1 = String::from("hello");
// 所有权从s1移动到f1的参数
// 然后f1返回值的所有权移动给s2
let s2 = f1(s1);
// 注意,println!()不会转移参数s2的所有权
println!("{}", s2);
let x = 4;
f2(x); // 没有移动所有权,而是拷贝一份给f2参数
} // 首先x跳出作用域,
// 然后s2跳出作用域,并释放对应堆内存数据,
// 最后s1跳出作用域,s1没有所有权,所以没有任何其他影响
fn f1(s: String) -> String {
let ss = String::from("world");
println!("{},{}", s,ss);
s // 返回值s的所有权移动到函数外
} // ss跳出作用域
fn f2(i: i32){
println!("{}",i);
} // i跳出作用域很多时候,变量传参之后丢失所有权是非常不方便的,这意味着函数调用之后,原变量就不可用了。为了解决这个问题,可以将变量的引用传递给参数。引用是保存在栈中的,它实现了Copy Trait,因此在传递引用时,所有权转移的过程实际上是拷贝了引用,这样不会丢失原变量的所有权,效率也更高。
引用和所有权借用
引用和所有权借用
所有权不仅可以转移(原变量会丢失数据的所有权),还可以通过引用的方式来借用数据的所有权(borrow ownership)。
使用引用借用变量所有权时,【借完】之后会自动交还所有权,从而使得原变量不丢失所有权。至于什么时候【借完】,尚无法在此深究。
例如:
fn main(){
{
let s = String::from("hello");
let sf1 = &s; // 借用
let sf2 = &s; // 再次借用
println!("{}, {}, {}",s, sf1, sf2);
} // sf2离开,sf1离开,s离开
}注意,&s表示创建变量s的引用,为某个变量创建引用的过程不会转移该变量所拥有的所有权。
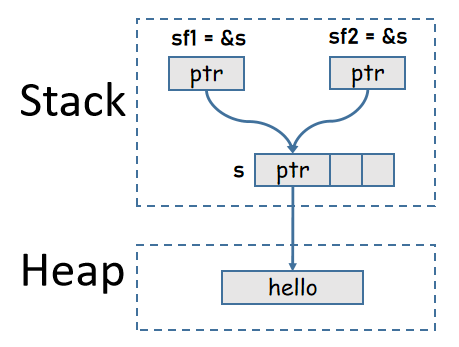
(不可变)引用实现了Copy Trait,因此下面的代码是等价的:
#![allow(unused)]
fn main() {
// 多次创建s的引用,并将它们赋值给不同变量
let sf1 = &s;
let sf2 = &s;
// 拷贝sf1,使得sf2也引用s,
// 但sf1是引用,是可Copy的,因此sf1仍然有效,即仍然指向数据
let sf1 = &s;
let sf2 = sf1;
}还可以将变量的引用传递给函数的参数,从而保证在调用函数时变量不会丢失所有权。
fn main(){
let s = String::from("hello");
let s1 = s.clone();
// s1丢失所有权,s1将回到未初始化状态
f1(s1);
// println!("{}", s1);
// 传递s的引用,借用s所有权
let l = f2(&s);
// 交还所有权
// s仍然可用
println!("{} size: {}", s, l);
}
fn f1(s: String){
println!("{}", s);
}
fn f2(s: &String)->usize{
s.len() // len()返回值类型是usize
}可变引用和不可变引用的所有权规则
变量的引用分为可变引用&mut var和不可变引用&var,站在所有权借用的角度来看,可变引用表示的是可变借用,不可变引用表示的是不可变借用。
- 不可变借用:借用只读权,不允许修改其引用的数据
- 可变引用:借用可写权(包括可读权),允许修改其引用的数据
- 多个不可变引用可共存(可同时读)
- 可变引用具有排他性,在有可变引用时,不允许存在该数据的其他可变和不可变引用
- 这样的说法不准确,短短几句话也无法描述清楚,因此留在后面再详细解释
前面示例中f2(&s)传递的是变量s的不可变引用&s,即借用了数据的只读权,因此无法在函数内部修改其引用的数据值。
如要使用可变引用去修改数据值,要求:
- var的变量可变,即
let mut var = xxx - var的引用可变,即
let varf = &mut var
例如:
fn main(){
let mut x = String::from("junmajinlong");
let x_ref = &mut x; // 借用s的可写权
x_ref.push_str(".com");
println!("{}", x);
let mut s = String::from("hello");
f1(&mut s); // 借用s的可写权
println!("{}", s);
}
fn f1(s: &mut String){
s.push_str("world");
}容器集合类型的所有权规则
前面所介绍的都是标量类型的所有权规则,此处再简单解释一下容器类型(比如tuple/array/vec/struct/enum等)的所有权。
容器类型中可能包含栈中数据值(特指实现了Copy的类型),也可能包含堆中数据值(特指未实现Copy的类型)。例如:
#![allow(unused)]
fn main() {
let tup = (5, String::from("hello"));
}容器变量拥有容器中所有元素值的所有权。
因此,当上面tup的第二个元素的所有权转移之后,tup将不再拥有它的所有权,这个元素将不可使用,tup自身也不可使用,但仍然可以使用tup的第一个元素。
#![allow(unused)]
fn main() {
let tup = (5, String::from("hello"));
// 5拷贝后赋值给x,tup仍有该元素的所有权
// 字符串所有权转移给y,tup丢失该元素所有权
let (x, y) = tup;
println!("{},{}", x, y); // 正确
println!("{}", tup.0); // 正确
println!("{}", tup.1); // 错误
println!("{:?}", tup); // 错误
}如果想要让原始容器变量继续可用,要么忽略那些没有实现Copy的堆中数据,要么clone()拷贝堆中数据后再borrow,又或者可以引用该元素。
#![allow(unused)]
fn main() {
// 方式一:忽略
let (x, _) = tup;
println!("{}", tup.1); // 正确
// 方式二:clone
let (x, y) = tup.clone();
println!("{}", tup.1); // 正确
// 方式三:引用
let (x, ref y) = tup;
println!("{}", tup.1); // 正确
}理解可变引用的排他性
理解可变引用的排他性
本节内容完全属于我个人推理,完全用我个人的理解来解释结论,我不知道官方有没有相关的术语,如果有,盼请告知。另外,如果结论错误,也盼请指正。
不可变引用可以共存,表示允许同时有多个不可变引用来访问数据,这不难理解。
fn main(){
let x = String::from("junmajinlong");
let _x1 = &x;
let _x2 = &x;
let _x3 = &x;
}可变引用具有排他性,某数据在某一时刻只允许有一个可变引用,此时不允许有其他任何引用。这看上去似乎这也不难理解。
例如,下面的代码会报错:cannot borrow x as mutable more than once at a time。
#![allow(unused)]
fn main() {
let mut x = String::from("junmajinlong");
let x_mut1 = &mut x; // (1)
let x_mut2 = &mut x; // (2)
println!("{}", x_mut1); // (3)
println!("{}", x_mut2); // (4)
}多数Rust书籍都只是像上面示例一样对【可变引用具有排他性】的结论粗浅地验证一遍。
但真相比这要复杂一点。比如,去掉上面的代码(3)或者同时去掉代码(3)和(4),又或者将代码(3)移到代码(2)之前,得到的代码都是可以正确执行的代码:
#![allow(unused)]
fn main() {
// 可以正确执行
let mut x = String::from("junmajinlong");
let x_mut1 = &mut x;
let x_mut2 = &mut x;
println!("{}", x_mut2);
// 也可以正确执行
let mut x = String::from("junmajinlong");
let x_mut1 = &mut x;
let x_mut2 = &mut x;
// 也可以正确执行
let mut x = String::from("junmajinlong");
let x_mut1 = &mut x;
println!("{}", x_mut1);
let x_mut2 = &mut x;
println!("{}", x_mut2);
}从上面的测试来看,同一份数据的多个可变引用是可以共存的。可见,可变引用具有排他性的【排他性】,其含义体现在更深层次。
可以将可变引用看作是一把独占锁。在当前作用域内,从第一次使用可变引用开始创建这把独占锁,之后无论使用原始变量(即所有权拥有者)、可变引用还是不可变引用都会抢占这把独占锁,以保证只有一方可以访问数据,每次抢得独占锁后,都会将之前所有引用变量给锁住,使它们变成不可用状态。当离开当前作用域时,当前作用域内的所有独占锁都被释放。
因此,可变引用是抢占且排他的,将其称为抢占式独占锁更为合适。
换个角度来理解,自从第一次使用可变引用导致独占锁出现后,可以随时使用原始变量、可变引用或不可变引用来抢独占锁,但抢锁后以前的引用变量就不能再用,且当前持有的锁也可以随时被抢走。一切都由程序员控制,程序员可以在任意代码位置通过原始变量或引用来抢锁。
下面通过示例来分析上述规则。
fn main(){
let mut a = String::from("junmajinlong");
// 创建两个不可变引用,不可变引用可以共存
// 此时还没有独占锁
let a_non_ref1 = &a;
let a_non_ref2 = &a;
// 可直接使用不可变引用
println!("{}", a_non_ref1);
println!("{}", a_non_ref2);
// 第一次使用可变引用,将出现独占锁,a_ref1拥有独占锁
let a_ref1 = &mut a;
// 抢占独占锁后,前面两个不可变引用变量将不能使用
// 因此下面两行代码报错
// println!("{}", a_non_ref1);
// println!("{}", a_non_ref2);
// 再次使用不可变引用,a_non_ref3将获得独占锁
let a_non_ref3 = &a;
// 抢占独占锁后,前面所有引用变量都不能使用
// 因此下面代码会报错
// println!("{}", a_ref1);
// println!("{}", a_non_ref1);
// 再次使用可变引用,a_ref2将获得独占锁
// 抢占后前面所有该数据的引用都不可用
let a_ref2 = &mut a;
// 但a_ref2是可用的
println!("{}", a_ref2);
// 这里println!中使用的是a的不可变引用&a,
// 但不可变引用也会抢占独占锁,前面所有引用变量将不能使用
println!("{}", a);
// 因此下面的代码会报错
// println!("{}", a_ref2);
// 任何时候使用原始变量a,也会抢占独占锁
a = String::from("junmajinlong");
}理解上面的分析后,再分析代码是否错误以及为什么将非常轻松。
例如,下面第一段代码为什么不报错,而第二段代码是错误的:
fn main(){
let mut x = String::from("junmajinlong");
// (1).下面这段代码是正确的
let x1 = &mut x; // 独占锁出现,x1拥有独占锁
println!("{}", x1); // x1是可用的变量
let x2 = &mut x; // x2抢占独占锁,x1不可用
println!("{}", x2); // x2是可用的变量
// (2).下面这段代码是错误的
let x3 = &mut x; // x3抢占独占锁
ff(&x); // &x抢占独占锁,参数s获得锁,使得x3不可用
println!("{}", x3); // 使用了x3,导致报错,注释本行将正确
}
fn ff(s: &String){
println!("{}", s);
}下面这段代码比较难理解:
fn main() {
let mut x = Box::new(42); // 1
// 创建x的不可变引用
let mut z = &x; // 2
// 在考虑引用检查问题和生命周期问题时,循环结构for {} 和多个独立的大括号 {} 是等价的
for i in 0..100 {
// 使用z的不可变引用
println!("{}", z); // 3
// 抢占x的独占锁,使得z不再可用
// 第一轮循环时创建x的独占锁
x = Box::new(i); // 4
// 因此下面的代码会报错
// println!("{}", z);
// 虽然z不可用,但z自身可以被重新赋值,重新赋值将丢弃z之前对x的引用,
// 注意这里使用了x的不可变引用,它会抢占x的独占锁,
// 虽然这里z重新引用了x,但和赋值之前引用的x已经不一样,它是一个新的引用,
// 并且z在这里抢占到了新的x独占锁,而赋值之前的x独占锁已经被代码行4抢占
z = &x; // 5
}
}如果注释上面的代码行5:z = &x,编译器将报错,如此修改后,上面的循环等价于:
fn main() {
let mut x = Box::new(42); // 1
let mut z = &x; // 2
{
println!("{}", z); // 3
x = Box::new(0); // 4 创建x的独占锁,z不再可用
}
{
println!("{}", z); // 代码行4抢占独占锁,z不再可用,报错
x = Box::new(1);
}
...
}再看下面这段代码:
fn main(){
let mut x = 33;
let y = &mut x; // y获得独占锁
x = *y + 1; // 使用y获取数据后,x重新抢得独占锁
// 赋值之后,x有效,y将失效
println!("{}", x); // 正确
// println!("{}", y); // 错误
}如果从位置表达式和值的角度来理解引用,会更直观更容易理解。在通过位置和值理解内存模型中说过,位置具有一些状态标记,其中之一就是该位置当前是否正在被引用以及如何被引用的状态标记。
对某个位置每建立一次引用就记录一次,如果是建立共享引用,则简单判断即可,但对该位置进行可变引用之后,从此刻开始的任意时刻,这个位置将只能存在单一使用者,使用者可以是原始变量,可以是新的可变引用或不可变引用,使用者可以随时更换,但保证任意时刻只能有一个使用者。
再次理解Move
再次理解Move
前面对Move、Copy和所有权相关的内容做了详细的解释,相信变量赋值、函数传参时的所有权问题应该不再难理解。
但是,所有权的转移并不仅仅只发生在这两种相对比较明显的情况下。例如,解引用操作也需要转移所有权。
#![allow(unused)]
fn main() {
let v = &vec![11, 22];
let vv = *v;
}上面会报错:
error[E0507]: cannot move out of `*v` which is behind a shared reference
从位置表达式和值的角度来思考也不难理解:当产生了一个位置,且需要向位置中放入值,就会发生移动(Moved and copied types)。只不过,这个值可能来自某个变量,可能来自计算结果(即来自于中间产生的临时变量),这个值的类型可能实现了Copy Trait。
对于上面的示例来说,&vec![11, 22]中间产生了好几个临时变量,但最终有一个临时变量是vec的所有者,然后对这个变量进行引用,将引用赋值给变量v。使用*v解引用时,也产生了一个临时变量保存解引用得到的值,而这里就出现了问题。因为变量v只是vec的一个引用,而不是它的所有者,它无权转移值的所有权。
下面几个示例,将不难理解:
#![allow(unused)]
fn main() {
let a = &"junmajinlong.com".to_string();
// let b = *a; // (1).取消注释将报错
let c = (*a).clone(); // (2).正确
let d = &*a; // (3).正确
let x = &3;
let y = *x; // (4).正确
}注意,不要使用println!("{}", *a);或类似的宏来测试,这些宏不是函数,它们真实的代码中使用的是&(*a),因此不会发生所有权的转移。
虽说【当产生了一个位置,且需要向位置中放入值,就会发生移动】这句话很容易理解,但有时候很难发现深层次的移动行为。
被丢弃的move
下面是一个容易令人疑惑的示例:
fn main(){
let x = "hello".to_string();
x; // 发生Move
println!("{}", x); // 报错:value borrowed here after move
}从这个示例来看,【当值需要放进位置的时候,就会发生移动】,这句话似乎不总是正确,第三行的x;取得了x的值,但是它直接被丢弃了,所以x也被消耗掉了,使得println中使用x报错。实际上,这里也产生了位置,它等价于let _tmp = x;,即将值移动给了一个临时变量。
如果上面的示例不好理解,那下面有时候会排上用场的示例,会有助于理解:
fn main() {
let x = "hello".to_string();
let y = {
x // 发生Move,注意没有结尾分号
};
println!("{}", x); // 报错:value borrowed here after move
}从结果上来看,语句块将x通过返回值的方式移出来赋值给了y,所以认为x的所有权被转移给了y。实际上,语句块中那唯一的一行代码本身就发生了一次移动,将x的所有权移动给了临时变量,然后返回时又发生了一次移动。
什么时候Move:使用值的时候
上面的结论说明了一个问题:虽然多数时候产生位置的行为是比较明确的,但少数时候却非常难发现,也难以理解。
可以换个角度来看待:当使用值的时候,就会产生位置,就会发生移动。
如果翻阅Rust Reference文档,就会经常性地看到类似这样的说法(例如Negation operators):
xxx are evaluated in value expression context so are moved or copied.
这里需要明确:value expression表示的是会产生值的表达式,value expression context表示的是使用值的上下文。
有哪些地方会使用值呢?除了比较明显的会移动的情况,还有一些隐式的移动(或Copy):
- 方法调用的真实接收者,如
a.meth(),a会被移动(注意,a可能会被自动加减引用,此时a不是方法的真实接收者) - 解引用时会Move(注意,解引用会得到那个值,但不一定会消耗这个值,有可能只是借助这个值去访问它的某个字段、或创建这个值的引用,这些操作可以看作是借值而不是使用值)
- 字段访问时会Move那个字段
- 索引访问时,会Move那个元素
- 大小比较时,会Move(注意,
a > b比较时会先自动取a和b的引用,然后再增减a和b的引用直到两边类型相同,因此实际上Move(Copy)的是它们的某个引用,而不会Move变量本身)
更完整更细致的描述,参考Expression - Rust Reference。
下面是几个比较常见的容易疑惑的移动示例:
#![allow(unused)]
fn main() {
struct User {name: String}
let user = User {name: "junmajinlong".to_string()};
let name = (&user).name; // 报错,想要移动name字段,但user正被引用着,此刻不允许移走它的一部分
let user1 = *(&user); // 报错,解引用临时变量时触发移动,此时user正被引用着
let u = &user;
let user2 = &(*u); // 不报错,解引用得到值后,对这个值创建引用,不会消耗值
impl User {
fn func(&self) {
let xx = *self; // 报错,解引用报错,self自身不是所有者,例如user.func()时,user才是所有者
if (*self).name < "hello".to_string(){} // 不报错,比较时会转换为&((*self).name) < &("hello".to_string())
}
}
}引用类型的Copy和Clone
引用类型的Copy和Clone
引用类型是可Copy的,所以引用类型在Move的时候都会Copy一个引用的副本,Copy前后的引用都指向同一个目标值,这很容易理解。
#![allow(unused)]
fn main() {
let a = "hello world".to_string();
// b和c都是a的引用
let b = &a;
let c = b; // Copy引用
}引用类型也是可Clone的(实现Copy的时候要求也必须实现Clone,所以可Copy的类型也是可Clone的),但是引用类型的clone()需注意。
例如:
#![allow(unused)]
fn main() {
struct Person;
let a = Person;
let b = &a;
let c = b.clone(); // c的类型是&Person
}如果使用了clippy工具检查代码,clippy将对上面的b.clone()给出错误提示:
using `clone` on a double-reference; this will copy the reference of type `&strategy::Strategy::run::Person` instead of cloning the inner type
提示说明,对引用clone()时,将拷贝引用类型本身,而不是去拷贝引用所指向的数据本身,所以变量c的类型是&Person。这里引用的clone()逻辑,看上去似乎没有问题,但是却发出了错误提示。
但如果,在引用所指向的类型上去实现Clone,再去clone()引用类型,将没有错误提示。
#![allow(unused)]
fn main() {
#[derive(Clone)]
struct Person;
let a = Person;
let b = &a;
let c = b.clone(); // c的类型是Person,而不是&Person
}注意上面b.clone()得到的类型是引用所指向数据的类型,即Person,而不是像之前示例中的那样得到&Person。
前后两个示例的区别,仅在于引用所指向的类型Person有没有实现Clone。所以得到结论:
- 没有实现Clone时,引用类型的clone()将等价于Copy,但cilppy工具的错误提示说明这很可能不是我们想要的克隆效果
- 实现了Clone时,引用类型的clone()将克隆并得到引用所指向的类型
同一种类型的同一个方法,调用时却产生两种效果,之所以会有这样的区别,是因为:
- 方法调用的符号
.会自动解引用 - 方法调用前会先查找方法,查找方法时有优先级,找得到即停。由于解引用的前和后是两种类型(解引用前是引用类型,解引用后是引用指向的类型),如果这两种类型都实现了同一个方法(比如
clone()),Rust编译器将按照方法查找规则来决定调用哪个类型上的方法,参考(https://rustc-dev-guide.rust-lang.org/method-lookup.html?highlight=lookup#method-lookup)
为什么clone引用的时候,clippy工具会提示这很可能不是我们想要的行为呢?一方面,拷贝一个引用得到另一个引用副本是很常见的需求,但是这个需求有Copy就够了,另一方面,正如clippy所提示的,能够拷贝引用背后的数据也是非常有必要的。
例如,某方法要求返回Person类型,但在该方法内部却只能取得Person的引用类型(比如从HashMap的get()方法只能返回值的引用),所以需要将引用&Person转换为Person,直接解引用是一种可行方案,但是对未实现Copy的类型去解引用,将会执行Move操作,很多时候这是不允许的,比如不允许将已经存入HashMap中的值Move出来,此时最简单的方式,就是通过克隆引用的方式得到Person类型。
提醒:正因为从集合(比如HashMap、BTreeMap等)中取数据后很有可能需要对取得的数据进行克隆,因此建议不要将大体量的数据存入集合,如果确实需要克隆集合中的数据的话,这将会严重影响性能。
作为建议,可以考虑先将大体量的数据封装在智能指针(比如Box、Rc等)的背后,再将智能指针存入集合。
其它语言中集合类型的使用可能非常简单直接,但Rust中需要去关注这一点。
Vec类型
Rust中数组的长度不可变,这是很受限制的。
Rust在标准库中提供了Vector类型(向量)。Vec类型和数组类型的区别在于前者的长度动态可变。
Vec的数据类型描述方式为Vec<T>,其中T代表vec中所存放元素的类型。例如,存放i32类型的vec,它的数据类型为Vec<i32>。
Vec的基本使用
vec的基本使用
创建向量有几种方式:
Vec::new()创建空的vecVec::with_capacity()创建空的vec,并将其容量设置为指定的数量vec![]宏创建并初始化vec(中括号可以换为小括号或大括号)vec![v;n]创建并初始化vec,共n个元素,每个元素都初始化为v
fn main(){
let mut v1 = Vec::new();
// 追加元素时,将根据所追加的元素推导v1的数据类型Vec<i32>
v1.push(1); // push()向vec尾部追加元素
v1.push(2);
v1.push(3);
v1.push(4);
assert_eq!(v1, [1,2,3,4]) // vec可以直接和数组进行比较
// v2的类型推导为:Vec<i32>
let v2 = vec![1,2,3,4];
assert_eq!(v2, [1,2,3,4]);
let v3 = vec!(3;4); // 等价于vec![3,3,3,3]
assert_eq!(v3, [3,3,3,3]);
// 创建容量为10的空vec
let mut v4 = Vec::with_capacity(10);
v4.push(33);
}访问和遍历vec
可以使用索引来访问vec中的元素。索引越界访问时,将在运行时panic报错。
索引是usize类型的值,因此不接受负数索引。
fn main(){
let v = vec![11,22,33,44];
let n: usize = 3;
println!("{},{}", v[0], v[n]);
// 越界,报错
// 运行错误而非编译错误,因为运行期间才知道vec长度
// println!("{}", v[9]);
}如果不想要在越界访问vec时panic中断程序,可使用:
get()来获取指定索引处的元素引用或范围内元素的引用,如果索引越界,返回None。get_mut()来获取元素的可变引用或范围内元素的可变引用,如果索引越界,返回None。
这两个方法的返回值可能是所取元素的引用,也可能是None,此处不对None展开介绍,相关的细节要留到Option类型中介绍。这里只需要知道,当所调用函数的返回值可能是一个具体值,也可能是None时,需要对这两种可能的返回值进行处理。比较简单的一种处理方式是在该函数返回结果上使用unwrap()方法:当成功返回具体值时,unwrap()将返回该值,当返回None时, unwrap()将panic报错退出。
例如:
fn main(){
let v = [11,22,33,44];
// 取得index=3处元素,成功,于是unwrap()提取得到44
let n = v.get(3).unwrap();
println!("{}", n);
// 取得index=4处元素,失败,于是panic报错
// let nn = v.get(4).unwrap();
}另外,Vec是可迭代的,可以直接使用for x in vec {}来遍历vec。
#![allow(unused)]
fn main() {
let v = vec![11,22,33,44];
for i in v {
println!("{}", i);
}
}Vec的内存布局
Vec的内存布局
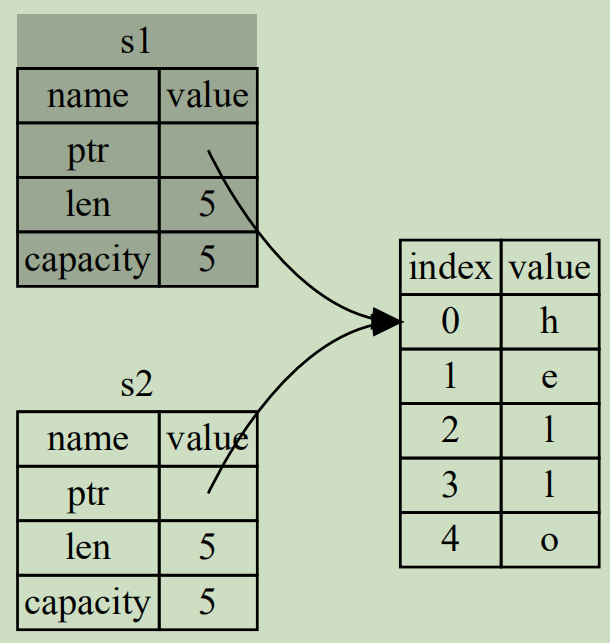
Vec所存储的数据部分在堆内存中,同时在栈空间中存放了该vec的胖指针。胖指针包括三部分元数据:
- 指向堆的指针(一个机器字长)
- 当前vec元素数量(即长度,usize,一个机器字长)
- vec的容量(即当前vec最多可存放多少元素,usize,一个机器字长)
因此,vec的内存布局大致如下:
vec扩容:重新分配内存
当向vec插入新元素时,如果没有空闲容量,则会重新申请一块内存,大小为原来vec内存大小的两倍(官方手册指明目前Rust并没有确定扩容的策略,以后可能会改变),然后将原vec中的元素拷贝到新内存位置处,同时更新vec的胖指针中的元数据。
例如,有一个容量为10、长度为0的空vec,向该vec中插入前10个元素时不会重新分配内存,但在插入第11个元素时,因容量不够,会重新申请一块内存,容量为20,然后将前10个元素拷贝到新内存位置并将第11个元素放入其中。
通过vec的len()方法可获取该vec当前的元素数量,capacity()方法可获取该vec当前的容量大小。
fn main(){
let mut v1 = vec![11,22,33];
// len: 3, cap: 3
println!("len: {}, cap: {}", v1.len(), v1.capacity());
// push()向vec中插入一个元素,将导致扩容,
// 扩容将导致重新分配vec的内存
v1.push(44);
// len: 4, cap: 6
println!("len: {}, cap: {}", v1.len(), v1.capacity());
}显然,当频繁扩容或者当元素数量较多且需要扩容时,大量的内存拷贝会降低程序的性能。
因此,如果可以的话,可以采取如下方式:
- 在创建vec的时候使用
Vec::with_capacity()指定一个足够大的容量值,以此来尽量减少可能的内存拷贝。 - 通过
reserve()方法来调整已存在的vec容量,使之至少有指定的空闲容量数,以此来尽量减少可能的内存拷贝。
例如:
fn main(){
// 创建一个容量为3的空vec
let mut v1 = Vec::with_capacity(3);
v1.push(11);
v1.push(22);
v1.push(33);
// len: 3, cap: 3
println!("len: {}, cap: {}", v1.len(), v1.capacity());
// 调整v1,使其至少要有10个空闲位置
v1.reserve(10);
// len: 3, cap: 13
println!("len: {}, cap: {}", v1.len(), v1.capacity());
// 当空闲容量足够时,reserve()什么也不做
v1.reserve(5);
println!("len: {}, cap: {}", v1.len(), v1.capacity());
}另外,可以使用shrink_to_fit()方法来释放剩余的容量。一般情况下,不会主动去释放容量。
vec的常用方法
vec的常用方法
vec自身有很多方法,另外vec还可以调用所有Slice类型的方法。
下面是vec自身提供的一些常见的方法,更多方法和它们更详细的用法,参考官方手册:https://doc.rust-lang.org/std/vec/struct.Vec.html。
- len():返回vec的长度(元素数量)
- is_empty():vec是否为空
- push():在vec尾部插入元素
- pop():删除并返回vec尾部的元素,vec为空则返回None
- insert():在指定索引处插入元素
- remove():删除指定索引处的元素并返回被删除的元素,索引越界将panic报错退出
- clear():清空vec
- append():将另一个vec中的所有元素追加移入vec中,移动后另一个vec变为空vec
- truncate():将vec截断到指定长度,多余的元素被删除
- retain():保留满足条件的元素,即删除不满足条件的元素
- drain():删除vec中指定范围的元素,同时返回一个迭代该范围所有元素的迭代器
- split_off():将vec从指定索引处切分成两个vec,索引左边(不包括索引位置处)的元素保留在原vec中,索引右边(包括索引位置处)的元素在返回的vec中
这些方法的用法都非常简单,下面举一些示例来演示它们。
len()和is_empty():
#![allow(unused)]
fn main() {
let v = vec![11,22,33];
assert_eq!(v.len(), 3);
assert!(!v.is_empty());
}push()、pop()、insert()、remove()和clear():
#![allow(unused)]
fn main() {
let mut v = vec![11,22];
v.push(33); // [11,22,33]
assert_eq!(v.pop(), Some(33));
assert_eq!(v.pop(), Some(22));
assert_eq!(v.pop(), Some(11));
assert_eq!(v.pop(), None);
v.insert(0, 111); // [111]
v.insert(1, 222); // [111,222]
v.insert(2, 333); // [111,222,333]
assert_eq!(v.remove(1), 222);
v.clear(); // []
}append():
#![allow(unused)]
fn main() {
let mut v = vec![11,22];
let mut vv = [33,44,55].to_vec();
v.append(&mut vv);
println!("{:?}", v); // [11,22,33,44,55]
println!("{:?}", vv); // []
}truncate():截断到指定长度,多余的元素被删除,如果目标长度大于当前长度,则不做任何事
#![allow(unused)]
fn main() {
let mut v = vec![11,22,33,44];
v.truncate(2);
println!("{:?}", v); // [11, 22]
v.truncate(5); // 不做任何事
}retain():
#![allow(unused)]
fn main() {
let mut v = vec![11, 22, 33, 44];
v.retain(|x| *x > 20);
println!("{:?}", v); // [22,33,44]
}drain():删除指定范围的元素,同时返回该范围所有元素的迭代器。如果删除迭代器,则丢弃迭代器中剩余的元素
#![allow(unused)]
fn main() {
let mut v = vec![11, 22, 33, 44, 55];
let mut vv = v.clone();
// 删除中间3个元素,同时获取到这些元素的迭代器
// 直接丢弃迭代器,所以迭代器中的元素也直接被丢弃
// 这相当于直接删除指定范围的元素
v.drain(1..=3);
println!("{:?}", v); // [11, 55]
// 将迭代器中的元素转换为Vec<i32>
let a: Vec<i32> = vv.drain(1..=3).collect();
println!("{:?}", a); // [22, 33, 44]
println!("{:?}", vv); // [11, 55]
}split_off():
#![allow(unused)]
fn main() {
let mut v = vec![11, 22, 33, 44, 55];
let vv = v.split_off(2);
println!("{:?}", v); // [11, 22]
println!("{:?}", vv); // [33, 44, 55]
}Struct类型
Struct是Rust中非常重要的一种数据类型,它可以容纳各种类型的数据,并且在存放数据的基本功能上之外还提供一些其他功能,比如可以为Struct类型定义方法。
实际上,Struct类型类似于面向对象的类,Struct的实例则类似于对象。Struct的实例和面向对象中的对象都可以看作是使用key-value模式的hash结构去存储数据,同时附带一些其他功能。
Struct的基本使用
Struct的基本使用
使用struct关键字定义Struct类型。
具名Struct
具名Struct(named Struct)表示有字段名称的Struct。Struct的字段(Field)也可以称为Struct的属性(Attribute)。
例如,定义一个名为Person的Struct结构体,Person包含三个属性,分别是name、age和email,每个属性都需要指定数据类型,这样可以限制各属性允许存放什么类型的数据。
#![allow(unused)]
fn main() {
struct Person{
name: String,
age: u32,
email: String, // 最后一个字段的逗号可省略,但建议保留
}
}定义Struct后,可创建Struct的实例对象,为其各个属性指定对应的值即可。
例如,构造Person结构体的实例对象user1,
#![allow(unused)]
fn main() {
let user1 = Person {
name: String::from("junmajinlong"),
email: String::from("[email protected]"),
age: 23,
};
}创建user1实例对象后,可以通过user1.name访问它的name字段的值,user1.age访问它的age字段的值。
以下是一段完整的代码:
struct Person{
name: String,
age: u32,
email: String,
}
fn main(){
let user1 = Person{
name: String::from("junmajinlong"),
email: String::from("[email protected]"),
age: 23,
};
// 访问user1实例name字段、age字段和email字段的值
println!(
"name: {}, age: {}, email: {}",
user1.name, user1.age, user1.email
);
}构造struct的简写方式
当要构造的Struct实例的字段值来自于变量,且这个变量名和字段名相同,则可以简写该字段。
struct Person{
name: String,
age: u32,
email: String,
}
fn main(){
let name = String::from("junmajinlong");
let email = String::from("[email protected]");
let user1 = Person{
name, // 简写,等价于name: name
email, // 简写,等价于email: email
age: 23,
};
}有时候会基于一个Struct实例构造另一个Struct实例,Rust允许通过..xx的方式来简化构造struct实例的写法:
#![allow(unused)]
fn main() {
let name = String::from("junmajinlong");
let email = String::from("[email protected]");
let user1 = Person{
name,
email,
age: 23,
};
let mut user2 = Person{
name: String::from("gaoxiaofang"),
email: String::from("[email protected]"),
..user1
};
}上面的..user1表示让user2借用或拷贝user1的某些字段值,由于user2中已经手动定义了name和email字段,因此..user1只借用了user1的age字段,即user2.age也是23。
注意,如果..base借用于base的字段是可Copy的,那么在借用时会自动Copy,这样在借用字段之后,base中的字段仍然有效。但如果借用的字段不是Copy的,那么在借用时会将base中字段的所有权转移走,使得base中的该字段无效。
例如,同时借用user1中的age字段和email字段,由于age是i32类型,是Copy的,所以user1.age仍然可用,但由于String类型不是Copy的,所以user1.email不可用。
#![allow(unused)]
fn main() {
let name = String::from("junmajinlong");
let email = String::from("[email protected]");
let user1 = Person{
name,
email,
age: 23,
};
let mut user2 = Person{
name: String::from("gaoxiaofang"),
..user1
};
// 报错,user1.email字段值的所有权已借给user2
// println!("{}", user1.email);
// println!("{}", user1); // 报错
println!("{}", user1.name); // 正确
println!("{}", user1.age); // 正确
}如果确实要借用user1的email属性,可以使用..user1.clone()先拷贝堆内存中的user1,这样就不会借用原始的user1中的email所有权。
#![allow(unused)]
fn main() {
let user2 = Person{
name: String::from("ggg"),
..user1.clone()
}
}tuple struct
除了named struct外,Rust还支持没有字段名的struct结构体,称为元组结构体(tuple struct)。
例如:
#![allow(unused)]
fn main() {
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}black和origin值的类型不同,因为它们是不同的结构体的实例。在其他方面,元组结构体实例类似于元组:可以将其解构,也可以使用.后跟索引来访问单独的值,等等。
unit-like struct
类单元结构体(unit-like struct)是没有任何字段的空struct。
#![allow(unused)]
fn main() {
struct St;
}调试输出Struct
调试输出Struct
在开发过程中,很多时候会想要查看某个struct实例中的数据,但直接输出是不行的:
struct Person{
name: String,
age: i32,
}
fn main(){
let p = Person{
name: String::from("junmajinlong"),
age: 23,
};
// 直接输出p会报错
println!("{}", p);
}这时需要在struct Person前加上#[derive(Debug)],然后使用{:?}或{:#?}进行调试输出。
#[derive(Debug)]
struct Person{
name: String,
age: i32,
}
fn main(){
let p = Person{
name: String::from("junmajinlong"),
age: 23,
};
println!("{:?}", p);
println!("{:#?}", p);
}输出结果:
Person { name: "junmajinlong", age: 23 }
Person {
name: "junmajinlong",
age: 23,
}
定义Struct的方法
定义Struct的方法
Struct就像面向对象的类一样,Rust允许为Struct定义实例方法和关联方法,实例方法可被所有实例对象访问调用,关联方法类似于其他语言中的类方法或静态方法。
定义Struct的方法的语法为impl Struct_Name {},所有方法定义在大括号中。
定义Struct的实例方法
实例方法是所有实例对象可访问、调用的方法。
例如:
struct Rectangle{
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn perimeter(&self) -> u32 {
(self.width + self.height) * 2
}
}
fn main() {
let rect1 = Rectangle{width: 30, height: 50};
println!("{},{}", rect1.area(), rect1.perimeter());
}也可以将方法定义在多个impl Struct_Name {}中。如下:
#![allow(unused)]
fn main() {
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn perimeter(&self) -> u32 {
(self.width + self.height) * 2
}
}
impl Rectangle {
fn include(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
}所有Struct的实例方法的第一个参数都是self(的不同形式)。self表示调用方法时的Struct实例对象(如rect1.area()时,self就是rect1)。有如下几种self形式:
fn f(self):当obj.f()时,转移obj的所有权,调用f方法之后,obj将无效fn f(&self):当obj.f()时,借用而非转移obj的只读权,方法内部不可修改obj的属性,调用f方法之后,obj依然可用fn f(&mut self):当obj.f()时,借用obj的可写权,方法内部可修改obj的属性,调用f方法之后,obj依然可用
定义方法时很少使用第一种形式fn f(self),因为这会使得调用方法后对象立即消失。但有时候也能派上场,例如可用于替换对象:调用方法后原对象消失,但返回另一个替换后的对象。
如果仔细观察的话,会发现方法的第一个参数self(或其他形式)没有指定类型。实际上,在方法的定义中,self的类型为Self(首字母大写)。例如,为Rectangle定义方法时,Self类型就是Rectangle类型。因此,下面几种定义方法的方式是等价的:
#![allow(unused)]
fn main() {
fn f(self)
fn f(self: Self)
fn f(&self)
fn f(self: &Self)
fn f(&mut self)
fn f(self: &mut Self)
}Rust的自动引用和解引用
在C/C++语言中,有两个不同的运算符来调用方法:.直接在对象上调用方法,->在一个对象指针上调用方法,这时需要先解引用(dereference)指针。
换句话说,如果obj是一个指针,那么obj->something()就像(*obj).something()一样。更典型的是Perl,Perl的对象总是引用类型,因此它调用方法时总是使用obj->m()形式。
Rust不会自动引用或自动解除引用,但有例外:当使用.运算符和比较操作符(如= > >=)时,Rust会自动创建引用和解引用,并且会尽可能地解除多层引用:
- (1).方法调用
v.f()会自动解除引用或创建引用 - (2).属性访问
p.name或p.0会自动解除引用 - (3).比较操作符的两端如果都是引用类型,则自动解除引用
- (4).能自动解除的引用包括普通引用
&x、Box<T>、Rc<T>等
对于(1),方法调用时的自动引用和自动解除引用,它是这样工作的:当使用ob.something()调用方法时,Rust会根据所调用方法的签名进行推断(即根据方法的接收者self参数的形式进行推断),然后自动为object添加&, &mut来创建引用或添加*来自动解除引用,其目的是让obj与方法签名相匹配。
也就是说,当distance方法的第一个形参是&self或&mut self时,下面代码是等价的,但第一行看起来简洁的多:
#![allow(unused)]
fn main() {
p1.distance(&p2);
(&p1).distance(&p2);
}关联函数(associate functions)
关联函数是指第一个参数不是self(的各种形式)但和Struct有关联关系的函数。关联方法类似于其他语言中类方法或静态方法的概念。
调用关联方法的语法StructName::func()。例如,String::from()就是在调用String的关联方法from()。
例如,可以定义一个专门用于构造实例对象的关联函数new。
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
// 关联方法new:构造Rectangle的实例对象
fn new(width: u32, height: u32) -> Rectangle {
Rectangle { width, height }
}
}
impl Rectangle {
fn area(&self) -> u32 { self.width * self.height }
}
fn main() {
// 调用关联方法
let rect1 = Rectangle::new(30, 50);
let rect2 = Rectangle::new(20, 50);
println!("{}", rect1.area());
println!("{}", rect2.area());
}实际上,实例方法也属于关联方法,也可以采用关联方法的形式去调用,只不过这时需要手动传递第一个self参数。例如:
#![allow(unused)]
fn main() {
// 调用Rectangle的area方法,并传递参数&self
Rectangle::area( &rect1 );
}Enum类型
枚举(Enum)类型通常用来归纳多种可穷举的具体事物。简单点说,枚举是一种包含零个、一个或多个具体值的数据类型。
比如,下面列出的几种情况都可以定义为枚举类型:
- 【性别】包含男和女
- 【月份】包含一月、二月、……、十二月
- 【星期】包含星期一、星期二、……、星期日
- 【会员】包含免费会员、vip1、vip2、vip3
- 【方向键】包含上、下、左、右
- 【方向】包含东、南、西、北
但枚举类型不能用来描述无法穷举的事物。例如【整数】虽然包含0、1、2、……,但这样的值无穷无尽,此时不应该直接用枚举类型,而应该使用具有概括性的方式去描述它们,比如枚举正整数、0、负整数这三种情况,也可以枚举所需的1、2、3后,再用一个额外的Other来通配所有其他情况。
Rust支持枚举类型,且Rust的枚举类型比其他语言的枚举类型更为强大。
Enum的基本使用
Enum的基本使用
Rust使用enum关键字定义枚举类型(Enum)。
例如,定义一个用来描述性别的枚举类型,名为Gender,它只枚举两种值:Male(表示男),Female(表示女)。
#![allow(unused)]
fn main() {
enum Gender {
Male, // 男
Female, // 女
}
}Enum作为一种数据类型,可以用来限制允许存放的数据。比如某变量的数据类型是Gender类型,那么该变量只允许存放指定的两种值:Male或Female,不允许存放其他任何值。也就是说,枚举类型的每个实例都是从枚举类型中进行多选一的值。
#![allow(unused)]
fn main() {
let g1: Gender = Gender::Male;
let g2: Gender = Gender::Female;
// let g3: Gender = "male"; // 不允许
}注意上面变量的类型为Gender,引用Enum内部值的方式为Gender::Male。
Gender类型内部的Male和Female称为枚举类型的值或者枚举类型的成员,还可以称为是枚举类型的实例。反过来思考,不管是Male成员还是Female成员,它们都属于Gender类型,是Gender类型的一种值。就像12_u8是u8类型的其中一个值,属于u8类型。
例如:
enum Gender {
Male,
Female,
}
// 参数类型为Gender
fn is_male(g: Gender) -> bool {
// ...some code...
}
fn main() {
// 可传递Gender已枚举的值作为参数
assert!(is_male(Gender::Male));
assert!(is_male(Gender::Female));
}再比如,定义一个Choice枚举类型,用来枚举由用户所作出的所有可能选择。
#![allow(unused)]
fn main() {
enum Choice {
One,
Two,
Three,
Other,
}
}Choice枚举四种可能的值,其中第四种Other表示除前三种选择之外的所有其他选择行为,包括错误的选择(比如通过某种手段选择了不存在的选项)。
Rust中经常会看到类似于Choice的这种用法,在枚举类型中额外使用一个可以归纳剩余所有可能的成员,正如上面的Other归纳了所有其他可能的选择。
其实,前文定义的枚举类型,其每个成员都有对应的数值。默认第一个成员对应的数值为0,第二个成员的对应的数值为1,后一个成员的数值总是比其前一个数值大1。并且,可以使用=为成员指定数值,但指定值时需注意,不同成员对应的数值不能相同。
例如:
#![allow(unused)]
fn main() {
enum E {
A, // 对应数值0
B, // 自动加1,对应1
C = 33, // 对应33
D, // 自动加1,对应34
}
}定义之后,可使用as将enum成员转换为对应的数值。
例如,定义英文的星期和数值相对应的枚举。
enum Week {
Monday = 1, // 1
Tuesday, // 2
Wednesday, // 3
Thursday, // 4
Friday, // 5
Saturday, // 6
Sunday, // 7
}
fn main(){
// mon等于1
let mon = Week::Monday as i32;
}可在enum定义枚举类型的前面使用#[repr]来指定枚举成员的数值范围,超出范围后将编译错误。当不指定类型限制时,Rust尽量以可容纳数据大小的最小类型。例如,最大成员值为100,则用一个字节的u8类型,最大成员值为500,则用两个字节的u16。
#![allow(unused)]
fn main() {
// 最大数值不能超过255
#[repr(u8)] // 限定范围为`0..=255`
enum E {
A,
B = 254,
C,
D, // 256,超过255,编译报错
}
}定义Enum的完整语法
定义Enum的完整语法
enum创建枚举类型有多种方式,其每个成员的定义都类似于创建Struct结构的语法。
例如:
#![allow(unused)]
fn main() {
enum E {
F1, // 该成员类似于unit-like struct
F2(i32, u64), // 该成员类似于tuple struct
F3{x: i32, y: u64}, // 该成员类似于named struct
}
}F1成员这种定义方式自无需再多做介绍,前文定义的枚举类型都是这种类型的成员。
F2成员的定义类似于tuple struct,F2成员包含两个字段,这两个字段类型分别是i32和u64。也就是说,枚举类型E的F2成员,是一个包含了具体数据的成员。
F3成员的定义类似于named struct,F3成员包含x和y两个字段,字段类型分别是i32和u64。也就是说,枚举类型E的F3成员,也是一个包含了具体数据的成员。
正是因为枚举类型允许定义F2和F3这种包含数据的成员,使得枚举类型在Rust中扮演的角色变得更为重要。
例如,Rust要实现一个Json解析工具,只需定义一个枚举类型去枚举Json允许的数据类型,参考如下代码。
#![allow(unused)]
fn main() {
enum Json {
Null,
Boolean(bool),
Number(f64),
String(String),
Array(Vec<Json>),
Object(Box<HashMap<String, Json>>),
}
}不可否认,Rust语言的表达能力很强。例如这里的枚举类型,仅仅这样一个简单的数据结构就表达出很多内容,而在其它语言中,这可能需要定义很多方法来表达出这些内容。
为枚举类型定义方法
为枚举类型定义方法
和Struct类型一样,也可以使用impl关键字为枚举类型定义方法。
例如,定义包含星期一到星期日的枚举类型Week,然后定义一个方法来判断给定的某一天是否是周末。
#[derive(Copy, Clone)]
enum Week {
Monday = 1,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday,
}
impl Week {
fn is_weekend(&self) -> bool {
if (*self as u8) > 5 {
return true;
}
false
}
}
fn main(){
let d = Week::Thursday;
println!("{}", d.is_weekend());
}模式匹配
模式匹配官方手册参考:https://doc.rust-lang.org/reference/patterns.html。
Rust中经常使用到的一个强大功能是模式匹配(pattern match),例如let变量赋值本质上就是在进行模式匹配。得益于Rust模式匹配功能的强大,使用模式匹配比不使用模式匹配,往往会减少很多代码。
模式匹配的基本使用
模式匹配的基本使用
可在如下几种情况下使用模式匹配:
- let变量赋值
- 函数参数传值时的模式匹配
- match分支
- if let
- while let
- for迭代的模式匹配
let变量赋值时的模式匹配
let变量赋值时的模式匹配:
#![allow(unused)]
fn main() {
let PATTERN = EXPRESSION;
}变量是一种最简单的模式,变量名位于Pattern位置,赋值时的过程:将表达式与模式进行比较匹配,并将任何模式中找到的变量名进行对应的赋值。
例如:
#![allow(unused)]
fn main() {
let x = 5;
let (x, y) = (1, 2);
}第一条语句,变量x是一个模式,在执行该语句时,将表达式5赋值给找到的变量名x。变量赋值总是可以匹配成功。
第二条语句,将表达式(1,2)和模式(x,y)进行匹配,匹配成功,于是为找到的变量x和y进行赋值:x=1,y=2。
如果模式中的元素数量和表达式中返回的元素数量不同,则匹配失败,编译将无法通过。
#![allow(unused)]
fn main() {
let (x,y,z) = (1,2); // 失败
}函数参数传值时的模式匹配
为函数参数传值和使用let变量赋值是类似的,本质都是在做模式匹配的操作。
例如:
#![allow(unused)]
fn main() {
fn f1(i: i32){
// xxx
}
fn f2(&(x, y): &(i32, i32)){
// yyy
}
}函数f1的参数i就是模式,当调用f1(88)时,88是表达式,将赋值给找到的变量名i。
函数f2的参数&(x,y)是模式,调用f2( &(2,8) )时,将表达式&(2,8)与模式&(x,y)进行匹配,并为找到的变量名x和y进行赋值:x=2,y=8。
match分支匹配
match分支匹配的用法非常灵活,此处只做基本的用法介绍,后文还会继续深入其用法。
它的语法为:
#![allow(unused)]
fn main() {
match VALUE {
PATTERN1 => EXPRESSION1,
PATTERN2 => EXPRESSION2,
PATTERN3 => EXPRESSION3,
}
}其中=>左边的是各分支的模式,VALUE将与这些分支逐一进行匹配,=>右边的是各分支匹配成功后执行的代码。每个分支后使用逗号分隔各分支,最后一个分支的结尾逗号可以省略(但建议加上)。
match会从前先后匹配各分支,一旦匹配成功则不再继续向下匹配。
例如:
#![allow(unused)]
fn main() {
let x = (11, 22);
match x {
(22, a) => println!("(22, {})", a), // 匹配失败
(a, b) => println!("({}, {})", a, b), // 匹配成功,停止匹配
(a, 11) => println!("({}, 11)", a), // 匹配失败
}
}如果某分支对应的要执行的代码只有一行,则直接编写该行代码,如果要执行的代码有多行,则需加上大括号包围这些代码。无论加不加大括号,每个分支都是一个独立的作用域。
因此,上述match的语法可衍生为如下两种语法:
#![allow(unused)]
fn main() {
match VALUE {
PATTERN1 => code1,
PATTERN2 => code2,
PATTERN3 => code3,
}
match VALUE {
PATTERN1 => {
code line 1
clod line 2
},
PATTERN2 => {
code line 1
clod line 2
},
PATTERN3 => code1,
}
}另外,match结构自身也是表达式,它有返回值,且可以赋值给变量。match的返回值由每个分支最后执行的那行代码决定。Rust要求match的每个分支返回值类型必须相同,且如果是一个单独的match表达式而不是赋值给变量时,每个分支必须返回()类型。
例如:
#![allow(unused)]
fn main() {
let x = (11,22);
// 正确,match没有赋值给变量,分支必须返回Unit值()
match x {
(a, b) => println!("{}, {}", a, b), // 返回Unit值()
// 其他正确写法:{println!("{}, {}", a, b);},
// 错误写法: println!("{}, {}", a, b);,
}
// 正确,每个分支都返回Unit值()
match x {
(a,11) => println!("{}", a), // 该分支匹配失败
(a,b) => println!("{}, {}", a, b), // 将匹配该分支
}
// match返回值赋值给变量,每个分支必须返回相同的类型:i32
let y = match x {
(a,11) => {
println!("{}", a);
a // 该分支的返回值:i32类型
},
(a,b) => {
println!("{}, {}", a, b);
a + b // 该分支的返回值:i32类型
},
};
}match也经常用来穷举Enum类型的所有成员。此时要求穷尽所有成员,如果有遗漏成员,编译将失败。可以将_作为最后一个分支的PATTERN,它将匹配剩余所有成员。
enum Direction {
Up,
Down,
Left,
Right,
}
fn main(){
let dir = match Direction::Down {
Direction::Up => 1,
Direction::Down => 2,
Direction::Right => 3,
_ => 4,
};
println!("{}", dir);
}if let
if let是match的一种特殊情况的语法糖:当只关心一个match分支,其余情况全部由_负责匹配时,可以将其改写为更精简if let语法。
#![allow(unused)]
fn main() {
if let PATTERN = EXPRESSION {
// xxx
}
}这表示将EXPRESSION的返回值与PATTERN模式进行匹配,如果匹配成功,则为找到的变量进行赋值,这些变量在大括号作用域内有效。如果匹配失败,则不执行大括号中的代码。
例如:
#![allow(unused)]
fn main() {
let x = (11, 22);
// 匹配成功,因此执行大括号内的代码
// if let是独立作用域,变量a b只在大括号中有效
if let (a, b) = x {
println!("{},{}", a, b);
}
// 等价于如下代码
let x = (11, 22);
match x {
(a, b) => println!("{},{}", a, b),
_ => (),
}
}if let可以结合else if、else if let和else一起使用。
#![allow(unused)]
fn main() {
if let PATTERN = EXPRESSION {
// XXX
} else if {
// YYY
} else if let PATTERN = EXPRESSION {
// zzz
} else {
// zzzzz
}
}这时候它们和match多分支类似。但实际上有很大的不同:使用match分支匹配时,要求分支之间是有关联(例如枚举类型的各个成员)且穷尽的,但Rust编译器不会检查if let的模式之间是否有关联关系,也不检查if let是否穷尽所有可能情况,因此,即使在逻辑上有错误,Rust也不会给出编译错误提醒。
例如,下面是一个使用了if let..else if let的示例,该示例穷举了Enum类型的所有成员,还包括该枚举类型之外的情况,但即使去掉任何一个分支,也都不会报错。
enum Direction {
Up,
Down,
Left,
Right,
}
fn main() {
let dir = Direction::Down;
if let Direction::Left = dir {
println!("Left");
} else if let Direction::Right = dir {
println!("Right");
} else {
println!("Up or Down or wrong");
}
}while let
只要while let的模式匹配成功,就会一直执行while循环内的代码。
例如:
#![allow(unused)]
fn main() {
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
while let Some(top) = stack.pop() {
println!("{}", top);
}
}当stack.pop成功时,将匹配Some(top)成功,并将pop返回的值赋值给top,当没有元素可pop时,返回None,匹配失败,于是while循环退出。
for迭代
for迭代也有模式匹配的过程:为控制变量赋值。例如:
#![allow(unused)]
fn main() {
let v = vec!['a','b','c'];
for (idx, value) in v.iter().enumerate(){
println!("{}: {}", idx, value);
}
}模式的完整语法
模式的两种形式:refutable和irrefutable
从前文介绍的几种模式匹配可知,模式匹配的方式不唯一:
- (1).模式匹配必须匹配成功,匹配失败就报错,主要是变量赋值型的(let/for/函数传参)模式匹配
- (2).模式匹配可以匹配失败,匹配失败时不执行相关代码
Rust中为这两种匹配模式定义了专门的称呼:
- 不可反驳的模式(irrefutable):一定会匹配成功,否则编译错误
- 可反驳的的模式(refutable):可以匹配成功,也可以匹配失败,匹配失败的结果是不执行对应分支的代码
let变量赋值、for迭代、函数传参这三种模式匹配只接受不可反驳模式。if let和while let只接受可反驳模式。
match则支持两种模式:
- 当明确给出分支的Pattern时,必须是可反驳模式,这些模式允许匹配失败
- 使用
_作为最后一个分支时,是不可反驳模式,它一定会匹配成功 - 如果只有一个Pattern分支,则可以是不可反驳模式,也可以是可反驳模式
当模式匹配处使用了不接受的模式时,将会编译错误或给出警告。
#![allow(unused)]
fn main() {
// let变量赋值时使用可反驳的模式(允许匹配失败),编译失败
let Some(x) = some_value;
// if let处使用了不可反驳模式,没有意义(一定会匹配成功),给出警告
if let x = 5 {
// xxx
}
}对于match来说,以下几个示例可说明它的使用方式:
#![allow(unused)]
fn main() {
match value {
Some(5) => (), // 允许匹配失败,是可反驳模式
Some(50) => (),
_ => (), // 一定会匹配成功,是不可反驳模式
}
match value {
// 当只有一个Pattern分支时,可以是不可反驳模式
x => println!("{}", x),
_ => (),
}
}完整的模式语法
下面系统性地介绍Rust中的Pattern语法。
字面量模式
模式部分可以是字面量:
#![allow(unused)]
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
_ => println!("anything"),
}
}模式带有变量名
例如:
fn main() {
let x = (11, 22);
let y = 10;
match x {
(22, y) => println!("Got: (22, {})", y),
(11, y) => println!("y = {}", y), // 匹配成功,输出22
_ => println!("Default case, x = {:?}", x),
}
println!("y = {}", y); // y = 10
}上面的match会匹配第二个分支,同时为找到的变量y进行赋值,即y=22。这个y只在第二个分支对应的代码部分有效,跳出作用域后,y恢复为y=10。
多选一模式
使用|可组合多个模式,表示逻辑或(or)的意思。
#![allow(unused)]
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}范围匹配模式
Rust支持数值和字符的范围,有如下几种范围表达式:
| Production | Syntax | Type | Range |
|---|---|---|---|
| RangeExpr | start..end | std::ops::Range | start ≤ x < end |
| RangeFromExpr | start.. | std::ops::RangeFrom | start ≤ x |
| RangeToExpr | ..end | std::ops::RangeTo | x < end |
| RangeFullExpr | .. | std::ops::RangeFull | - |
| RangeInclusiveExpr | start..=end | std::ops::RangeInclusive | start ≤ x ≤ end |
| RangeToInclusiveExpr | ..=end | std::ops::RangeToInclusive | x ≤ end |
但范围作为模式匹配的Pattern时,只允许使用全闭合的..=范围语法,其他类型的范围类型都会报错。
例如:
#![allow(unused)]
fn main() {
// 数值范围
let x = 79;
match x {
0..=59 => println!("不及格"),
60..=89 => println!("良好"),
90..=100 => println!("优秀"),
_ => println!("error"),
}
// 字符范围
let y = 'c';
match y {
'a'..='j' => println!("a..j"),
'k'..='z' => println!("k..z"),
_ => (),
}
}模式解构赋值
模式解构赋值
模式匹配时可用于解构赋值,可解构的类型包括struct、enum、tuple、slice等等。
解构赋值时,可使用_作为某个变量的占位符,使用..作为剩余所有变量的占位符(使用..时不能产生歧义,例如(..,x,..)是有歧义的)。当解构的类型包含了命名字段时,可使用fieldname简化fieldname: fieldname的书写。
解构struct
解构Struct时,会将待解构的struct各个字段和Pattern中的各个字段进行匹配,并为找到的字段变量进行赋值。
当Pattern中的字段名和字段变量同名时,可简写。例如P{name: name, age: age}和P{name, age}是等价的Pattern。
struct Point2 {
x: i32,
y: i32,
}
struct Point3 {
x: i32,
y: i32,
z: i32,
}
fn main(){
let p = Point2{x: 0, y: 7};
// 等价于 let Point2{x: x, y: y} = p;
let Point2{x, y} = p;
println!("x: {}, y: {}", x, y);
// 解构时可修改字段变量名: let Point2{x: a, y: b} = p;
// 此时,变量a和b将被赋值
let ori = Point{x: 0, y: 0, z: 0};
match ori{
// 使用..忽略解构后剩余的字段
Point3 {x, ..} => println!("{}", x),
}
}解构enum
例如:
enum IPAddr {
IPAddr4(u8,u8,u8,u8),
IPAddr6(String),
}
fn main(){
let ipv4 = IPAddr::IPAddr4(127,0,0,1);
match ipv4 {
// 丢弃解构后的第四个值
IPAddr::IPAddr4(a,b,c,_) => println!("{},{},{}", a,b,c),
IPAddr::IPAddr6(s) => println!("{}", s),
}
}解构元组
#![allow(unused)]
fn main() {
let ((feet, inches), Point {x, y}) = ((3, 1), Point { x: 3, y: -1 });
}@绑定变量名
当解构后进行模式匹配时,如果某个值没有对应的变量名,则可以使用@手动绑定一个变量名。
例如:
#![allow(unused)]
fn main() {
struct S(i32, i32);
match S(1, 2) {
// 如果匹配1成功,将其赋值给变量z
// 如果匹配2成功,也将其赋值给变量z
S(z @ 1, _) | S(_, z @ 2) => assert_eq!(z, 1),
_ => panic!(),
}
}再例如,匹配并解构一个数组:
#![allow(unused)]
fn main() {
let arr = ["x", "y", "z"];
match arr {
[.., "!"] => println!("!!!"),
// 匹配成功,start = ["x", "y"]
[start @ .., "z"] => println!("starts: {:?}", start),
["a", end @ ..] => println!("ends: {:?}", end),
rest => println!("{:?}", rest),
}
}ref和mut修饰模式中的变量
当进行解构赋值时,很可能会将变量拥有的所有权转移出去,从而使得原始变量变得不完整或直接失效。
struct Person{
name: String,
age: i32,
}
fn main(){
let p = Person{name: String::from("junmajinlong"), age: 23};
let Person{name, age} = p;
println!("{}", name);
println!("{}", age);
println!("{}", p.name); // 错误,name字段所有权已转移
}如果想要在解构赋值时不丢失所有权,有以下几种方式:
#![allow(unused)]
fn main() {
// 方式一:解构表达式的引用
let Person{name, age} = &p;
// 方式二:解构表达式的克隆,适用于可调用clone()方法的类型
// 但Person struct没有clone()方法
// 方式三:在模式的某些字段或元素上使用ref关键字修饰变量
let Person{ref name, age} = p;
let Person{name: ref n, age} = p;
}在模式中使用ref修饰变量名相当于对被解构的字段或元素上使用&进行引用。
#![allow(unused)]
fn main() {
let x = 5_i32; // x的类型:i32
let x = &5_i32; // x的类型:&i32
let ref x = 5_i32; // x的类型:&i32
let ref x = &5_i32; // x的类型:&&i32
}因此,使用ref修饰了模式中的变量后,解构赋值时对应值的所有权就不会发生转移,而是以只读的方式借用给该变量。
如果想要对解构赋值的变量具有数据的修改权,需要使用mut关键字修饰模式中的变量,但这样会转移原值的所有权,此时可不要求原变量是可变的。
#[derive(Debug)]
struct Person {
name: String,
age: i32,
}
fn main() {
let p = Person {
name: String::from("junma"),
age: 23,
};
match p {
Person { mut name, age } => {
name.push_str("jinlong");
println!("name: {}, age: {}", name, age)
},
}
//println!("{:?}", p); // 错误
}如果不想在可修改数据时丢失所有权,可在mut的基础上加上ref关键字,就像&mut xxx一样。
#[derive(Debug)]
struct Person {
name: String,
age: i32,
}
fn main() {
let mut p = Person { // 这里要改为mut p
name: String::from("junma"),
age: 23,
};
match p {
// 这里要改为ref mut name
Person { ref mut name, age } => {
name.push_str("jinlong");
println!("name: {}, age: {}", name, age)
},
}
println!("{:?}", p);
}注意,使用ref修饰变量只是借用了被解构表达式的一部分值,而不是借用整个值。如果要匹配的是一个引用,则使用&。
#![allow(unused)]
fn main() {
let a = &(1,2,3); // a是一个引用
let (t1,t2,t3) = a; // t1,t2,t3都是引用类型&i32
let &(x,y,z) = a; // x,y,z都是i32类型
let &(ref xx,yy,zz) = a; // xx是&i32类型,yy,zz是i32类型
}最后,也可以将match value{}的value进行修饰,例如match &mut value {},这样就不需要在模式中去加ref和mut了。这对于有多个分支需要解构赋值,且每个模式中都需要ref/mut修饰变量的match非常有用。
fn main() {
let mut s = "hello".to_string();
match &mut s { // 对可变引用进行匹配
// 匹配成功时,变量也是对原数据的可变引用
x => x.push_str("world"),
}
println!("{}", s);
}匹配守卫(match guard)
匹配守卫允许匹配分支添加额外的后置条件:当匹配了某分支的模式后,再检查该分支的守卫后置条件,如果守卫条件也通过,则成功匹配该分支。
#![allow(unused)]
fn main() {
let x = 33;
match x {
// 先范围匹配,范围匹配成功后,再检查是否是偶数
// 如果范围匹配没有成功,则不会检查后置条件
0..=50 if x % 2 == 0 => {
println!("x in [0, 50], and it is an even");
},
0..=50 => println!("x in [0, 50], but it is not an even"),
_ => (),
}
}注意,后置条件的优先级很低。例如:
#![allow(unused)]
fn main() {
// 下面两个分支的写法等价
4 | 5 | 6 if bool_expr => println!("yes"),
(4 | 5 | 6) if bool_expr => println!("yes"),
}注意(1):对引用进行解构赋值时
在解构赋值时,如果解构的是一个引用,则被匹配的变量也将被赋值为对应元素的引用。
#![allow(unused)]
fn main() {
let t = &(1,2,3); // t是一个引用
let (t0,t1,t2) = t; // t0,t1,t2的类型都是&i32
let t0 = t.0; // t0的类型是i32而不是&i32,因为t.0等价于(*t).0
let t0 = &t.0; // t0的类型是&i32而不是i32,&t.0等价于&(t.0)而非(&t).0
}因此,当使用模式匹配语法for i in t进行迭代时:
- 如果t不是一个引用,则t的每一个元素都会move给i
- 如果t是一个引用,则i将是每一个元素的引用
- 同理,
for i in &mut t和for i in mut t也一样
注意(2):对解引用进行匹配时
当match VALUE的VALUE是一个解引用*xyz时(因此,xyz是一个引用),可能会发生所有权的转移,此时可使用xyz或&*xyz来代替*xyz。具体原因请参考:解引用(deref)的所有权转移问题。
下面是一个示例:
fn main() {
// p是一个Person实例的引用
let p = &Person {
name: "junmajinlong".to_string(),
age: 23,
};
// 使用&*p或p进行匹配,而不是*p
// 使用*p将报错,因为会转移所有权
match &*p {
Person {name, age} =>{
println!("{}, {}",name, age);
},
_ => (),
}
}
struct Person {
name: String,
age: u8,
}Trait和Trait Object
从多种数据类型中抽取出这些类型之间可通用的方法或属性,并将它们放进另一个相对更抽象的类型中,是一种很好的代码复用方式,也是多态的一种体现方式。
在面向对象语言中,这种功能一般通过接口(interface)实现。在Rust中,这种功能通过Trait实现。Trait类似于其他语言中接口的概念。例如,Trait可以被其他具体的类型实现(implement),也可以在Trait中定义一些方法,实现该Trait的类型都必须实现这些方法。
严格来说,Rust中Trait的作用主要体现在两方面:
- Trait类型:用于定义抽象行为,抽取那些共性的属性,主要表现是作为泛型的数据类型(对泛型进行限制)
- Trait对象:即Trait Object,能用于多态
总之,Trait很重要,说是Rust的基石也不为过,它贯穿于整个Rust。本章介绍Trait最基本的内容,更多内容将在后面的泛型章节中展开。
Trait通常翻译为【特性】、【特征】、【特质】,但这些翻译都很尴尬,特别是将特性或特质等这种名词写进文章时,更显别扭。
因此对于Trait这种重要的术语,我不打算做任何转换,直接在文中使用英文原单词。
Trait的基本用法
Trait的基本用法
Trait最基本的作用是从多种类型中抽取出共性的属性或方法,并定义这些方法的规范(即方法签名)。
例如,对于Audio类型和Video类型,它们有几个具有共性的方法:
- play方法用于播放
- pause方法用于暂停
- get_duration方法用于显示媒体的总时长
为了抽取这些共性方法,可定义一个名为Playable的Trait,并在其中规范好这些方法的签名。
自定义Trait类型时,使用trait关键字。如:
#![allow(unused)]
fn main() {
trait Playable {
fn play(&self);
fn pause(&self) {
println!("pause");
}
fn get_duration(&self) -> f32;
}
}注意上面的play方法和get_duration方法都仅仅只规范了它们的方法签名,并没有为它们定义方法体,而pause方法则指定了函数签名且定义了方法体,这个方法体是pause方法的默认方法体。
定义好Playable Trait后,先让Audio类型去实现Playable:
#![allow(unused)]
fn main() {
struct Audio {
name: String,
duration: f32,
}
impl Playable for Audio {
fn play(&self) {
println!("listening audio: {}", self.name);
}
fn get_duration(&self) -> f32 {
self.duration
}
}
}注意,上面impl Playable for Audio表示为Audio类型实现Playable Trait。Audio实现Playable Trait时,Trait中的所有没有提供默认方法体的方法(即play方法和get_duration方法)都需要实现。对于提供了默认方法体的方法,可实现可不实现,如果实现了则覆盖默认方法体,如果没有实现,则使用默认方法体。
下面再为Video类型实现Playable Trait,这里也实现了有默认方法体的pause方法:
#![allow(unused)]
fn main() {
struct Video {
name: String,
duration: f32,
}
impl Playable for Video {
fn play(&self) {
println!("watching video: {}", self.name);
}
fn pause(&self) {
println!("video paused");
}
fn get_duration(&self) -> f32 {
self.duration
}
}
}当Audio类型和Video类型实现了Playable Trait后,这两个类型的实例对象自然可以去调用它们各自定义的方法。而对于Audio没有定义的pause方法,则会从其所实现的Trait中寻找。
fn main() {
let audio = Audio{
name: "telephone.mp3".to_string(),
duration: 4.32,
};
audio.play();
audio.pause();
println!("{}", audio.get_duration());
let video = Video {
name: "Yui Hatano.mp4".to_string(),
duration: 59.59,
};
video.play();
video.pause();
println!("{}", video.get_duration());
}再多理解一点Trait
再多理解一点Trait
从前面示例来看,某类型实现某Trait时,需要定义该Trait中指定的所有方法,定义之后,该类型也会拥有这些方法,似乎看上去和直接为各类型定义这些方法没什么区别。
但是Trait是对多种类型之间的共性进行的抽象,它只规定实现它的类型要定义哪些方法以及这些方法的签名,至于方法体的逻辑则不关心。
也可以换个角度来看待Trait。Trait描述了一种通用功能,这种通用功能要求具有某些行为,这种通用功能可以被很多种类型实现,每个实现了这种通用功能的类型,都可以被称之为是【具有该功能的类型】。
例如,Clone Trait是一种通用功能,描述可克隆的行为,i32类型、i64类型、Vec类型都实现了Clone Trait,那么就可以说i32类型、i64类型、Vec类型具有Clone的功能,可以调用clone()方法。
甚至,数值类型(包括i32、u32、f32等等)的加减乘除功能,也都是通过实现各种对应的Trait而来的。比如,为了支持加法操作+,这些数值类型都实现了std::ops::Add这个Trait。可以这样理解,std::ops::Add Trait是一种通用功能,只要某个类型(包括自定义类型)实现了std::ops::Add这个Trait,这个类型的实例对象就可以使用加法操作。同理,对减法、除法、乘法、取模等等操作,也都如此。
一个类型可以实现很多种Trait,使得这个类型具有很多种功能,可以调用这些Trait的方法。比如,原始数据类型、Vec类型、HashMap类型等等已经定义好可直接使用的类型,都已经实现好了各种各样的Trait(具体实现了哪些Trait需查各自的文档),可以调用这些Trait中的方法。
例如,查看i32类型的官方文档,会发现i32类型实现了非常非常多的Trait,下面截图是i32类型所实现的一部分Trait。

i32类型的绝大多数功能都来自于其实现的各种Trait,用术语来说,那就是i32类型的大多数功能是组合(composite)其他各种Trait而来的(组合优于继承的组合)。
因此,Rust是一门支持组合的语言:通过实现Trait而具备相应的功能,是组合而非继承。
derive Traits
对于Struct类型、Enum类型,需要自己手动去实现各Trait。
但对于一些常见的Trait,可在Struct类型或Enum类型前使用#[derive()]简单方便地实现这些Trait,Rust会自动为Struct类型和Enum类型定义好这些Trait所要求实现的方法。
例如,为下面的Struct类型、Enum类型实现Copy Trait、Clone Trait。
#![allow(unused)]
fn main() {
#[derive(Copy, Clone)]
struct Person {
name: String,
age: u8,
}
#[derive(Copy, Clone)]
enum Direction {
Up,
Down,
Left,
Right,
}
}现在,Person类型和Direction类型就都实现了Copy Trait和Clone Trait,具备了这两个Trait的功能:所有权转移时是可拷贝的、可克隆的。
trait作用域
Rust允许在任何时候为任何类型实现任何Trait。例如,在自己的代码中为标准库Vec类型实现trait A。
#![allow(unused)]
fn main() {
// 伪代码
impl A for Vec {
fn ff(&self){...}
}
}这使得编程人员可以非常方便地为某类型添加功能,无论这个功能来自自定义的Trait还是Rust中已存在的Trait,也无论这个类型是自定义类型还是Rust内置类型。
这和Ruby的一些功能有些相似,Ruby可以在任意位置处使用include添加代表功能的模块,可以在任意位置重新打开类、重新打开对象来定义临时方法。
但对于Rust而言,当类型A实现了Trait T时,想要通过A的实例对象来调用来自于T的方法时,要求Trait T必须在当前作用域内,否则报错。例如:
#![allow(unused)]
fn main() {
// Vec类型已经实现了std::io::Write
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?; // 报错:未找到write_all方法
}上面的代码报错是因为Vec虽然实现了Trait Write,但Write并未在作用域内,因此调用来自Write的方法write_all会查找不到该方法。
根据编译错误提示,加上use std::io::Write即可:
#![allow(unused)]
fn main() {
use std::io::Write;
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?;
}为什么Rust要做如此要求呢?这可以避免冲突。比如张三可以在他的代码中为u8类型实现Trait A,并定义了实现A所需的方法f,张三导入使用的第三方包中可能也为u8类型实现了Trait A,毕竟Rust允许在任何位置为某类型实现某Trait。因此,张三执行(3_u8).f()的时候,Rust必须要能够区分调用的这个f方法来自于何处。
Trait继承
Trait继承
通过让某个类型去实现某个Trait,使得该类型具备该Trait的功能,是组合(composite)的方式。
经常和组合放在一起讨论的是继承(inheritance)。继承通常用来描述属于同种性质的父子关系(is a),而组合用来描述具有某功能(has a)。
例如,支持继承的语言,可以让轿车类型(Car)继承交通工具类型(Vehicle),表明轿车是一种(is a)交通工具,它们是同一种性质的东西。而如果是支持组合的语言,可以定义可驾驶功能Drivable,然后将Driveable组合到轿车类型、轮船类型、飞机类型、卡车类型、玩具车类型,等等,表明这些类型具有(has a)驾驶功能。
Rust除了支持组合,还支持继承。但Rust只支持Trait之间的继承,比如Trait A继承Trait B。实现继承的方式很简单,在定义Trait A时使用冒号加上Trait B即可。
例如:
#![allow(unused)]
fn main() {
trait B{}
trait A: B{}
}如果Trait A继承Trait B,当类型C想要实现Trait A时,将要求同时也要去实现B。
#![allow(unused)]
fn main() {
trait B{
fn func_in_b(&self);
}
// Trait A继承Trait B
trait A: B{
fn func_in_a(&self);
}
struct C{}
// C实现Trait A
impl A for C {
fn func_in_a(&self){
println!("impl: func_in_a");
}
}
// C还要实现Trait B
impl B for C {
fn func_in_b(&self){
println!("impl: func_in_b");
}
}
}现在,C的实例对象将可以调用func_in_a()和func_in_b():
fn main(){
let c = C{};
c.func_in_a();
c.func_in_b();
}Trait Object
理解Trait Object和vtable
Trait的另一个作用是Trait Object。
理解Trait Object也简单:当Car、Boat、Bus实现了Trait Drivable后,在需要Drivable类型的地方,都可以使用实现了Drivable的任意类型,如Car、Boat、Bus。从场景需求来说,需要Drivable的地方,其要求的是具有可驾驶功能,而实现了Drivable的Car、Bus等类型都具有可驾驶功能。
所以,只要能保护唐僧去西天取经,是选孙悟空还是选六耳猕猴,这是无关紧要的,重要的是要求具有保护唐僧的能力。
这和鸭子模型(Duck Typing)有点类似,只要叫起来像鸭子,它就可以当成鸭子来使用。也就是说,真正需要的不是鸭子,而是鸭子的叫声。
再看Rust的Trait Object。按照上面的说法,当B、C、D类型实现了Trait A后,就可以将类型B、C、D当作Trait A来使用。这在概念上来说似乎是正确的,但根据Rust语言的特性,Rust没有直接实现这样的用法。原因之一是,Rust中不能直接将Trait当作数据类型来使用。
例如,Audio类型实现了Trait Playable,在创建Audio实例对象时不能将数据类型指定为Trait Playable。
#![allow(unused)]
fn main() {
// Trait Playable不能作为数据类型
let x: Playable = Audio{
name: "telephone.mp3".to_string(),
duration: 3.42,
};
}这很容易理解,因为一种类型可能实现了很多种Trait,将其实现的其中一种Trait作为数据类型,显然无法代表该类型。
Rust真正支持的用法是:虽然Trait自身不能当作数据类型来使用,但Trait Object可以当作数据类型来使用。因此,可以将实现了Trait A的类型B、C、D当作Trait A的Trait Object来使用。也就是说,Trait Object是Rust支持的一种数据类型,它可以有自己的实例数据,就像Struct类型有自己的实例对象一样。
可以将Trait Object和Slice做对比,它们在不少方面有相似之处。
-
对于类型T,写法
[T]表示类型T的Slice类型,由于Slice的大小不固定,因此几乎总是使用Slice的引用方式&[T],Slice的引用保存在栈中,包含两份数据:Slice所指向数据的起始指针和Slice的长度。 -
对于Trait A,写法
dyn A表示Trait A的Trait Object类型,由于Trait Object的大小不固定,因此几乎总是使用Trait Object的引用方式&dyn A,Trait Object的引用保存在栈中,包含两份数据:Trait Object所指向数据的指针和指向一个虚表vtable的指针。
上面所描述的Trait Object,还有几点需要解释:
- Trait Object大小不固定:这是因为,对于Trait A,类型B可以实现Trait A,类型C也可以实现Trait A,因此Trait Object没有固定大小
- 几乎总是使用Trait Object的引用方式:
- 虽然Trait Object没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成,因此占用两个指针大小,即两个机器字长
- 一个指针指向实现了Trait A的具体类型的实例,也就是当作Trait A来用的类型的实例,比如B类型的实例、C类型的实例等
- 另一个指针指向一个虚表vtable,vtable中保存了B或C类型的实例对于可以调用的实现于A的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了Trait A的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作Trait A来使用时(此时,它们全都看作是Trait A类型的实例),有必要区分这些实例各自有哪些方法可调用
- Trait Object的引用方式有多种。例如对于Trait A,其Trait Object类型的引用可以是
&dyn A、Box<dyn A>、Rc<dyn A>等
简而言之,当类型B实现了Trait A时,类型B的实例对象b可以当作A的Trait Object类型来使用,b中保存了作为Trait Object对象的数据指针(指向B类型的实例数据)和行为指针(指向vtable)。
一定要注意,此时的b被当作A的Trait Object的实例数据,而不再是B的实例对象,而且,b的vtable只包含了实现自Trait A的那些方法,因此b只能调用实现于Trait A的方法,而不能调用类型B本身实现的方法和B实现于其他Trait的方法。也就是说,当作哪个Trait Object来用,它的vtable中就包含哪个Trait的方法。
其实,可以对比着来理解Trait Object,比如v是包含i32类型数据的Vec,v的类型是Vec而不是i32,但v中保存了i32类型的实例数据,另外v也只能调用Vec部分的方法,而不能调用i32相关的方法。
例如:
trait A{
fn a(&self){println!("from A");}
}
trait X{
fn x(&self){println!("from X");}
}
// 类型B同时实现trait A和trait X
// 类型B还定义自己的方法b
struct B{}
impl B {fn b(&self){println!("from B");}}
impl A for B{}
impl X for B{}
fn main(){
// bb是A的Trait Object实例,
// bb保存了指向类型B实例数据的指针和指向vtable的指针
let bb: &dyn A = &B{};
bb.a(); // 正确,bb可调用实现自Trait A的方法a()
bb.x(); // 错误,bb不可调用实现自Trait X的方法x()
bb.b(); // 错误,bb不可调用自身实现的方法b()
}使用Trait Object类型
了解Trait Object之后,使用它就不再难了,它也只是一种数据类型罢了。
例如,前文的Audio类型和Video类型都实现Trait Playable:
#![allow(unused)]
fn main() {
// 为了排版,调整了代码格式
trait Playable {
fn play(&self);
fn pause(&self) {println!("pause");}
fn get_duration(&self) -> f32;
}
// Audio类型,实现Trait Playable
struct Audio {name: String, duration: f32}
impl Playable for Audio {
fn play(&self) {println!("listening audio: {}", self.name);}
fn get_duration(&self) -> f32 {self.duration}
}
// Video类型,实现Trait Playable
struct Video {name: String, duration: f32}
impl Playable for Video {
fn play(&self) {println!("watching video: {}", self.name);}
fn pause(&self) {println!("video paused");}
fn get_duration(&self) -> f32 {self.duration}
}
}现在,将Audio的实例或Video的实例当作Playable的Trait Object来使用:
fn main() {
let x: &dyn Playable = &Audio{
name: "telephone.mp3".to_string(),
duration: 3.42,
};
x.play();
let y: &dyn Playable = &Video{
name: "Yui Hatano.mp4".to_string(),
duration: 59.59,
};
y.play();
}此时,x的数据类型是Playable的Trait Object类型的引用,它在栈中保存了一个指向Audio实例数据的指针,还保存了一个指向包含了它可调用方法的vtable的指针。同理,y也一样。
再比如,有一个Playable的Trait Object类型的数组,在这个数组中可以存放所有实现了Playable的实例对象数据:
use std::fmt::Debug;
fn main() {
let a:&dyn Playable = &Audio{
name: "telephone.mp3".to_string(),
duration: 3.42,
};
let b: &dyn Playable = &Video {
name: "Yui Hatano.mp4".to_string(),
duration: 59.59,
};
let arr: [&dyn Playable;2] = [a, b];
println!("{:#?}", arr);
}
trait Playable: Debug {}
#[derive(Debug)]
struct Audio {}
impl Playable for Audio {}
#[derive(Debug)]
struct Video {...}
impl Playable for Video {...}注意,上面为了使用println!的调试输出格式{:#?},要让Playable实现名为std::fmt::Debug的Trait,因为Playable自身也是一个Trait,所以使用Trait继承的方式来继承Debug。继承Debug后,要求实现Playable Trait的类型也都要实现Debug Trait,因此在Audio和Video之前使用#[derive(Debug)]来实现Debug Trait。
上面实例的输出结果:
#![allow(unused)]
fn main() {
[
Audio {
name: "telephone.mp3",
duration: 3.42,
},
Video {
name: "Yui Hatano.mp4",
duration: 59.59,
},
]
}泛型
在编程语言中,变量名是对编程人员友好的名称,在编译期间,变量名会被转换为可被机器识别的内存地址,变量保存了什么数据,变量名就被替换为该数据的内存地址。也就是说,有了变量,编程人员可以使用更友好的变量名而不是使用内存地址来操作内存中的数据。
也可以将变量理解为是对内存中数据的抽象,无论是什么数据值,在编写代码的阶段,都可以用变量来表示这些数据,而在编译阶段,变量则会被替换为它所代表的内存数据。
除了可以使用变量来代表数据,在支持泛型(Generic)的编程语言中,还可以使用泛型来代表各种各样可能的数据类型。泛型之于数据类型,和变量之于内存数据,是类似的。在编写代码阶段,泛型可以表示各种各样的数据类型,(对于Rust来说)在编译阶段,泛型会被替换为它所代表的数据类型。
本章将介绍泛型相关的内容。
泛型的基本使用
泛型的基本使用
通过泛型系统,可以减少很多冗余代码。
例如,不使用泛型时,定义一个参数允许为u8、i8、u16、i16、u32、i32……等类型的double函数时:
fn double_u8(i: u8) -> u8 { i + i }
fn double_i8(i: i8) -> i8 { i + i }
fn double_u16(i: u16) -> u16 { i + i }
fn double_i16(i: i16) -> i16 { i + i }
fn double_u32(i: u32) -> u32 { i + i }
fn double_i32(i: i32) -> i32 { i + i }
fn double_u64(i: u64) -> u64 { i + i }
fn double_i64(i: i64) -> i64 { i + i }
fn main(){
println!("{}",double_u8(3_u8));
println!("{}",double_i16(3_i16));
}上面定义了一堆double函数,函数的逻辑部分是完全一致的,仅在于类型的不同。
泛型可以用于解决这样因类型而代码冗余的问题。使用泛型时:
use std::ops::Add;
fn double<T>(i: T) -> T
where T: Add<Output=T> + Clone + Copy {
i + i
}
fn main(){
println!("{}",double(3_i16));
println!("{}",double(3_i32));
}上面的字母T就是泛型(和变量x的含义是相同的),它用来代表各种可能的数据类型。多数时候泛型使用单个大写字母来表示,但也可以使用多个字母来表示。
对于double函数签名的前一部分:
#![allow(unused)]
fn main() {
fn double<T>(i: T) -> T
}函数名称后面的<T>表示在函数作用域内定义一个泛型T,这个泛型只能在函数签名和函数体内使用,就跟在一个作用域内定义一个变量,这个变量只能在该作用域内使用是一样的。而且,泛型本就是代表各种数据类型的变量。
参数部分i: T表示参数i的类型是泛型T。
返回值部分-> T表示该函数的返回值类型是泛型T。
因此,上面这部分函数签名表达的含义是:传入某种数据类型的参数,也返回这种数据类型的返回值,且这种数据类型可以是任意的类型。
对于第一次接触泛型的人来说,这可能很难理解。但是,换成类似的使用普通变量的代码,可能就容易理解了:
# 伪代码:传入一个数据,返回这个数据
function f(x) {return x}
对泛型进行限制
但注意,double函数期待的是对数值进行加法操作,但泛型却可以代表各种类型,因此,还需要对泛型T进行限制,否则在调用double函数时就允许传递字符串类型、Vec类型、Person类型等值作为函数参数,这偏离了期待。
例如,在double的函数体内需要对泛型T的值i进行加法操作,但只有实现了std::ops::Add Trait的类型才能使用+进行加法操作。因此要限制泛型T是那些实现了std::ops::Add的数据类型。
限制泛型也叫做Trait绑定(Trait Bound),其语法有两种:
- 在定义泛型类型T时,使用类似于
T: Trait_Name这种语法进行限制 - 在返回值后面、大括号前面使用where关键字,如
where T: Trait_Name
因此,下面两种写法是等价的:
#![allow(unused)]
fn main() {
fn f<T: Clone + Copy>(i: T) -> T{}
fn f<T>(i: T) -> T
where T: Clone + Copy {}
// 更复杂的示例:
fn query<M: Mapper + Serialize, R: Reducer + Serialize>(
data: &DataSet, map: M, reduce: R) -> Results
{
...
}
// 此时,下面写法更友好、可读性更高
fn query<M, R>(data: &DataSet, map: M, reduce: R) -> Results
where M: Mapper + Serialize,
R: Reducer + Serialize
{
...
}
}其中,T: Trait_Name表示将泛型T限制为那些实现了Trait_Name Trait的数据类型。因此T: std::ops::Add表示泛型T只能代表那些实现了std::ops::Add Trait的数据类型,比如各种数值类型都实现了Add Trait,因此T可以代表数值类型,而Vec类型没有实现Add Trait,因此T不能代表Vec类型。
观察指定变量数据类型的写法i: i32和限制泛型的写法T: Trait_Name,由此可知,Trait其实是泛型的数据类型,Trait限制了泛型所能代表的类型,正如数据类型限制了变量所能存放的数据。
有时候需要对泛型做多重限制,这时使用+即可。例如T: Add<Output=T>+Copy+Clone,表示限制泛型T只能代表那些同时实现了Add、Copy、Clone这三种Trait的数据类型。
之所以要做多重限制,是因为有时候限制少了,泛型所能代表的类型不够精确或者缺失某种功能。比如,只限制泛型T是实现了std::ops::Add Trait的类型还不够,还要限制它实现了Copy Trait以便函数体内的参数i被转移所有权时会自动进行Copy,但Copy Trait是Clone Trait的子Trait,即Copy依赖于Clone,因此限制泛型T实现Copy的同时,还要限制泛型T同时实现Clone Trait。
简而言之,要对泛型做限制,一方面的原因是函数体内需要某种Trait提供的功能(比如函数体内要对i执行加法操作,需要的是std::ops::Add的功能),另一方面的原因是要让泛型T所能代表的数据类型足够精确化(如果不做任何限制,泛型将能代表任意数据类型)。
泛型的引用类型
如果参数是一个引用,且又使用泛型,则需要使用泛型的引用&T或&mut T。
例如:
#![allow(unused)]
fn main() {
use std::fmt::Display;
fn f<T: Display>(i: &T) {
println!("{}", *i);
}
}零运行开销的泛型:泛型代码膨胀
rustc在编译代码时,会将所有的泛型替换成它所代表的具体数据类型,就像编译期间会将变量名替换成它所代表数据的内存地址一样。
例如,对于下面这个泛型函数:
use std::ops::Add;
fn double_me<T>(i: T) -> T
where T: Add<Output=T> + Clone + Copy {
i + i
}
fn main() {
println!("{}", double_me(3u32));
println!("{}", double_me(3u8));
println!("{}", double_me(3i8));
}在编译期间,rustc会根据调用double_me()时传递的具体数据类型进行替换。上面示例使用了u32、u8和i8三种类型的值传递给泛型参数,那么编译期间,编译器会对应生成三个double_me()函数,它们的参数类型分别是u32、u8和i8。
$ rustc src/main.rs
$ strings main | grep "double_me"
_ZN4main9double_me17h6d861a9e8ab36c42E
_ZN4main9double_me17ha214a9977249a1bfE
_ZN4main9double_me17hbc458c5fab68c203E
由于编译期间,编译器会对泛型类型进行替换,这会导致泛型代码膨胀(code bloat),从一个函数膨胀为零个、一个或多个具体数据类型的函数。有时候这种膨胀会导致编译后的程序文件变大很多。不过,多数情况下,代码膨胀的问题都不是大问题。
另一方面,由于编译期间已经将泛型替换成了具体的数据类型,因此,在程序运行期间,直接调用对应类型的函数即可,不需要再消耗任何额外的资源去计算泛型所代表的具体类型。因此,Rust的泛型是零运行时开销的。
使用泛型的位置
使用泛型的位置
不仅仅是函数的参数可以指定泛型,任何需要指定数据类型的地方,都可以使用泛型来替代具体的数据类型,以此来表示此处可以使用比某种具体类型更为通用的数据类型。
而且,可以同时使用多个泛型,只要将不同的泛型定义为不同的名称即可。例如,HashMap类型是保存键值对的类型,它的key是一种泛型类型,它的值也是一种泛型类型。它的定义如下:
#![allow(unused)]
fn main() {
// 使用了三个泛型,分别是K、V、S,并且泛型S的默认类型是RandomState
struct HashMap<K, V, S = RandomState> {
base: base::HashMap<K, V, S>,
}
}实际上,Struct、Enum、impl、Trait等地方都可以使用泛型,仍然要注意的是,需要在类型的名称后或者impl后先声明泛型,才能使用已声明的泛型。
下面是一些简单的示例。
Struct使用泛型:
#![allow(unused)]
fn main() {
struct Container_tuple<T> (T)
struct Container_named<T: std::fmt::Display> {
field: T,
}
}例如,Vec类型就是泛型的Struct类型,其官方定义如下:
#![allow(unused)]
fn main() {
pub struct Vec<T> {
buf: RawVec<T>,
len: usize,
}
}Enum使用泛型:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}impl实现类型的方法时使用泛型:
#![allow(unused)]
fn main() {
struct Container<T>{
item: T,
}
// impl后的T是声明泛型T
// Container<T>的T对应Struct类型Container<T>
impl<T> Container<T> {
fn new(item: T) -> Self {
Container {item}
}
}
}Trait使用泛型:
#![allow(unused)]
fn main() {
// 表示将某种类型T转换为当前类型
trait From<T> {
fn from(T) -> Self;
}
}某数据类型impl实现Trait时使用泛型:
#![allow(unused)]
fn main() {
use std::fmt::Debug;
trait Eatable {
fn eat_me(&self);
}
#[derive(Debug)]
struct Food<T>(T);
impl<T: Debug> Eatable for Food<T> {
fn eat_me(&self) {
println!("Eating: {:?}", self);
}
}
}注意,上面impl时指定了T: Debug,它表示了Food<T>类型的T必须实现了Debug。为什么不直接在定义Struct时,将Food定义为struct Food<T: Debug>而是在impl Food时才限制泛型T呢?
通常,应当尽量不在定义类型时限制泛型的范围,除非确实有必要去限制。这是因为,泛型本就是为了描述更为抽象、更为通用的类型而存在的,限制泛型将使得类型变得更具体化,适用场景也更窄。但是在impl类型时,应当去限制泛型,并且遵守缺失什么功能就添加什么限制的规范,这样可以使得所定义的方法不会过度泛化,也不会过度具体化。
简单来说,尽量不去限制类型是什么,而是限制类型能做什么。
另一方面,即使定义struct Food<T: Debug>,在impl Food<T>时,也仍然要在impl时指定泛型的限制,否则将编译错误。
#![allow(unused)]
fn main() {
#[derive(Debug)]
struct Food<T: Debug>(T);
impl<T: Debug> Eatable for Food<T> {}
}也就是说,如果某个泛型类型有对应的impl,那么在定义类型时指定的泛型限制很可能是多余的。但如果没有对应的impl,那么可能有必要在定义泛型类型时加上泛型限制。
Trait对象和泛型
Trait对象和泛型
对比一下Trait对象和泛型:
- Trait对象可以被看作一种数据类型,它总是以引用的方式被使用,在运行期间,它在栈中保存了具体类型的实例数据和实现自该Trait的方法。
- 泛型不是一种数据类型,它可被看作是数据类型的参数形式或抽象形式,在编译期间会被替换为具体的数据类型
Trait Objecct方式也称为动态分派(dynamic dispatch),它在程序运行期间动态地决定具体类型。而Rust泛型是静态分派,它在编译期间会代码膨胀,将泛型参数转变为使用到的每种具体类型。
例如,类型Square和类型Rectangle都实现了Trait Area以及方法get_area,现在要创建一个vec,这个vec中包含了任意能够调用get_area方法的类型实例。这种需求建议采用Trait Object方式:
fn main(){
let mut sharps: Vec<&dyn Area> = vec![];
sharps.push(&Square(3.0));
sharps.push(&Rectangle(3.0, 2.0));
println!("{}", sharps[0].get_area());
println!("{}", sharps[1].get_area());
}
trait Area{
fn get_area(&self)->f64;
}
struct Square(f64);
struct Rectangle(f64, f64);
impl Area for Square{
fn get_area(&self) -> f64 {self.0 * self.0}
}
impl Area for Rectangle{
fn get_area(&self) -> f64 {self.0 * self.1}
}在上面的示例中,Vec sharps用于保存多种不同类型的数据,只要能调用get_area方法的数据都能存放在此,而调用get_area方法的能力,来自于Area Trait。因此,使用动态的类型dyn Area来描述所有这类数据。当sharps中任意一个数据要调用get_area方法时,都会从它的vtable中查找该方法,然后调用。
但如果改一下上面示例的需求,不仅要为f64实现上述功能,还要为i32、f32、u8等类型实现上述功能,这时候使用Trait Object就很冗余了,要为每一个数值类型都实现一次。
使用泛型则可以解决这类因数据类型而导致的冗余问题。
fn main(){
let sharps: Vec<Sharp<_>> = vec![
Sharp::Square(3.0_f64),
Sharp::Rectangle(3.0_f64, 2.0_f64),
];
sharps[0].get_area();
}
trait Area<T> {
fn get_area(&self) -> T;
}
enum Sharp<T>{
Square(T),
Rectangle(T, T),
}
impl<T> Area<T> for Sharp<T>
where T: Mul<Output=T> + Clone + Copy
{
fn get_area(&self) -> T {
match *self {
Sharp::Rectangle(a, b) => return a * b,
Sharp::Square(a) => return a * a,
}
}
}上面使用了泛型枚举,在这个枚举类型上实现Area Trait,就可以让泛型枚举统一各种类型,使得这些类型的数据都具有get_area方法。
tokio简介
tokio是Rust中使用最广泛的异步Runtime,它性能高、功能丰富、便于使用,是使用Rust实现高并发不可不学的一个框架。
在正式开始学习tokio之前,当然是在Cargo.toml中引入tokio。在Cargo.toml文件中添加以下依赖:
// 开启全部功能的tokio,
// 在了解tokio之后,只开启需要的特性,减少编译时间,减小编译大小
tokio = {version = "1.4", features = ["full"]}
理解tokio的核心(1): runtime
理解tokio核心(1): runtime
在使用tokio之前,应当先理解tokio的核心概念:runtime和task。只有理解了这两个核心概念,才能正确地、合理地使用tokio。本文先详细介绍runtime这个核心概念,还会介绍一些基本的调度知识,这些都是理解异步理解tokio的必要知识,后面再专门介绍task。
创建tokio Runtime
要使用tokio,需要先创建它提供的异步运行时环境(Runtime),然后在这个Runtime中执行异步任务。
使用tokio::runtime创建Runtime:
use tokio;
fn main() {
// 创建runtime
let rt = tokio::runtime::Runtime::new().unwrap();
}也可以使用Runtime Builder来配置并创建runtime:
use tokio;
fn main() {
// 创建带有线程池的runtime
let rt = tokio::runtime::Builder::new_multi_thread()
.worker_threads(8) // 8个工作线程
.enable_io() // 可在runtime中使用异步IO
.enable_time() // 可在runtime中使用异步计时器(timer)
.build() // 创建runtime
.unwrap();
}tokio提供了两种工作模式的runtime:
- 1.单一线程的runtime(single thread runtime,也称为current thread runtime)
- 2.多线程(线程池)的runtime(multi thread runtime)
注: 这里的所说的线程是Rust线程,而每一个Rust线程都是一个OS线程。
IO并发类任务较多时,单一线程的runtime性能不如多线程的runtime,但因为多线程runtime使用了多线程,使得线程间的通信变得更为复杂,也加重了线程间切换的开销,使得有些情况下的性能不如使用单线程runtime。因此,在要求极限性能的时候,建议测试两种工作模式的性能差距来选择更优解。在后面深入了一些tokio后,我会再花一个小节来解释单一线程的runtime和多线程的runtime的调度区别以及如何选择合适的runtime。
默认情况下(比如以上两种方式),创建出来的runtime都是多线程runtime,且没有指定工作线程数量时,默认的工作线程数量将和CPU核数(虚拟核,即CPU线程数)相同。
只有明确指定,才能创建出单一线程的runtime。例如:
#![allow(unused)]
fn main() {
// 创建单一线程的runtime
let rt = tokio::runtime::Builder::new_current_thread().build().unwrap();
}例如,创建一个多线程的runtime,查看其线程数:
use tokio;
fn main(){
let rt = tokio::runtime::Runtime::new().unwrap();
std::thread::sleep(std::time::Duration::from_secs(10));
}在另一个终端查看线程数:
$ ps -eLf | grep 'targe[t]'
longshu+ 15759 62 15759 6 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15761 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15762 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15763 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15764 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15765 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15766 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15767 0 9 20:42 pts/0 00:00:00 target/debug/async main
longshu+ 15759 62 15768 0 9 20:42 pts/0 00:00:00 target/debug/async main
总共9个OS线程,其中8个worker thread(我的电脑是4核8线程的),外加一个main thread。
async main
对于main函数,tokio提供了简化的异步运行时创建方式:
use tokio;
#[tokio::main]
async fn main() {}通过#[tokio::main]注解(annotation),使得async main自身成为一个async runtime。
#[tokio::main]创建的是多线程runtime,还有以下几种方式创建多线程runtime:
#![allow(unused)]
fn main() {
#[tokio::main(flavor = "multi_thread"] // 等价于#[tokio::main]
#[tokio::main(flavor = "multi_thread", worker_threads = 10))]
#[tokio::main(worker_threads = 10))]
}它们等价于如下没有使用#[tokio::main]的代码:
fn main(){
tokio::runtime::Builder::new_multi_thread()
.worker_threads(N)
.enable_all()
.build()
.unwrap()
.block_on(async { ... });
}#[tokio::main]也可以创建单一线程的main runtime:
#![allow(unused)]
fn main() {
#[tokio::main(flavor = "current_thread")]
}等价于:
fn main() {
tokio::runtime::Builder::new_current_thread()
.enable_all()
.build()
.unwrap()
.block_on(async { ... })
}多个runtime共存
可手动创建线程,并在不同线程内创建互相独立的runtime。
例如:
use std::thread;
use std::time::Duration;
use tokio::runtime::Runtime;
fn main() {
// 在第一个线程内创建一个多线程的runtime
let t1 = thread::spawn(||{
let rt = Runtime::new().unwrap();
thread::sleep(Duration::from_secs(10));
});
// 在第二个线程内创建一个多线程的runtime
let t2 = thread::spawn(||{
let rt = Runtime::new().unwrap();
thread::sleep(Duration::from_secs(10));
});
t1.join().unwrap();
t2.join().unwrap();
}对于4核8线程的电脑,此时总共有19个OS线程:16个worker-thread,2个spawn-thread,一个main-thread。
runtime实现了Send和Sync这两个Trait,因此可以将runtime包在Arc里,然后跨线程使用同一个runtime。
进入runtime: 在异步runtime中执行异步任务
提供了Runtime后,可在Runtime中执行异步任务。
多数时候,异步任务是一些带有网络IO操作的任务,比如异步的http请求。但是介绍tokio用法时,不需要那么复杂,只需使用tokio的异步timer即可解释清楚,如tokio::time::sleep()。
注:
std::time也提供了sleep(),但它会阻塞整个线程,而tokio::time中的sleep()则只是让它所在的任务放弃CPU并进入调度队列等待被唤醒,它不会阻塞任何线程,它所在的线程仍然可被用来执行其它异步任务。因此,在tokio runtime中,应当使用tokio::time中的sleep()。
例如:
use tokio::runtime::Runtime;
use chrono::Local;
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("before sleep: {}", Local::now().format("%F %T.%3f"));
tokio::time::sleep(tokio::time::Duration::from_secs(2)).await;
println!("after sleep: {}", Local::now().format("%F %T.%3f"));
});
}输出:
before sleep: 2021-10-24 11:53:38.496
after sleep: 2021-10-24 11:53:40.497
上面调用了runtime的block_on()方法,block_on要求一个Future作为参数,可以像上面一样直接使用一个async {}来定义一个Future。每一个Future都是一个已经定义好但尚未执行的异步任务,每一个异步任务中可能会包含其它子任务。
这些异步任务不会直接执行,需要先将它们放入到runtime环境,然后在合适的地方通过Future的await来执行它们。await可以将已经定义好的异步任务立即加入到runtime的任务队列中等待调度执行,于此同时,await会等待该异步任务完成才返回。例如:
#![allow(unused)]
fn main() {
rt.block_on(async {
// 只是定义了Future,此时尚未执行
let task = tokio::time::sleep(tokio::time::Duration::from_secs(2));
// ...不会执行...
// ...
// 开始执行task任务,并等待它执行完成
task.await;
// 上面的任务完成之后,才会继续执行下面的代码
});
}block_on会阻塞当前线程(例如阻塞住上面的main函数所在的主线程),直到其指定的**异步任务树(可能有子任务)**全部完成。
注:block_on是等待异步任务完成,而不是等待runtime中的所有任务都完成,后面介绍blocking thread时会再次说明block_on的阻塞问题。
block_on也有返回值,其返回值为其所执行异步任务的返回值。例如:
use tokio::{time, runtime::Runtime};
fn main() {
let rt = Runtime::new().unwrap();
let res: i32 = rt.block_on(async{
time::sleep(time::Duration::from_secs(2)).await;
3
});
println!("{}", res); // 3
}spawn: 向runtime中添加新的异步任务
在上面的例子中,直接将async {}作为block_on()的参数,这个async {}本质上是一个Future,即一个异步任务。在这个最外层的异步任务内部,还可以创建新的异步任务,它们都将在同一个runtime中执行。
有时候,定义要执行的异步任务时,并未身处runtime内部。例如定义一个异步函数,此时可以使用tokio::spawn()来生成异步任务。
use std::thread;
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
// 在runtime外部定义一个异步任务,且该函数返回值不是Future类型
fn async_task() {
println!("create an async task: {}", now());
tokio::spawn(async {
time::sleep(time::Duration::from_secs(10)).await;
println!("async task over: {}", now());
});
}
fn main() {
let rt1 = Runtime::new().unwrap();
rt1.block_on(async {
// 调用函数,该函数内创建了一个异步任务,将在当前runtime内执行
async_task();
});
}除了tokio::spawn(),runtime自身也能spawn,因此,也可以传递runtime(注意,要传递runtime的引用),然后使用runtime的spawn()。
use tokio::{Runtime, time}
fn async_task(rt: &Runtime) {
rt.spawn(async {
time::sleep(time::Duration::from_secs(10)).await;
});
}
fn main(){
let rt = Runtime::new().unwrap();
rt.block_on(async {
async_task(&rt);
});
}进入runtime: 非阻塞的enter()
block_on()是进入runtime的主要方式。但还有另一种进入runtime的方式:enter()。
block_on()进入runtime时,会阻塞当前线程,enter()进入runtime时,不会阻塞当前线程,它会返回一个EnterGuard。EnterGuard没有其它作用,它仅仅只是声明从它开始的所有异步任务都将在runtime上下文中执行,直到删除该EnterGuard。
删除EnterGuard并不会删除runtime,只是释放之前的runtime上下文声明。因此,删除EnterGuard之后,可以声明另一个EnterGuard,这可以再次进入runtime的上下文环境。
use tokio::{self, runtime::Runtime, time};
use chrono::Local;
use std::thread;
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
// 进入runtime,但不阻塞当前线程
let guard1 = rt.enter();
// 生成的异步任务将放入当前的runtime上下文中执行
tokio::spawn(async {
time::sleep(time::Duration::from_secs(5)).await;
println!("task1 sleep over: {}", now());
});
// 释放runtime上下文,这并不会删除runtime
drop(guard1);
// 可以再次进入runtime
let guard2 = rt.enter();
tokio::spawn(async {
time::sleep(time::Duration::from_secs(4)).await;
println!("task2 sleep over: {}", now());
});
drop(guard2);
// 阻塞当前线程,等待异步任务的完成
thread::sleep(std::time::Duration::from_secs(10));
}理解runtime和异步调度
异步Runtime提供了异步IO驱动、异步计时器等异步API,还提供了任务的调度器(scheduler)和Reactor事件循环(Event Loop)。
每当创建一个Runtime时,就在这个Runtime中创建好了一个Reactor和一个Scheduler,同时还创建了一个任务队列。
从这一点看来,异步运行时和操作系统的进程调度方式是类似的,只不过现代操作系统的进程调度逻辑要比异步运行时的调度逻辑复杂的多。
当一个异步任务需要运行,这个任务要被放入到可运行的任务队列(就绪队列),然后等待被调度,当一个异步任务需要阻塞时(对应那些在同步环境下会阻塞的操作),它被放进阻塞队列。
阻塞队列中的每一个被阻塞的任务,都需要等待Reactor收到对应的事件通知(比如IO完成的通知、睡眠完成的通知等)来唤醒它。当该任务被唤醒后,它将被放入就绪队列,等待调度器的调度。
就绪队列中的每一个任务都是可运行的任务,可随时被调度器调度选中。调度时会选择哪一个任务,是调度器根据调度算法去决定的。某个任务被调度选中后,调度器将分配一个线程去执行该任务。
大方向上来说,有两种调度策略:抢占式调度和协作式调度。抢占式调度策略,调度器会在合适的时候(调度规则决定什么是合适的时候)强行切换当前正在执行的调度单元(例如进程、线程),避免某个任务长时间霸占CPU从而导致其它任务出现饥饿。协作式调度策略则不会强行切断当前正在执行的单元,只有执行单元执行完任务或主动放弃CPU,才会将该执行单元重新排队等待下次调度,这可能会导致某个长时间计算的任务霸占CPU,但是可以让任务充分执行尽早完成,而不会被中断。
对于面向大众使用的操作系统(如Linux)通常采用抢占式调度策略来保证系统安全,避免恶意程序霸占CPU。而对于语言层面来说,通常采用协作式调度策略,这样既有底层OS的抢占式保底,又有协作式的高效。tokio的调度策略是协作式调度策略。
也可以简单粗暴地去理解异步调度:任务刚出生时,放进任务队列尾部,调度器总是从任务队列的头部选择任务去执行,执行任务时,如果任务有阻塞操作,则该任务总是会被放入到任务队列的尾部。如果任务队列的第一个任务都是阻塞的(即任务之前被阻塞但目前尚未完成),则调度器直接将它重新放回队列的尾部。因此,调度器总是从前向后一次又一次地轮询这个任务队列。当然,调度算法通常会比这种简单的方式要复杂的多,它可能会采用多个任务队列,多种挑选标准,且队列不是简单的队列,而是更高效的数据结构。
以上是通用知识,用于理解何为异步调度系统,每个调度系统都有自己的特性。例如,Rust tokio并不完全按照上面所描述的方式进行调度。tokio的作者,非常友好地提供了一篇他实现tokio调度器的思路,里面详细介绍了调度器的基本知识和tokio调度器的调度策略,参考Making the Tokio scheduler 10x faster。
tokio的两种线程:worker thread和blocking thread
需要注意,tokio提供了两种功能的线程:
- 用于异步任务的工作线程(worker thread)
- 用于同步任务的阻塞线程(blocking thread)
单个线程或多个线程的runtime,指的都是工作线程,即只用于执行异步任务的线程,这些任务主要是IO密集型的任务。tokio默认会将每一个工作线程均匀地绑定到每一个CPU核心上。
但是,有些必要的任务可能会长时间计算而占用线程,甚至任务可能是同步的,它会直接阻塞整个线程(比如thread::time::sleep()),这类任务如果计算时间或阻塞时间较短,勉强可以考虑留在异步队列中,但如果任务计算时间或阻塞时间可能会较长,它们将不适合放在异步队列中,因为它们会破坏异步调度,使得同线程中的其它异步任务处于长时间等待状态,也就是说,这些异步任务可能会被饿很长一段时间。
例如,直接在runtime中执行阻塞线程的操作,由于这类阻塞操作不在tokio系统内,tokio无法识别这类线程阻塞的操作,tokio只能等待该线程阻塞操作的结束,才能重新获得那个线程的管理权。换句话说,worker thread被线程阻塞的时候,它已经脱离了tokio的控制,在一定程度上破坏了tokio的调度系统。
#![allow(unused)]
fn main() {
rt.block_on(async{
// 在runtime中,让整个线程进入睡眠,注意不是tokio::time::sleep()
std::thread::sleep(std::time::Duration::from_secs(10));
});
}因此,tokio提供了这两类不同的线程。worker thread只用于执行那些异步任务,异步任务指的是不会阻塞线程的任务。而一旦遇到本该阻塞但却不会阻塞的操作(如使用tokio::time::sleep()而不是std::thread::sleep()),会直接放弃CPU,将线程交还给调度器,使该线程能够再次被调度器分配到其它异步任务。blocking thread则用于那些长时间计算的或阻塞整个线程的任务。
blocking thread默认是不存在的,只有在调用了spawn_blocking()时才会创建一个对应的blocking thread。
blocking thread不用于执行异步任务,因此runtime不会去调度管理这类线程,它们在本质上相当于一个独立的thread::spawn()创建的线程,它也不会像block_on()一样会阻塞当前线程。它和独立线程的唯一区别,是blocking thread是在runtime内的,可以在runtime内对它们使用一些异步操作,例如await。
use std::thread;
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt1 = Runtime::new().unwrap();
// 创建一个blocking thread,可立即执行(由操作系统调度系统决定何时执行)
// 注意,不阻塞当前线程
let task = rt1.spawn_blocking(|| {
println!("in task: {}", now());
// 注意,是线程的睡眠,不是tokio的睡眠,因此会阻塞整个线程
thread::sleep(std::time::Duration::from_secs(10))
});
// 小睡1毫秒,让上面的blocking thread先运行起来
std::thread::sleep(std::time::Duration::from_millis(1));
println!("not blocking: {}", now());
// 可在runtime内等待blocking_thread的完成
rt1.block_on(async {
task.await.unwrap();
println!("after blocking task: {}", now());
});
}输出:
in task: 2021-10-25 19:01:00
not blocking: 2021-10-25 19:01:00
after blocking task: 2021-10-25 19:01:10
需注意,blocking thread生成的任务虽然绑定了runtime,但是它不是异步任务,不受tokio调度系统控制。因此,如果在block_on()中生成了blocking thread或普通的线程,block_on()不会等待这些线程的完成。
#![allow(unused)]
fn main() {
rt.block_on(async{
// 生成一个blocking thread和一个独立的thread
// block on不会阻塞等待两个线程终止,因此block_on在这里会立即返回
rt.spawn_blocking(|| std::thread::sleep(std::time::Duration::from_secs(10)));
thread::spawn(||std::thread::sleep(std::time::Duration::from_secs(10)));
});
}tokio允许的blocking thread队列很长(默认512个),且可以在runtime build时通过max_blocking_threads()配置最大长度。如果超出了最大队列长度,新的任务将放在一个等待队列中进行等待(比如当前已经有512个正在运行的任务,下一个任务将等待,直到有某个blocking thread空闲)。
blocking thread执行完对应任务后,并不会立即释放,而是继续保持活动状态一段时间,此时它们的状态是空闲状态。当空闲时长超出一定时间后(可在runtime build时通过thread_keep_alive()配置空闲的超时时长),该空闲线程将被释放。
blocking thread有时候是非常友好的,它像独立线程一样,但又和runtime绑定,它不受tokio的调度系统调度,tokio不会把其它任务放进该线程,也不会把该线程内的任务转移到其它线程。换言之,它有机会完完整整地发挥单个线程的全部能力,而不像worker线程一样,可能会被调度器打断。
关闭Runtime
由于异步任务完全依赖于Runtime,而Runtime又是程序的一部分,它可以轻易地被删除(drop),这时Runtime会被关闭(shutdown)。
#![allow(unused)]
fn main() {
let rt = Runtime::new().unwrap();
...
drop(rt);
}这里的变量rt,官方手册将其称为runtime的句柄(runtime handle)。
关闭Runtime时,将使得该Runtime中的所有异步任务被移除。完整的关闭过程如下:
- 1.先移除整个任务队列,保证不再产生也不再调度新任务
- 2.移除当前正在执行但尚未完成的异步任务,即终止所有的worker thread
- 3.移除Reactor,禁止接收事件通知
注意,这种删除runtime句柄的方式只会立即关闭未被阻塞的worker thread,那些已经运行起来的blocking thread以及已经阻塞整个线程的worker thread仍然会执行。但是,删除runtime又要等待runtime中的所有异步和非异步任务(会阻塞线程的任务)都完成,因此删除操作会阻塞当前线程。
use std::thread;
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
// 一个运行5秒的blocking thread
// 删除rt时,该任务将继续运行,直到自己终止
rt.spawn_blocking(|| {
thread::sleep(std::time::Duration::from_secs(5));
println!("blocking thread task over: {}", now());
});
// 进入runtime,并生成一个运行3秒的异步任务,
// 删除rt时,该任务直接被终止
let _guard = rt.enter();
rt.spawn(async {
time::sleep(time::Duration::from_secs(3)).await;
println!("worker thread task over 1: {}", now());
});
// 进入runtime,并生成一个运行4秒的阻塞整个线程的任务
// 删除rt时,该任务继续运行,直到自己终止
rt.spawn(async {
std::thread::sleep(std::time::Duration::from_secs(4));
println!("worker thread task over 2: {}", now());
});
// 先让所有任务运行起来
std::thread::sleep(std::time::Duration::from_millis(3));
// 删除runtime句柄,将直接移除那个3秒的异步任务,
// 且阻塞5秒,直到所有已经阻塞的thread完成
drop(rt);
println!("runtime droped: {}", now());
}输出结果(注意结果中没有异步任务中println!()输出的内容):
worker thread task over 2: 2021-10-25 20:08:35
blocking thread task over: 2021-10-25 20:08:36
runtime droped: 2021-10-25 20:08:36
关闭runtime可能会被阻塞,因此,如果是在某个runtime中关闭另一个runtime,将会导致当前的runtime的某个worker thread被阻塞,甚至可能会阻塞很长时间,这是异步环境不允许的。
tokio提供了另外两个关闭runtime的方式:shutdown_timeout()和shutdown_background()。前者会等待指定的时间,如果正在超时时间内还未完成关闭,将强行终止runtime中的所有线程。后者是立即强行关闭runtime。
use std::thread;
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.spawn_blocking(|| {
thread::sleep(std::time::Duration::from_secs(5));
println!("blocking thread task over: {}", now());
});
let _guard = rt.enter();
rt.spawn(async {
time::sleep(time::Duration::from_secs(3)).await;
println!("worker thread task over 1: {}", now());
});
rt.spawn(async {
std::thread::sleep(std::time::Duration::from_secs(4));
println!("worker thread task over 2: {}", now());
});
// 先让所有任务运行起来
std::thread::sleep(std::time::Duration::from_millis(3));
// 1秒后强行关闭Runtime
rt.shutdown_timeout(std::time::Duration::from_secs(1));
println!("runtime droped: {}", now());
}输出:
runtime droped: 2021-10-25 20:16:02
需要注意的是,强行关闭Runtime,可能会使得尚未完成的任务的资源泄露。因此,应小心使用强行关闭Runtime的操作。
runtime Handle
tokio提供了一个称为runtime Handle的东西,它实际上是runtime的一个引用,可以随意被clone。它可以spawn()生成异步任务,这些异步任务将绑定在其所引用的runtime中,还可以block_on()或enter()进入其所引用的runtime,此外,还可以生成blocking thread。
#![allow(unused)]
fn main() {
let rt = Runtime::new().unwrap();
let handle = rt.handle();
handle.spawn(...)
handle.spawn_blocking(...)
handle.block_on(...)
handle.enter()
}需注意,如果runtime已被关闭,handle也将失效,此后再使用handle,将panic。
理解多进程、多线程、多协程的并发能力
大家都说,多进程效率不如多线程,多线程效率又不如多协程。但这里面并不是如此简单的一句话就能描述准确的,还需要理解其中的真相。
如果有很多IO任务要执行,为了让这些IO操作不阻塞程序,可以使用多进程的方式将这些IO操作丢到【后台】去等待,然后通过各种进程间通信的方式来传递数据。但是进程间的上下文切换会带来较大的开销。因此,当程序使用多进程方式,且工作进程数量较多时,因为不断地进行进程间切换和内存拷贝,效率会明显下降。
比多进程更好一些的是多线程方式,线程是进程内部的执行单元,线程间的上下文切换的开销要远小于进程间切换的开销。因此,大概可以认为,多线程要优于多进程,如果单个进程内的线程数量较多,可以考虑引入多进程,然后在某些进程内使用多线程。
比多线程更好一些的是多协程方式,协程是线程内部的执行单元,协程的上下文切换开销,又要远小于线程间切换的开销。因此,大概可以认为,多协程要优于多线程,如果单个线程内的协程数量较多,可以考虑引入多线程,然后在某些线程内使用多协程。
但是,多进程效率并不真的差,多线程的效率也并不真的比多协程效率差。高并发能力的高低,完全取决于程序是否出现了等待、是否浪费了可调度单元(即进程、线程、协程)、是否浪费了更多的CPU。
一个简单的例子,假如要发送10W个HTTP请求,用多协程是最好的。为什么呢?因为HTTP请求是一个非常简单的IO任务,它只需要发送请求,然后等待。如果用多线程的并发模式,每个线程负责发送一个HTTP请求,那么每一个线程都将长时间处于等待状态,什么也不做,这是对线程的浪费,加之线程数量太多,在这么多的线程之间进行切换也会浪费大量CPU。因此,在这种情况下,多协程优于多线程。
另一方面,如果是要计算10W个密钥,应当去使用一定数量的多进程或多线程(少于或等于CPU核数),以保证能尽量多地利用多核CPU。用多协程可能会很不好,因为协程调度会打断计算进度,当然这取决于协程调度器的调度逻辑。
从这两个简单又极端的示例可以大概理解,如果要执行的任务越简单(这里的简单表示的是计算密集程度低),越IO密集,越应该使用粒度更小的可调度单元(即协程)。计算任务越重,越应该利用多核CPU。
更多时候,一个任务里会同时带有IO和计算,无法简单地判断它是IO密集还是CPU密集的任务。这时候需要进行测试。
选择单一线程runtime还是多线程runtime?
tokio提供了单一线程的runtime和多线程的runtime,虽然官方文档里时不时地提到【多数时候是多线程的runtime】,但并不意味着多线程的runtime优于单一线程的runtime,这取决于异步任务的工作类型。
简单来说,每一个异步任务都是一个线程内的【协程】,单一线程的runtime是在单个线程内调度管理这些任务,多线程runtime则是在多个线程内不断地分配和跨线程传递这些任务。
单一线程的runtime的优势在于它的任务调度开销低,因为它不需要进行开销更重的线程间切换,更不需要不断地在线程间传递数据。因此,对于计算程度不重的需求,它的高并发性能会很好。
单一线程的runtime的劣势在于这个runtime只能利用单核CPU,它无法利用多核CPU,也就无法发挥多核CPU的优势。
注:也可以认为,单一线程的runtime,和Python、Ruby等语言的并发是类似的,都是充分利用单核CPU。但却比它们更高效一些,一方面是语言本身的性能,另一方面是tokio的worker thread都是绑定CPU的,不会在不同的CPU核心之间进行切换,降低了切换开销。
但是,可以手动在多个线程内创建互相独立的单一线程runtime,这样也可以利用多核CPU。
use tokio;
use std::thread;
fn main(){
let t1 = thread::spawn(||{
let rt = tokio::runtime::Builder::new().new_current_thread()
.enable_all()
.build()
.unwrap();
rt.block_on(...)
});
let t2 = thread::spawn(||{
let rt = tokio::runtime::Builder::new().new_current_thread()
.enable_all()
.build()
.unwrap();
rt.block_on(...)
});
t1.join().unwrap();
t2.join().unwrap();
}这种手动创建多个单线程runtime的方式,可以利用多核CPU,但是这几个线程是不受控制的,完全由操作系统决定如何调度它们。这种方式是多线程runtime的雏形。它和多线程runtime的区别在于,多线程runtime会调度管理这些线程,会尽量以高效的方式来分配任务(比如从其它线程中偷任务)。但是有了多线程,就有了额外的切换开销,就有了CPU利用率的浪费。
因此,可以这样认为,单线程runtime对单个线程(单核CPU)的利用率,是高于多线程runtime的。
如果并发任务不重,单核CPU都无法跑满,显然单线程runtime要更优。如果并发任务中有较重的计算任务,则还需要再测试何种方式更优。
理解tokio的核心(2): task
理解tokio核心(2): task
本篇是介绍tokio核心的第二篇,理解tokio中的task。
何为tokio task?
tokio官方手册tokio::task中用了一句话介绍task:Asynchronous green-threads(异步的绿色线程)。
Rust中的原生线程(std::thread)是OS线程,每一个原生线程,都对应一个操作系统的线程。操作系统线程在内核层,由操作系统负责调度,缺点是涉及相关的系统调用,它有更重的线程上下文切换开销。
green thread则是用户空间的线程,由程序自身提供的调度器负责调度,由于不涉及系统调用,同一个OS线程内的多个绿色线程之间的上下文切换的开销非常小,因此非常的轻量级。可以认为,它们就是一种特殊的协程。
解释了何为绿色线程后,回到tokio的task概念。什么是task呢?
每定义一个Future(例如一个async语句块就是一个Future),就定义了一个静止的尚未执行的task,当它在runtime中开始运行的时候,它就是真正的task,一个真正的异步任务。
要注意,在tokio runtime中执行的并不都是异步任务,绑定在runtime中的可能是同步任务(例如一个数值计算就是一个同步任务,只是速度非常快,可忽略不计),可能会长时间计算,可能会阻塞整个线程,这一点在前一篇介绍runtime时详细说明过。tokio严格区分异步任务和同步任务,只有异步任务才算是tokio task。tokio推荐的做法是将同步任务放入blocking thread中运行。
从官方手册将task描述为绿色线程也能理解,tokio::task只能是完全受tokio调度管理的异步任务,而不是脱离tokio调度控制的同步任务。
tokio::task
tokio::task模块本身提供了几个函数:
- spawn:向runtime中添加新异步任务
- spawn_blocking:生成一个blocking thread并执行指定的任务
- block_in_place:在某个worker thread中执行同步任务,但是会将同线程中的其它异步任务转移走,使得异步任务不会被同步任务饥饿
- yield_now: 立即放弃CPU,将线程交还给调度器,自己则进入就绪队列等待下一轮的调度
- unconstrained: 将指定的异步任务声明未不受限的异步任务,它将不受tokio的协作式调度,它将一直霸占当前线程直到任务完成,不会受到tokio调度器的管理
- spawn_local: 生成一个在当前线程内运行,一定不会被偷到其它线程中运行的异步任务
这里的三个spawn类的方法都返回JoinHandle类型,JoinHandle类型可以通过await来等待异步任务的完成,也可以通过abort()来中断异步任务,异步任务被中断后返回JoinError类型。
task::spawn()
这个很简单,就是直接在当前的runtime中生成一个异步任务。
use chrono::Local;
use std::thread;
use tokio::{self, task, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
let _guard = rt.enter();
task::spawn(async {
time::sleep(time::Duration::from_secs(3)).await;
println!("task over: {}", now());
});
thread::sleep(time::Duration::from_secs(4));
}task::spawn_blocking()
生成一个blocking thread来执行指定的任务。在前一篇介绍runtime的文章中已经解释清楚,这里不再解释。
#![allow(unused)]
fn main() {
let join = task::spawn_blocking(|| {
// do some compute-heavy work or call synchronous code
"blocking completed"
});
let result = join.await?;
assert_eq!(result, "blocking completed");
}task::block_in_place()
block_in_place()的目的和spawn_blocking()类似。区别在于spawn_blocking()会新生成一个blocking thread来执行指定的任务,而block_in_place()是在当前worker thread中执行指定的可能会长时间运行或长时间阻塞线程的任务,但是它会先将该worker thread中已经存在的异步任务转移到其它worker thread,使得这些异步任务不会被饥饿。
显然,block_in_place()只应该在多线程runtime环境中运行,如果是单线程runtime,block_in_place会阻塞唯一的那个worker thread。
#![allow(unused)]
fn main() {
use tokio::task;
task::block_in_place(move || {
// do some compute-heavy work or call synchronous code
});
}在block_in_place内部,可以使用block_on()或enter()重新进入runtime环境。
#![allow(unused)]
fn main() {
use tokio::task;
use tokio::runtime::Handle;
task::block_in_place(move || {
Handle::current().block_on(async move {
// do something async
});
});
}task::yield_now
让当前任务立即放弃CPU,将worker thread交还给调度器,任务自身则进入调度器的就绪队列等待下次被轮询调度。类似于其它异步系统中的next_tick行为。
需注意,调用yield_now()后还需await才立即放弃CPU,因为yield_now本身是一个异步任务。
#![allow(unused)]
fn main() {
use tokio::task;
async {
task::spawn(async {
// ...
println!("spawned task done!")
});
// Yield, allowing the newly-spawned task to execute first.
task::yield_now().await;
println!("main task done!");
}
}注意,yield后,任务调度的顺序是未知的。有可能任务在发出yield后,紧跟着的下一轮调度会再次调度该任务。
task::unconstrained()
tokio的异步任务都是受tokio调度控制的,tokio采用协作式调度策略来调度它所管理的异步任务。当异步任务中的执行到了某个本该阻塞的操作时(即使用了tokio提供的那些原本会阻塞的API,例如tokio版本的sleep()),将不会阻塞当前线程,而是进入等待队列,等待Reactor接收事件通知来唤醒该异步任务,这样当前线程会被释放给调度器,使得调度器能够继续分配其它异步任务到该线程上执行。
task::unconstrained()则是创建一个不受限制不受调度器管理的异步任务,它将不会参与调度器的协作式调度,可以认为是将这个异步任务暂时脱离了调度管理。这样一来,即便该任务中遇到了本该阻塞而放弃线程的操作,也不会去放弃,而是直接阻塞该线程。
因此,unconstrained()创建的异步任务将会使得同线程的其它异步任务被饥饿。如果确实有这样的需求,建议使用block_in_place()或spawn_blocking()。
task::spawn_local()
关于spawn_local(),后面介绍LocalSet的时候再一起介绍。
取消任务abort()
正在执行的异步任务可以随时被abort()取消,取消之后的任务返回JoinError类型。
use tokio::{self, runtime::Runtime, time};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let task = tokio::task::spawn(async {
time::sleep(time::Duration::from_secs(10)).await;
});
// 让上面的异步任务跑起来
time::sleep(time::Duration::from_millis(1)).await;
task.abort(); // 取消任务
// 取消任务之后,可以取得JoinError
let abort_err: JoinError = task.await.unwrap_err();
println!("{}", abort_err.is_cancelled());
})
}如果异步任务已经完成,再对该任务执行abort()操作将没有任何效果。也就是说,没有JoinError,task.await.unwrap_err()将报错,而task.await.unwrap()则正常。
tokio::join!宏和tokio::try_join!宏
可以使用await去等待某个异步任务的完成,无论这个异步任务是正常完成还是被取消。
tokio提供了两个宏tokio::join!和tokio::try_join!。它们可以用于等待多个异步任务全部完成:
join!必须等待所有任务完成try_join!要么等待所有异步任务正常完成,要么等待第一个返回Result Err的任务出现
另外,这两个宏都需要Future参数,它们将提供的各参数代表的任务封装成为一个大的task。
例如:
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
async fn do_one() {
println!("doing one: {}", now());
time::sleep(time::Duration::from_secs(2)).await;
println!("do one done: {}", now());
}
async fn do_two() {
println!("doing two: {}", now());
time::sleep(time::Duration::from_secs(1)).await;
println!("do two done: {}", now());
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
tokio::join!(do_one(), do_two());// 等待两个任务均完成,才继续向下执行代码
println!("all done: {}", now());
});
}输出:
doing one: 2021-11-02 16:51:36
doing two: 2021-11-02 16:51:36
do two done: 2021-11-02 16:51:37
do one done: 2021-11-02 16:51:38
all done: 2021-11-02 16:51:38
下面是官方文档中try_join!的示例:
async fn do_stuff_async() -> Result<(), &'static str> {
// async work
}
async fn more_async_work() -> Result<(), &'static str> {
// more here
}
#[tokio::main]
async fn main() {
let res = tokio::try_join!(do_stuff_async(), more_async_work());
match res {
Ok((first, second)) => {
// do something with the values
}
Err(err) => {
println!("processing failed; error = {}", err);
}
}
}固定在线程内的本地异步任务: tokio::task::LocalSet
当使用多线程runtime时,tokio会协作式调度它管理的所有worker thread上的所有异步任务。例如某个worker thread空闲后可能会从其它worker thread中偷取一些异步任务来执行,或者tokio会主动将某些异步任务转移到不同的线程上执行。这意味着,异步任务可能会不受预料地被跨线程执行。
有时候并不想要跨线程执行。例如,那些没有实现Send的异步任务,它们不能跨线程,只能在一个固定的线程上执行。
tokio提供了让某些任务固定在某一个线程中运行的功能,叫做LocalSet,这些异步任务被放在一个独立的本地任务队列中,它们不会跨线程执行。
要使用tokio::task::LocalSet,需使用LocalSet::new()先创建好一个LocalSet实例,它将生成一个独立的任务队列用来存放本地异步任务。
之后,便可以使用LocalSet的spawn_local()向该队列中添加异步任务。但是,添加的异步任务不会直接执行,只有对LocalSet调用await或调用LocalSet::run_until()或LocalSet::block_on()的时候,才会开始运行本地队列中的异步任务。调用后两个方法会进入LocalSet的上下文环境。
例如,使用await来运行本地异步任务。
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
let local_tasks = tokio::task::LocalSet::new();
// 向本地任务队列中添加新的异步任务,但现在不会执行
local_tasks.spawn_local(async {
println!("local task1");
time::sleep(time::Duration::from_secs(5)).await;
println!("local task1 done");
});
local_tasks.spawn_local(async {
println!("local task2");
time::sleep(time::Duration::from_secs(5)).await;
println!("local task2 done");
});
println!("before local tasks running: {}", now());
rt.block_on(async {
// 开始执行本地任务队列中的所有异步任务,并等待它们全部完成
local_tasks.await;
});
}除了LocalSet::spawn_local()可以生成新的本地异步任务,tokio::task::spawn_local()也可以生成新的本地异步任务,但是它的使用有个限制,必须在LocalSet上下文内部才能调用。
例如:
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
let local_tasks = tokio::task::LocalSet::new();
local_tasks.spawn_local(async {
println!("local task1");
time::sleep(time::Duration::from_secs(2)).await;
println!("local task1 done");
});
local_tasks.spawn_local(async {
println!("local task2");
time::sleep(time::Duration::from_secs(3)).await;
println!("local task2 done");
});
println!("before local tasks running: {}", now());
// LocalSet::block_on进入LocalSet上下文
local_tasks.block_on(&rt, async {
tokio::task::spawn_local(async {
println!("local task3");
time::sleep(time::Duration::from_secs(4)).await;
println!("local task3 done");
}).await.unwrap();
});
println!("all local tasks done: {}", now());
}需要注意的是,调用LocalSet::block_on()和LocalSet::run_until()时均需指定一个异步任务(Future)作为其参数,它们都会立即开始执行该异步任务以及本地任务队列中已存在的任务,但是这两个函数均只等待其参数对应的异步任务执行完成就返回。这意味着,它们返回的时候,可能还有正在执行中的本地异步任务,它们会继续保留在本地任务队列中。当再次进入LocalSet上下文或await
LocalSet的时候,它们会等待调度并运行。
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
let local_tasks = tokio::task::LocalSet::new();
local_tasks.spawn_local(async {
println!("local task1");
time::sleep(time::Duration::from_secs(2)).await;
println!("local task1 done {}", now());
});
// task2要睡眠10秒,它将被第一次local_tasks.block_on在3秒后中断
local_tasks.spawn_local(async {
println!("local task2");
time::sleep(time::Duration::from_secs(10)).await;
println!("local task2 done, {}", now());
});
println!("before local tasks running: {}", now());
local_tasks.block_on(&rt, async {
tokio::task::spawn_local(async {
println!("local task3");
time::sleep(time::Duration::from_secs(3)).await;
println!("local task3 done: {}", now());
}).await.unwrap();
});
// 线程阻塞15秒,此时task2睡眠10秒的时间已经过去了,
// 当再次进入LocalSet时,task2将可以直接被唤醒
thread::sleep(std::time::Duration::from_secs(15));
// 再次进入LocalSet
local_tasks.block_on(&rt, async {
// 先执行该任务,当遇到睡眠1秒的任务时,将出现任务切换,
// 此时,调度器将调度task2,而此时task2已经睡眠完成
println!("re enter localset context: {}", now());
time::sleep(time::Duration::from_secs(1)).await;
println!("re enter localset context done: {}", now());
});
println!("all local tasks done: {}", now());
}输出结果:
#![allow(unused)]
fn main() {
before local tasks running: 2021-10-26 20:19:11
local task1
local task3
local task2
local task1 done 2021-10-26 20:19:13
local task3 done: 2021-10-26 20:19:14
re enter localset context: 2021-10-26 20:19:29
local task2 done, 2021-10-26 20:19:29
re enter localset context done: 2021-10-26 20:19:30
all local tasks done: 2021-10-26 20:19:30
}需要注意的是,再次运行本地异步任务时,之前被中断的异步任务所等待的事件可能已经出现了,因此它们可能会被直接唤醒重新进入就绪队列等待下次轮询调度。正如上面需要睡眠10秒的task2,它会被第一次block_on中断,虽然task2已经不再执行,但是15秒之后它的睡眠完成事件已经出现,它可以在下次调度本地任务时直接被唤醒。但注意,唤醒的任务不是直接就可以被执行的,而是放入就绪队列等待调度。
这意味着,再次进入上下文时,所指定的Future中必须至少存在一个会引起调度切换的任务,否则该Future以同步的方式运行直到结束都不会给已经被唤醒的任务任何执行的机会。
例如,将上面示例中的第二个block_on中的Future参数换成下面的async代码块,task2将不会被调度执行:
#![allow(unused)]
fn main() {
local_tasks.block_on(&rt, async {
println!("re-enter localset context, and exit context");
println!("task2 will not be scheduled");
})
}下面是使用run_until()两次进入LocalSet上下文的示例,和block_on()类似,区别仅在于它只能在Runtime::block_on()内或[tokio::main]注解的main函数内部被调用。
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
let local_tasks = tokio::task::LocalSet::new();
local_tasks.spawn_local(async {
println!("local task1");
time::sleep(time::Duration::from_secs(5)).await;
println!("local task1 done {}", now());
});
println!("before local tasks running: {}", now());
rt.block_on(async {
local_tasks
.run_until(async {
println!("local task2");
time::sleep(time::Duration::from_secs(3)).await;
println!("local task2 done: {}", now());
})
.await;
});
thread::sleep(std::time::Duration::from_secs(10));
rt.block_on(async {
local_tasks
.run_until(async {
println!("local task3");
tokio::task::yield_now().await;
println!("local task3 done: {}", now());
})
.await;
});
println!("all local tasks done: {}", now());
}输出结果:
before local tasks running: 2021-10-26 21:23:18
local task2
local task1
local task2 done: 2021-10-26 21:23:21
local task3
local task1 done 2021-10-26 21:23:31
local task3 done: 2021-10-26 21:23:31
all local tasks done: 2021-10-26 21:23:31
tokio::select!宏
在Golang中有一个select关键字,tokio中则类似地提供了一个名为select!的宏。tokio::select!宏使用场景非常普遍,因此有必要理解该宏的工作流程。
select!宏的作用是轮询指定的多个异步任务,每个异步任务都是select!的一个分支,当某个分支已完成,则执行该分支对应的代码,同时取消其它分支。简单来说,select!的作用是等待第一个完成的异步任务并执行对应任务完成后的操作。
它的使用语法参考如下:
#![allow(unused)]
fn main() {
tokio::select! {
<pattern1> = <async expression 1> (, if <precondition1>)? => <handler1>, // branch 1
<pattern2> = <async expression 2> (, if <precondition2>)? => <handler2>, // branch 2
...
(else => <handler_else>)?
};
}else分支是可选的,每个分支的if前置条件是可选的。因此,简化的语法为:
#![allow(unused)]
fn main() {
tokio::select! {
<pattern1> = <async expression 1> => <handler1>, // branch 1
<pattern2> = <async expression 2> => <handler2>, // branch 2
...
};
}即,每个分支都有一个异步任务,并对异步任务完成后的返回结果进行模式匹配,如果匹配成功,则执行对应的handler。
一个简单的示例:
use tokio::{self, runtime::Runtime, time::{self, Duration}};
async fn sleep(n: u64) -> u64 {
time::sleep(Duration::from_secs(n)).await;
n
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
tokio::select! {
v = sleep(5) => println!("sleep 5 secs, branch 1 done: {}", v),
v = sleep(3) => println!("sleep 3 secs, branch 2 done: {}", v),
};
println!("select! done");
});
}输出结果:
sleep 3 secs, branch 2 done: 3
select! done
注意,select!本身是【阻塞】的,只有select!执行完,它后面的代码才会继续执行。
每个分支可以有一个if前置条件,当if前置条件为false时,对应的分支将被select!忽略(禁用),但该分支的异步任务仍然会执行,只不过select!不再轮询它(即不再推进异步任务的执行)。
下面是官方手册对select!工作流程的描述:
- 评估所有分支中存在的if前置条件,如果某个分支的前置条件返回false,则禁用该分支。注意,循环(如loop)时,每一轮执行的select!都会清除分支的禁用标记
- 收集所有分支中的异步表达式(包括已被禁用的分支),并在同一个线程中推进所有未被禁用的异步任务执行,然后等待
- 当某个分支的异步任务完成,将该异步任务的返回值与对应分支的模式进行匹配,如果匹配成功,则执行对应分支的handler,如果匹配失败,则禁用该分支,本次
select!调用不会再考虑该分支。如果匹配失败,则重新等待下一个异步任务的完成 - 如果所有分支最终都被禁用,则执行else分支,如果不存在else分支,则panic
默认情况下,select!会伪随机公平地轮询每一个分支,如果确实需要让select!按照任务书写顺序去轮询,可以在select!中使用biased。
例如,官方手册提供了一个很好的例子:
#[tokio::main]
async fn main() {
let mut count = 0u8;
loop {
tokio::select! {
// 如果取消biased,挑选的任务顺序将随机,可能会导致分支中的断言失败
biased;
_ = async {}, if count < 1 => { count += 1; assert_eq!(count, 1); }
_ = async {}, if count < 2 => { count += 1; assert_eq!(count, 2); }
_ = async {}, if count < 3 => { count += 1; assert_eq!(count, 3); }
_ = async {}, if count < 4 => { count += 1; assert_eq!(count, 4); }
else => { break; }
};
}
}另外,上面的例子中将select!放进了一个loop循环中,这是很常见的用法。对于上面的例子来说,如果注释掉biased,那么在第一轮循环中,由于select!中的4个if前置条件均为true,因此按照随机的顺序推进这4个异步任务。由于上面示例中的异步任务表达式不做任何事,因此第一个被推进的异步任务会先完成,selcet!将取消剩余3个任务,假如先完成任务的分支的断言通过,那么select!返回后将进入下一轮loop循环,重新调用一次select!宏,重新评估if条件,这次将只有3个分支通过检测,不通过的那个分支将被禁用,select!将按照随机顺序推进这3个分支。
JoinHandle::is_finished()
可使用JoinHandle的is_finished()方法来判断任务是否已终止,它是非阻塞的。
#![allow(unused)]
fn main() {
let task = tokio::spawn(async {
tokio::time::sleep(tokio::time::Duration::from_secs(5)).await;
});
// 立即输出 false
println!("1 {}", task.is_finished());
tokio::time::sleep(tokio::time::Duration::from_secs(10)).await;
// 输出 true
println!("2 {}", task.is_finished());
}is_finished()常用于在多个任务中轮询直到其中一个任务终止。
tokio task JoinSet
tokio::task::JoinSet用于收集一系列异步任务,并判断它们是否终止。
注意,使用JoinSet的spawn()方法创建的异步任务才会被收集。
示例如下:
use tokio::task::JoinSet;
#[tokio::main]
async fn main() {
let mut set = JoinSet::new();
// 创建10个异步任务并收集
for i in 0..10 {
// 使用JoinSet的spawn()方法创建异步任务
set.spawn(async move { i });
}
// join_next()阻塞直到其中一个任务完成
set.join_next().await();
set.abort_all();
}如果要等待多个或所有任务完成,则循环join_next()即可。如果JoinSet为空,则该方法返回None。
#![allow(unused)]
fn main() {
while let Some(_) = set.join_next().await {}
}使用JoinSet的abort_all()或直接Drop JoinSet,都会对所有异步任务进行abort()操作。
使用JoinSet的shutdown()方法,将先abort_all(),然后join_next()所有任务,直到任务集合为空。
使用JoinSet的detach_all()将使得集合中的所有任务都被detach,即时JoinSet被丢弃,被detach的任务也依然会在后台运行。
等待任一一个异步任务的终止
虽然join!() try_join!() select!()都可以等待一个或多个异步任务完成,但是有些情况下它们并不方便使用。
例如,客户端连接到服务端时,服务端为每个客户端都开启了n个异步任务,这些异步任务被收集在一个容器中(如Vec),这些任务都是长久工作的,直到客户端断开。理所当然地,应当去等待这些任务直到任意一个任务终止,然后abort()所有剩余任务,从而避免客户端断开后仍然在后台任务运行没有意义的任务,这很容易会导致内存飞速暴涨。
因为异步任务被收集在容器中,因此无法使用join!() try_join!() select!()去等待这些异步任务中的任意一个的完成。
有几种方式处理这种情况:
1.可以考虑使用is_finished()来轮询判断(为了避免忙等消耗CPU,建议加上轮询间隔)。
#![allow(unused)]
fn main() {
let tasks = vec![ Some_async_tasks ];
'outer: loop {
for task in &tasks {
if task.is_finished() {
break 'outer;
}
}
tokio::time::sleep(tokio::time::Duration::from_millis(100)).await;
}
for task in tasks {
task.abort();
}
}2.考虑使用JoinSet。参考JoinSet。
3.考虑使用futures::future::try_join_all或者futures::stream::FuturesUnordered。
使用tokio Timer
使用tokio Timer
本篇介绍tokio的计时器功能:Timer。
每一个异步框架都应该具备计时器功能,tokio的计时器功能在开启了time特性后可用。
tokio = {version = "1.13", features = ["rt", "rt-multi-thread", "time"]}
tokio的time模块包含几个功能:
Duration类型:是对std::time::Duration的重新导出,两者等价。它用于描述持续时长,例如睡眠3秒的3秒是一个时长,每隔3秒的3秒也是一个时长Instant类型:从程序运行开始就单调递增的时间点,仅结合Duration一起使用。例如,此刻是处在某个时间点A,下一次(例如某个时长过后),处在另一个时间点B,时间点B一定不会早于时间点A,即便修改了操作系统的时钟或硬件时钟,它也不会时光倒流的现象Sleep类型:是一个Future,通过调用sleep()或sleep_until()返回,该Future本身不做任何事,它只在到达某个时间点(Instant)时完成Interval类型:是一个流式的间隔计时器,通过调用interval()或interval_at()返回。Interval使用Duration来初始化,表示每隔一段时间(即指定的Duration时长)后就产生一个值Timeout类型:封装异步任务,并为异步任务设置超时时长,通过调用timeout()或timeout_at()返回。如果异步任务在指定时长内仍未完成,则异步任务被强制取消并返回Error
时长: tokio::time::Duration
tokio::time::Duration是对std::time::Duration的Re-exports,它两完全等价,因此可在tokio上下文中使用任何一种Duration。
Duration类型描述了一种时长,该结构包含两部分:秒和纳秒。
#![allow(unused)]
fn main() {
pub struct Duration {
secs: u64,
nanos: u32,
}
}可使用Duration::new(Sec, Nano_sec)来构建Duration。例如,Duration::new(5, 30)构建了一个5秒30纳秒的时长,即总共5_000_000_030纳秒。
如果Nano_sec部分超出了纳秒范围(1秒等于10亿纳秒),将进位到秒单位上,例如第二个参数指定为500亿纳秒,那么会向秒部分加50秒。
注意,构建时长时,这两部分的值可能会超出范围,例如计算后的秒部分的值超出了u64的范围,或者计算得到了负数。对此,Duration提供了几种不同的处理方式。
特殊地,如果两个参数都指定为0,那么表示时长为0,可用is_zero()来检测某个Duration是否是0时长。0时长可用于上下文切换(yield),例如sleep睡眠0秒,表示不用睡眠,但会交出CPU使得发生上下文切换。
还可以使用如下几种简便的方式构建各种单位的时长:
- Duration::from_secs(3):3秒时长
- Duration::from_millis(300):300毫秒时长
- Duration::from_micros(300):300微秒时长
- Duration::from_nanos(300):300纳秒时长
- Duration::from_secs_f32(2.3):2.3秒时长
- Duration::from_secs_f64(2.3):2.3秒时长
对于构建好的Duration实例dur = Duration::from_secs_f32(2.3),可以使用如下几种方法方便地提取、转换它的秒、毫秒、微秒、纳秒。
- dur.as_secs():转换为秒的表示方式,2
- dur.as_millis(): 转换为毫秒表示方式,2300
- dur.as_micros(): 转换为微秒表示方式,2_300_000
- dur.as_nanos(): 转换为纳秒表示方式,2_300_000_000
- dur.as_secs_f32(): 小数秒表示方式,2.3
- dur.as_secs_f64(): 小数秒表示方式,2.3
- dur.subsec_millis(): 小数部分转换为毫秒精度的表示方式,300
- dur.subsec_micros(): 小数部分转换为微秒精度的表示方式,300_000
- dur.subsec_nanos(): 小数部分转换为纳秒精度的表示方式,300_000_000
Duration实例可以直接进行大小比较以及加减乘除运算:
- checked_add(): 时长的加法运算,超出Duration范围时返回None
- checked_sub(): 时长的减法运算,超出Duration范围时返回None
- checked_mul(): 时长的乘法运算,超出Duration范围时返回None
- checked_div(): 时长的除法运算,超出Duration范围时(即分母为0)返回None
- saturating_add():饱和式的加法运算,超出范围时返回Duration支持的最大时长
- saturating_mul():饱和式的乘法运算,超出范围时返回Duration支持的最大时长
- saturating_sub():饱和式的减法运算,超出范围时返回0时长
- mul_f32():时长乘以小数,得到的结果如果超出范围或无效,则panic
- mul_f64():时长乘以小数,得到的结果如果超出范围或无效,则panic
- div_f32():时长除以小数,得到的结果如果超出范围或无效,则panic
- div_f64():时长除以小数,得到的结果如果超出范围或无效,则panic
时间点: tokio::time::Instant
Instant用于表示时间点,主要用于两个时间点的比较和相关运算。
tokio::time::Instant是对std::time::Instant的封装,添加了一些对齐功能,使其能够适用于tokio runtime。
Instant是严格单调递增的,绝不会出现时光倒流的现象,即之后的时间点一定晚于之前创建的时间点。但是,tokio time提供了pause()函数可暂停时间点,还提供了advance()函数用于向后跳转到某个时间点。
tokio::time::Instant::now()用于创建代表此时此刻的时间点。Instant可以直接进行大小比较,还能执行+、-操作。
use tokio;
use tokio::time::Instant;
use tokio::time::Duration;
#[tokio::main]
async fn main() {
// 创建代表此时此刻的时间点
let now = Instant::now();
// Instant 加一个Duration,得到另一个Instant
let next_3_sec = now + Duration::from_secs(3);
// Instant之间的大小比较
println!("{}", now < next_3_sec); // true
// Instant减Duration,得到另一个Instant
let new_instant = next_3_sec - Duration::from_secs(2);
// Instant减另一个Instant,得到Duration
// 注意,Duration有它的有效范围,因此必须是大的Instant减小的Instant,反之将panic
let duration = next_3_sec - new_instant;
}此外tokio::time::Instant还有以下几个方法:
- from_std(): 将
std::time::Instant转换为tokio::time::Instant - into_std(): 将
tokio::time::Instant转换为std::time::Instant - elapsed(): 指定的时间点实例,距离此时此刻的时间点,已经过去了多久(返回Duration)
- duration_since(): 两个Instant实例之间相差的时长,要求
B.duration_since(A)中的B必须晚于A,否则panic - checked_duration_since(): 两个时间点之间的时长差,如果计算返回的Duration无效,则返回None
- saturating_duration_since(): 两个时间点之间的时长差,如果计算返回的Duration无效,则返回0时长的Duration实例
- checked_add(): 为时间点加上某个时长,如果加上时长后是无效的Instant,则返回None
- checked_sub(): 为时间点减去某个时长,如果减去时长后是无效的Instant,则返回None
tokio顶层也提供了一个tokio::resume()方法,功能类似于tokio::time::from_std(),都是将std::time::Instant::now()保存为tokio::time::Instant。不同的是,后者用于创建tokio time Instant时间点,而resume()是让tokio的Instant的计时系统与系统的计时系统进行一次同步更新。
睡眠: tokio::time::Sleep
tokio::time::sleep()和tokio::time::sleep_until()提供tokio版本的睡眠任务:
use tokio::{self, runtime::Runtime, time};
fn main(){
let rt = Runtime::new().unwrap();
rt.block_on(async {
// 睡眠2秒
time::sleep(time::Duration::from_secs(2)).await;
// 一直睡眠,睡到2秒后醒来
time::sleep_until(time::Instant::now() + time::Duration::from_secs(2)).await;
});
}注意,std::thread::sleep()会阻塞当前线程,而tokio的睡眠不会阻塞当前线程,实际上tokio的睡眠在进入睡眠后不做任何事,仅仅只是立即放弃CPU,并进入任务轮询队列,等待睡眠时间终点到了之后被Reactor唤醒,然后进入就绪队列等待被调度。
可以简单理解异步睡眠:调用睡眠后,记录睡眠的终点时间点,之后在轮询到该任务时,比较当前时间点是否已经超过睡眠终点,如果超过了,则唤醒该睡眠任务,如果未超过终点,则不管。
注意,tokio的sleep的睡眠精度是毫秒,因此无法保证也不应睡眠更低精度的时间。例如不要睡眠100微秒或100纳秒,这时无法保证睡眠的时长。
下面是一个睡眠10微秒的例子,多次执行,会发现基本上都要1毫秒多,去掉执行指令的时间,实际的睡眠时长大概是1毫秒。另外,将睡眠10微秒改成睡眠100微秒或1纳秒,结果也是接近的。
use tokio::{self, runtime::Runtime, time};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let start = time::Instant::now();
// time::sleep(time::Duration::from_nanos(100)).await;
// time::sleep(time::Duration::from_micros(100)).await;
time::sleep(time::Duration::from_micros(10)).await;
println!("sleep {}", time::Instant::now().duration_since(start).as_nanos());
});
}执行的多次,输出结果:
sleep 1174300
sleep 1202900
sleep 1161200
sleep 1393200
sleep 1306400
sleep 1285300
sleep()或sleep_until()都返回time::Sleep类型,它有3个方法可调用:
- deadline(): 返回Instant,表示该睡眠任务的睡眠终点
- is_elapsed(): 可判断此时此刻是否已经超过了该sleep任务的睡眠终点
- reset():可用于重置睡眠任务。如果睡眠任务未完成,则直接修改睡眠终点,如果睡眠任务已经完成,则再次创建睡眠任务,等待新的终点
需要注意的是,reset()要求修改睡眠终点,因此Sleep实例需要是mut的,但这样会消费掉Sleep实例,更友好的方式是使用tokio::pin!(sleep)将sleep给pin在当前栈中,这样就可以调用as_mut()方法获取它的可修改版本。
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
#[allow(dead_code)]
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("start: {}", now());
let slp = time::sleep(time::Duration::from_secs(1));
tokio::pin!(slp);
slp.as_mut().reset(time::Instant::now() + time::Duration::from_secs(2));
slp.await;
println!("end: {}", now());
});
}输出:
start: 2021-11-02 21:57:42
end: 2021-11-02 21:57:44
重置已完成的睡眠实例:
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
#[allow(dead_code)]
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("start: {}", now());
let slp = time::sleep(time::Duration::from_secs(1));
tokio::pin!(slp);
//注意调用slp.as_mut().await,而不是slp.await,后者会move消费掉slp
slp.as_mut().await;
println!("end 1: {}", now());
slp.as_mut().reset(time::Instant::now() + time::Duration::from_secs(2));
slp.await;
println!("end 2: {}", now());
});
}输出结果:
start: 2021-11-02 21:59:25
end 1: 2021-11-02 21:59:26
end 2: 2021-11-02 21:59:28
任务超时: tokio::time::Timeout
tokio::time::timeout()或tokio::time::timeout_at()可设置一个异步任务的完成超时时间,前者接收一个Duration和一个Future作为参数,后者接收一个Instant和一个Future作为参数。这两个函数封装异步任务之后,返回time::Timeout,它也是一个Future。
如果在指定的超时时间内该异步任务已完成,则返回该异步任务的返回值,如果未完成,则异步任务被撤销并返回Err。
use chrono::Local;
use tokio::{self, runtime::Runtime, time};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let res = time::timeout(time::Duration::from_secs(5), async {
println!("sleeping: {}", now());
time::sleep(time::Duration::from_secs(6)).await;
33
});
match res.await {
Err(_) => println!("task timeout: {}", now()),
Ok(data) => println!("get the res '{}': {}", data, now()),
};
});
}得到结果:
sleeping: 2021-11-03 17:12:33
task timeout: 2021-11-03 17:12:38
如果将睡眠6秒改为睡眠4秒,那么将得到结果:
sleeping: 2021-11-03 17:13:11
get the res '33': 2021-11-03 17:13:15
得到time::Timeout实例res后,可以通过res.get_ref()或者res.get_mut()获得Timeout所封装的Future的可变和不可变引用,使用res.into_inner()获得所封装的Future,这会消费掉该Future。
如果要取消Timeout的计时等待,直接删除掉Timeout实例即可。
间隔任务: tokio::time::Interval
tokio::time::interval()和tokio::time::interval_at()用于设置间隔性的任务。
- interval_at(): 接收一个Instant参数和一个Duration参数,Instant参数表示间隔计时器的开始计时点,Duration参数表示间隔的时长
- interval(): 接收一个Duration参数,它在第一次被调用的时候立即开始计时
注意,这两个函数只是定义了间隔计时器的起始计时点和间隔的时长,要真正开始让它开始计时,还需要调用它的tick()方法生成一个Future任务,并调用await来执行并等待该任务的完成。
例如,5秒后开始每隔1秒执行一次输出操作:
use chrono::Local;
use tokio::{self, runtime::Runtime, time::{self, Duration, Instant}};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("before: {}", now());
// 计时器的起始计时点:此时此刻之后的5秒后
let start = Instant::now() + Duration::from_secs(5);
let interval = Duration::from_secs(1);
let mut intv = time::interval_at(start, interval);
// 该计时任务"阻塞",直到5秒后被唤醒
intv.tick().await;
println!("task 1: {}", now());
// 该计时任务"阻塞",直到1秒后被唤醒
intv.tick().await;
println!("task 2: {}", now());
// 该计时任务"阻塞",直到1秒后被唤醒
intv.tick().await;
println!("task 3: {}", now());
});
}输出结果:
before: 2021-11-03 18:52:14
task 1: 2021-11-03 18:52:19
task 2: 2021-11-03 18:52:20
task 3: 2021-11-03 18:52:21
上面定义的计时器,有几点需要说明清楚:
- interval_at()第一个参数定义的是计时器的开始时间,这样描述不准确,它表述的是最早都要等到这个时间点才开始计时。例如,定义计时器5秒之后开始计时,但在第一次tick()之前,先睡眠了10秒,那么该计时器将在10秒后才开始,但如果第一次tick之前只睡眠了3秒,那么还需再等待2秒该tick计时任务才会完成。
- 定义计时器时,要将其句柄(即计时器变量)声明为mut,因为每次tick时,都需要修改计时器内部的下一次计时起点。
- 不像其它语言中的间隔计时器,tokio的间隔计时器需要手动调用tick()方法来生成临时的异步任务。
- 删除计时器句柄可取消间隔计时器。
再看下面的示例,定义5秒后开始的计时器,但在第一次开始计时前,先睡眠10秒。
use chrono::Local;
use tokio::{
self,
runtime::Runtime,
time::{self, Duration, Instant},
};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("before: {}", now());
let start = Instant::now() + Duration::from_secs(5);
let interval = Duration::from_secs(1);
let mut intv = time::interval_at(start, interval);
time::sleep(Duration::from_secs(10)).await;
intv.tick().await;
println!("task 1: {}", now());
intv.tick().await;
println!("task 2: {}", now());
});
}输出结果:
before: 2021-11-03 19:00:10
task 1: 2021-11-03 19:00:20
task 2: 2021-11-03 19:00:20
注意输出结果中的task 1和task 2的时间点是相同的,说明第一次tick之后,并没有等待1秒之后再执行紧跟着的tick,而是立即执行之。
简单解释一下上面示例中的计时器内部的工作流程,假设定义计时器的时间点是19:00:10:
- 定义5秒后开始的计时器intv,该计时器内部有一个字段记录着下一次开始tick的时间点,其值为19:00:15
- 睡眠10秒后,时间点到了19:00:20,此时第一次执行
intv.tick(),它将生成一个异步任务,执行器执行时发现此时此刻的时间点已经超过该计时器内部记录的值,于是该异步任务立即完成并进入就绪队列等待调度,同时修改计时器内部的值为19:00:16 - 下一次执行tick的时候,此时此刻仍然是19:00:20,已经超过了该计时器内部的19:00:16,因此计时任务立即完成
这是tokio Interval在遇到计时延迟时的默认计时策略,叫做Burst。tokio支持三种延迟后的计时策略。可使用set_missed_tick_behavior(MissedTickBehavior)来修改计时策略。
1.Burst策略,冲刺型的计时策略,当出现延迟后,将尽量快地完成接下来的tick,直到某个tick赶上它正常的计时时间点。
例如,5秒后开始的每隔1秒的计时器,第一次开始tick前睡眠了10秒,那么10秒后将立即进行如下几次tick,或者说瞬间完成如下几次tick:
- 第一次tick,它本该在第五秒的时候被执行
- 第二次tick,它本该在第六秒的时候被执行
- 第三次tick,它本该在第七秒的时候被执行
- 第四次tick,它本该在第八秒的时候被执行
- 第五次tick,它本该在第九秒的时候被执行
- 第六次tick,它本该在第十秒的时候被执行
而第七次tick的时间点,将回归正常,即在第十一秒的时候开始被执行。
2.Delay策略,延迟性的计时策略,当出现延迟后,仍然按部就班地每隔指定的时长计时。在内部,这种策略是在每次执行tick之后,都修改下一次计时起点为Instant::now() + Duration。因此,这种策略下的任何相邻两次的tick,其中间间隔的时长都至少达到Duration。
例如:
use chrono::Local;
use tokio::{self, runtime::Runtime};
use tokio::time::{self, Duration, Instant, MissedTickBehavior};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("before: {}", now());
let mut intv = time::interval_at(
Instant::now() + Duration::from_secs(5),
Duration::from_secs(2),
);
intv.set_missed_tick_behavior(MissedTickBehavior::Delay);
time::sleep(Duration::from_secs(10)).await;
println!("start: {}", now());
intv.tick().await;
println!("tick 1: {}", now());
intv.tick().await;
println!("tick 2: {}", now());
intv.tick().await;
println!("tick 3: {}", now());
});
}输出结果:
before: 2021-11-03 19:31:02
start: 2021-11-03 19:31:12
tick 1: 2021-11-03 19:31:12
tick 2: 2021-11-03 19:31:14
tick 3: 2021-11-03 19:31:16
3.Skip策略,忽略型的计时策略,当出现延迟后,仍然所有已经被延迟的计时任务。这种策略总是以定义计时器时的起点为基准,类似等差数量,每一次执行tick的时间点,一定符合Start + N * Duration。
use chrono::Local;
use tokio::{self, runtime::Runtime};
use tokio::time::{self, Duration, Instant, MissedTickBehavior};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
println!("before: {}", now());
let mut intv = time::interval_at(
Instant::now() + Duration::from_secs(5),
Duration::from_secs(2),
);
intv.set_missed_tick_behavior(MissedTickBehavior::Skip);
time::sleep(Duration::from_secs(10)).await;
println!("start: {}", now());
intv.tick().await;
println!("tick 1: {}", now());
intv.tick().await;
println!("tick 2: {}", now());
intv.tick().await;
println!("tick 3: {}", now());
});
}输出结果:
before: 2021-11-03 19:34:53
start: 2021-11-03 19:35:03
tick 1: 2021-11-03 19:35:03
tick 2: 2021-11-03 19:35:04
tick 3: 2021-11-03 19:35:06
注意上面的输出结果中,第一次tick和第二次tick只相差1秒而不是相差2秒。
上面通过interval_at()解释清楚了tokio::time::Interval的三种计时策略。但在程序中,更大的可能是使用interval()来定义间隔计时器,它等价于interval_at(Instant::now() + Duration),表示计时起点从现在开始的计时器。
此外,可以使用period()方法获取计时器的间隔时长,使用missed_tick_behavior()获取当前的计时策略。
tokio task的通信和同步(1): 简介
tokio task的通信和同步(1): 简介
通常来说,对于允许并发多执行分支的内核或引擎来说,都需要提供对应的通信机制和同步机制。
例如,多进程之间,有进程间通信方式,比如管道、套接字、共享内存、消息队列等,还有进程间的同步机制,例如信号量、文件锁、条件变量等。多线程之间,也有线程间通信方式,简单粗暴的是直接共享同进程内存,同步机制则有互斥锁、条件变量等。
tokio提供了异步多任务的并发能力,它也需要提供异步任务之间的通信方式和同步机制。
在介绍它们之前,需要先开启tokio的同步功能。
tokio = {version = "1.13", features = ["rt", "sync", "rt-multi-thread"]}
sync模块功能简介
sync模块主要包含两部分功能:异步任务之间的通信模块以及异步任务之间的状态同步模块。
任务间通信
tokio的异步任务之间主要采用消息传递(message passing)的通信方式,即某个异步任务负责发消息,另一个异步任务收消息。这种通信方式的最大优点是避免并发任务之间的数据共享,消灭数据竞争,使得代码更加安全,更加容易维护。
消息传递通常使用通道(channel)来进行通信。tokio提供几种不同功能的通道:
- oneshot通道: 一对一发送的一次性通道,即该通道只能由一个发送者(Sender)发送最多一个数据,且只有一个接收者(Receiver)接收数据
- mpsc通道: 多对一发送,即该通道可以同时有多个发送者向该通道发数据,但只有一个接收者接收数据
- broadcast通道: 多对多发送,即该通道可以同时有多个发送者向该通道发送数据,也可以有多个接收者接收数据
- watch通道: 一对多发送,即该通道只能有一个发送者向该通道发送数据,但可以有多个接收者接收数据
不同类型的通道,用于解决不同场景的需求。通常来说,最常用的是mpsc类型的通道。
任务间状态同步
在编写异步任务的并发代码时,很多时候需要去检测任务之间的状态。比如任务A需要等待异步任务B执行完某个操作后才允许向下执行。
比较原始的解决方式是直接用代码去轮询判断状态是否达成。但在异步编程过程中,这类状态检测的需求非常普遍,因此异步框架会提供一些内置在框架中的同步原语。同步原语封装了各种状态判断、状态等待的轮询操作,这使得编写任务状态同步的代码变得更加简单直接。
通常来说,有以下几种基本的同步原语,这些也是tokio所提供的:
- Mutex: 互斥锁,任务要执行某些操作时,必须先申请锁,只有申请到锁之后才能执行操作,否则就等待
- RwLock: 读写锁,类似于互斥锁,但粒度更细,区分读操作和写操作,可以同时存在多个读操作,但写操作必须独占锁资源
- Notify: 任务通知,用于唤醒正在等待的任务,使其进入就绪态等待调度
- Barrier: 屏障,多个任务在某个屏障处互相等待,只有这些任务都达到了那个屏障点,这些任务才都继续向下执行
- Semaphore: 信号量(信号灯),限制同时执行的任务数量,例如限制最多只有20个线程(或tokio的异步任务)同时执行
tokio task的通信和同步(2): 通信
tokio task的通信和同步(2): 通信
tokio使用通道在task之间进行通信,有四种类型通道:oneshot、mpsc、broadcast和watch。
oneshot通道
oneshot通道的特性是:单Sender、单Receiver以及单消息,简单来说就是一次性的通道。
oneshot通道的创建方式是使用oneshot::channel()方法:
#![allow(unused)]
fn main() {
pub fn channel<T>() -> (Sender<T>, Receiver<T>)
}它返回该通道的写端sender和读端receiver,其中泛型T表示的是读写两端所传递的消息类型。
例如,创建一个可发送i32数据的一次性通道:
#![allow(unused)]
fn main() {
let (tx, rx) = oneshot::channel::<i32>();
}返回的结果中,tx是发送者(sender)、rx是接收者(receiver)。
多数时候不需要去声明通道的类型,编译器可以根据发送数据时的类型自动推断出类型。
#![allow(unused)]
fn main() {
let (tx, rx) = oneshot::channel();
}Sender
Sender通过send()方法发送数据,因为oneshot通道只能发送一次数据,所以send()发送数据的时候,tx直接被消费掉。Sender并不一定总能成功发送消息,比如,Sender发送消息之前,Receiver端就已经关闭了读端。因此send()返回Result结果:如果发送成功,则返回Ok(()),如果发送失败,则返回Err(T)。
因此,发送数据的时候,通常会做如下检测:
#![allow(unused)]
fn main() {
// 或 if tx.send(33).is_err() {}
// 或直接忽略错误 let _ = tx.send();
if let Err(_) = tx.send(33) {
println!("receiver closed");
}
}另外需注意,send()是非异步但却不阻塞的,它总是立即返回,如果能发送数据,则发送数据,如果不能发送数据,就返回错误,它不会等待Receiver启动读取操作。也因此,send()可以应用在同步代码中,也可以应用在异步代码中。
Sender可以通过is_closed()方法来判断Receiver端是否已经关闭。
Sender可以通过close()方法来等待Receiver端关闭。它可以结合select!宏使用:其中一个分支计算要发送的数据,另一个分支为closed()等待分支,如果先计算完成,则发送计算结果,而如果是先等到了对端closed的异步任务完成,则无需再计算浪费CPU去计算结果。例如:
#![allow(unused)]
fn main() {
tokio::spawn(async move {
tokio::select! {
_ = tx.closed() => {
// 先等待到了对端关闭,不做任何事,select!会自动取消其它分支的任务
}
value = compute() => {
// 先计算得到结果,则发送给对端
// 但有可能刚计算完成,尚未发送时,对端刚好关闭,因此可能发送失败
// 此处丢弃发送失败的错误
let _ = tx.send(value);
}
}
});
}Receiver
Receiver没有recv()方法,rx本身实现了Future Trait,它执行时对应的异步任务就是接收数据,因此只需await即可用来接收数据。
但是,接收数据并不一定会接收成功。例如,Sender端尚未发送任何数据就已经关闭了(被drop),此时Receiver端会接收到error::RecvError错误。因此,接收数据的时候通常也会进行判断:
#![allow(unused)]
fn main() {
match rx.await {
Ok(v) => println!("got = {:?}", v),
Err(_) => println!("the sender dropped"),
// Err(e: RecvError) => xxx,
}
}既然通过rx.await来接收数据,那么已经隐含了一个信息,异步任务中接收数据时会进行等待。
Receiver端可以通过close()方法关闭自己这一端,当然也可以直接drop来关闭。关闭操作是幂等的,即,如果关闭的是已经关闭的Recv,则不产生任何影响。
关闭Recv端之后,可以保证Sender端无法再发送消息。但需要注意,有可能Recv端关闭完成之前,Sender端正好在这时发送了一个数据过来。因此,在关闭Recv端之后,尽可能地再调用一下try_recv()方法尝试接收一次数据。
try_recv()方法返回三种可能值:
Ok(T): 表示成功接收到通道中的数据Err(TryRecvError::Empty): 表示通道为空Err(TryRecvError::Closed): 表示通道为空,且Sender端已关闭,即Sender未发送任何数据就关闭了
例如:
#![allow(unused)]
fn main() {
let (tx, mut rx) = oneshot::channel::<()>();
drop(tx);
match rx.try_recv() {
// The channel will never receive a value.
Err(TryRecvError::Closed) => {}
_ => unreachable!(),
}
}使用示例
一个完整但简单的示例:
use tokio::{self, runtime::Runtime, sync};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let (tx, rx) = sync::oneshot::channel();
tokio::spawn(async move {
if tx.send(33).is_err() {
println!("receiver dropped");
}
});
match rx.await {
Ok(value) => println!("received: {:?}", value),
Err(_) => println!("sender dropped"),
};
});
}另一个比较常见的使用场景是结合select!宏,此时应在recv前面加上&mut。例如:
#![allow(unused)]
fn main() {
let interval = tokio::interval(tokio::time::Duration::from_millis(100));
// 注意mut
let (tx, mut rx) = oneshot::channel();
loop {
// 注意,select!中无需await,因为select!会自动轮询推进每一个分支的任务进度
tokio::select! {
_ = interval.tick() => println!("Another 100ms"),
msg = &mut recv => {
println!("Got message: {}", msg.unwrap());
break;
}
}
}
}mpsc通道
mpsc通道的特性是可以有多个发送者发送多个消息,且只有一个接收者。mpsc通道是使用最频繁的通道类型。
mpsc通道分为两种:
- bounded channel: 有界通道,通道有容量限制,即通道中最多可以存放指定数量(至少为1)的消息,通过
mpsc::channel()创建 - unbounded channel: 无界通道,通道中可以无限存放消息,直到内存耗尽,通过
mpsc::unbounded_channel()创建
有界通道
通过mpsc::channel()创建有界通道,需传递一个大于1的usize值作为其参数。
例如,创建一个最多可以存放100个消息的有界通道。
#![allow(unused)]
fn main() {
// tx是Sender端,rx是Receiver端
// 接收端接收数据时需修改状态,因此声明为mut
let (tx, mut rx) = mpsc::channel(100);
}mpsc通道只能有一个Receiver端,但可以tx.clone()得到多个Sender端,clone得到的Sender都可以使用send()方法向该通道发送消息。
发送消息时,如果通道已满,发送消息的任务将等待直到通道中有空闲的位置。
发送消息时,如果Receiver端已经关闭,则发送消息的操作将返回SendError。
如果所有的Sender端都已经关闭,则Receiver端接收消息的方法recv()将返回None。
一个简单的示例:
use tokio::{ self, runtime::Runtime, sync };
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let (tx, mut rx) = sync::mpsc::channel::<i32>(10);
tokio::spawn(async move {
for i in 1..=10 {
// if let Err(_) = tx.send(i).await {}
if tx.send(i).await.is_err() {
println!("receiver closed");
return;
}
}
});
while let Some(i) = rx.recv().await {
println!("received: {}", i);
}
});
}输出的结果:
received: 1
received: 2
received: 3
received: 4
received: 5
received: 6
received: 7
received: 8
received: 9
received: 10
上面的示例中,先生成了一个异步任务,该异步任务向通道中发送10个数据,Receiver端则在while循环中不断从通道中取数据。
将上面的示例改一下,生成10个异步任务分别发送数据:
use tokio::{ self, runtime::Runtime, sync };
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let (tx, mut rx) = sync::mpsc::channel::<i32>(10);
for i in 1..=10 {
let tx = tx.clone();
tokio::spawn(async move {
if tx.send(i).await.is_err() {
println!("receiver closed");
}
});
}
drop(tx);
while let Some(i) = rx.recv().await {
println!("received: {}", i);
}
});
}输出的结果:
received: 2
received: 3
received: 1
received: 4
received: 6
received: 5
received: 10
received: 7
received: 8
received: 9
10个异步任务发送消息的顺序是未知的,因此接收到的消息无法保证顺序。
另外注意上面示例中的drop(tx),因为生成的10个异步任务中都拥有clone后的Sender,clone出的Sender在每个异步任务完成时自动被drop,但原始任务中还有一个Sender,如果不关闭这个Sender,rx.recv()将不会返回None,而是一直等待。
如果通道已满,Sender通过send()发送消息时将等待。例如下面的示例中,通道容量为5,但要发送7个数据,前5个数据会立即发送,发送第6个消息的时候将等待,直到1秒后Receiver开始从通道中消费数据。
use chrono::Local;
use tokio::{self, sync, runtime::Runtime, time::{self, Duration}};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let (tx, mut rx) = sync::mpsc::channel::<i32>(5);
tokio::spawn(async move {
for i in 1..=7 {
if tx.send(i).await.is_err() {
println!("receiver closed");
return;
}
println!("sended: {}, {}", i, now());
}
});
time::sleep(Duration::from_secs(1)).await;
while let Some(i) = rx.recv().await {
println!("received: {}", i);
}
});
}输出结果:
sended: 1, 2021-11-12 18:25:28
sended: 2, 2021-11-12 18:25:28
sended: 3, 2021-11-12 18:25:28
sended: 4, 2021-11-12 18:25:28
sended: 5, 2021-11-12 18:25:28
received: 1
received: 2
received: 3
received: 4
received: 5
sended: 6, 2021-11-12 18:25:29
sended: 7, 2021-11-12 18:25:29
received: 6
sended: 8, 2021-11-12 18:25:29
received: 7
received: 8
received: 9
sended: 9, 2021-11-12 18:25:29
sended: 10, 2021-11-12 18:25:29
received: 10
Sender端和Receiver端有一些额外的方法需要解释一下它们的作用。
对于Sender端:
- capacity(): 获取当前通道的剩余容量(注意,不是初始化容量)
- closed(): 等待Receiver端关闭,当Receiver端关闭后该等待任务会立即完成
- is_closed(): 判断Receiver端是否已经关闭
- send(): 向通道中发送消息,通道已满时会等待通道中的空闲位置,如果对端已关闭,则返回错误
- send_timeout(): 向通道中发送消息,通道已满时只等待指定的时长
- try_send(): 向通道中发送消息,但不等待,如果发送不成功,则返回错误
- reserve(): 等待并申请一个通道中的空闲位置,返回一个Permit,申请的空闲位置被占位,且该位置只留给该Permit实例,之后该Permit可以直接向通道中发送消息,并释放其占位的位置。申请成功时,通道空闲容量减1,释放位置时,通道容量会加1
- try_reserve(): 尝试申请一个空闲位置且不等待,如果无法申请,则返回错误
- reserve_owned(): 与reserve()类似,它返回OwnedPermit,但会Move Sender
- try_reserve_owned(): reserve_owned()的不等待版本,尝试申请空闲位置失败时会立即返回错误
- blocking_send(): Sender可以在同步代码环境中使用该方法向异步环境发送消息
对于Receiver端:
- close(): 关闭Receiver端
- recv(): 接收消息,如果通道已空,则等待,如果对端已全部关闭,则返回None
- try_recv(): 尝试接收消息,不等待,如果无法接收消息(即通道为空或对端已关闭),则返回错误
- blocking_recv(): Receiver可以在同步代码环境中使用该方法接收来自异步环境的消息
注意,在这些方法中,try_xxx()方法都是立即返回不等待的(可以认为是同步代码),因此调用它们后无需await,只有调用那些可能需要等待的方法,调用后才需要await。例如rx.recv().await和rx.try_recv()。
下面是一些稍详细的用法说明和示例。
Sender端可通过send_timeout()来设置一个等待通道空闲位置的超时时间,它和send()返回值一样,此外还添加一种超时错误:超时后仍然没有发送成功时将返回错误。至于返回的是什么错误,对于发送端来说不重要,重要的是发送的消息是否成功。因此,对于Sender端的条件判断,通常也仅仅只是检测is_err():
#![allow(unused)]
fn main() {
if tx.send_timeout(33, Duration::from_secs(1)).await.is_err() {
println!("receiver closed or timeout");
}
}需要特别注意的是,Receiver端调用close()方法关闭通道后,只是半关闭状态,Receiver端仍然可以继续读取可能已经缓冲在通道中的消息,close()只能保证Sender端无法再发送普通的消息,但Permit或OwnedPermit仍然可以向通道发送消息。只有通道已空且所有Sender端(包括Permit和OwnedPermit)都已经关闭的情况下,recv()才会返回None,此时代表通道完全关闭。
Receiver的try_recv()方法在无法立即接收消息时会立即返回错误。返回的错误分为两种:
- TryRecvError::Empty错误: 表示通道已空,但Sender端尚未全部关闭
- TryRecvError::Disconnected错误: 表示通道已空,且Sender端(包括Permit和OwnedPermit)已经全部关闭
关于reserve()和reserve_owned(),看官方示例即可轻松理解:
use tokio::sync::mpsc;
#[tokio::main]
async fn main() {
// 创建容量为1的通道
let (tx, mut rx) = mpsc::channel(1);
// 申请并占有唯一的空闲位置
let permit = tx.reserve().await.unwrap();
// 唯一的位置已被permit占有,tx.send()无法发送消息
assert!(tx.try_send(123).is_err());
// Permit可以通过send()方法向它占有的那个位置发送消息
permit.send(456);
// Receiver端接收到消息
assert_eq!(rx.recv().await.unwrap(), 456);
// 创建容量为1的通道
let (tx, mut rx) = mpsc::channel(1);
// tx.reserve_owned()会消费掉tx
let permit = tx.reserve_owned().await.unwrap();
// 通过permit.send()发送消息,它又返回一个Sender
let tx = permit.send(456);
assert_eq!(rx.recv().await.unwrap(), 456);
//可以继续使用返回的Sender发送消息
tx.send(789).await.unwrap();
}无界通道
理解了mpsc的有界通道之后,再理解无界通道会非常轻松。
#![allow(unused)]
fn main() {
let (tx, mut rx) = mpsc::unbounded_channel();
}对于无界通道,它的通道中可以缓冲无限数量的消息,直到内存耗尽。这意味着,Sender端可以无需等待地不断向通道中发送消息,这也意味着无界通道的Sender既可以在同步环境中也可以在异步环境中向通道中发送消息。只有当Receiver端已经关闭,Sender端的发送才会返回错误。
使用无界通道的关键,在于必须要保证不会无限度地缓冲消息而导致内存耗尽。例如,让Receiver端消费消息的速度尽量快,或者采用一些复杂的限速机制让严重超前的Sender端等一等。
broadcast通道
broadcast通道是一种广播通道,可以有多个Sender端以及多个Receiver端,可以发送多个数据,且任何一个Sender发送的每一个数据都能被所有的Receiver端看到。
使用mpsc::broadcast()创建广播通道,要求指定一个通道容量作为参数。它返回Sender和Receiver。Sender可以克隆得到多个Sender,可以调用Sender的subscribe()方法来创建新的Receiver。
例如,下面是官方文档提供的一个示例:
use tokio::sync::broadcast;
#[tokio::main]
async fn main() {
// 最多存放16个消息
// tx是Sender,rx1是Receiver
let (tx, mut rx1) = broadcast::channel(16);
// Sender的subscribe()方法可生成新的Receiver
let mut rx2 = tx.subscribe();
tokio::spawn(async move {
assert_eq!(rx1.recv().await.unwrap(), 10);
assert_eq!(rx1.recv().await.unwrap(), 20);
});
tokio::spawn(async move {
assert_eq!(rx2.recv().await.unwrap(), 10);
assert_eq!(rx2.recv().await.unwrap(), 20);
});
tx.send(10).unwrap();
tx.send(20).unwrap();
}Sender端通过send()发送消息的时候,如果所有的Receiver端都已关闭,则send()方法返回错误。
Receiver端可通过recv()去接收消息,如果所有的Sender端都已经关闭,则该方法返回RecvError::Closed错误。该方法还可能返回RecvError::Lagged错误,该错误表示接收端已经落后于发送端。
虽然broadcast通道也指定容量,但是通道已满的情况下还可以继续写入新数据而不会等待(因此上面示例中的send()无需await),此时通道中最旧的(头部的)数据将被剔除,并且新数据添加在尾部。就像是FIFO队列一样。出现这种情况时,就意味着接收端已经落后于发送端。
当接收端已经开始落后于发送端时,下一次的recv()操作将直接返回RecvError::Lagged错误。如果紧跟着再执行recv()且落后现象未再次发生,那么这次的recv()将取得队列头部的消息。
use tokio::sync::broadcast;
#[tokio::main]
async fn main() {
// 通道容量2
let (tx, mut rx) = broadcast::channel(2);
// 写入3个数据,将出现接收端落后于发送端的情况,
// 此时,第一个数据(10)将被剔除,剔除后,20将位于队列的头部
tx.send(10).unwrap();
tx.send(20).unwrap();
tx.send(30).unwrap();
// 落后于发送端之后的第一次recv()操作,返回RecvError::Lagged错误
assert!(rx.recv().await.is_err());
// 之后可正常获取通道中的数据
assert_eq!(20, rx.recv().await.unwrap());
assert_eq!(30, rx.recv().await.unwrap());
}Receiver也可以使用try_recv()方法去无等待地接收消息,如果Sender都已关闭,则返回TryRecvError::Closed错误,如果接收端已落后,则返回TryRecvError::Lagged错误,如果通道为空,则返回TryRecvError::Empty错误。
另外,tokio::broadcast的任何一个Receiver都可以看到每一次发送的消息,且它们都可以去recv()同一个消息,tokio::broadcast对此的处理方式是消息克隆:每一个Receiver调用recv()去接收一个消息的时候,都会克隆通道中的该消息一次,直到所有存活的Receiver都克隆了该消息,该消息才会从通道中被移除,进而释放一个通道空闲位置。
这可能会导致一种现象:某个ReceiverA已经接收了通道中的第10个消息,但另一个ReceiverB可能尚未接收第一个消息,由于第一个消息还未被全部接收者所克隆,它仍会保留在通道中并占用通道的位置,假如该通道的最大容量为10,此时Sender再发送一个消息,那么第一个数据将被踢掉,ReceiverB接收到消息的时候将收到RecvError::Lagged错误并永远地错过第一个消息。
watch通道
watch通道的特性是:只能有单个Sender,可以有多个Receiver,且通道永远只保存一个数据。Sender每次向通道中发送数据时,都会修改通道中的那个数据。
通道中的这个数据可以被Receiver进行引用读取。
一个简单的官方示例:
use tokio::sync::watch;
#[tokio::main]
async fn main() {
// 创建watch通道时,需指定一个初始值存放在通道中
let (tx, mut rx) = watch::channel("hello");
// Recevier端,通过changed()来等待通道的数据发生变化
// 通过borrow()引用通道中的数据
tokio::spawn(async move {
while rx.changed().await.is_ok() {
println!("received = {:?}", *rx.borrow());
}
});
// 向通道中发送数据,实际上是修改通道中的那个数据
tx.send("world")?;
}watch通道的用法很简单,但是有些细节需要理解。
Sender端可通过subscribe()创建新的Receiver端。
当所有Receiver端均已关闭时,send()方法将返回错误。也就是说,send()必须要在有Receiver存活的情况下才能发送数据。
但是Sender端还有一个send_replace()方法,它可以在没有Receiver的情况下将数据写入通道,并且该方法会返回通道中原来保存的值。
无论是Sender端还是Receiver端,都可以通过borrow()方法取得通道中当前的值。由于可以有多个Receiver,为了避免读写时的数据不一致,watch内部使用了读写锁:Sender端要发送数据修改通道中的数据时,需要申请写锁,论是Sender还是Receiver端,在调用borrow()或其它一些方式访问通道数据时,都需要申请读锁。因此,访问通道数据时要尽快释放读锁,否则可能会长时间阻塞Sender端的发送操作。
如果Sender端未发送数据,或者隔较长时间才发送一次数据,那么通道中的数据在一段时间内将一直保持不变。如果Receiver在这段时间内去多次读取通道,得到的结果将完全相同。但有时候,可能更需要的是等待通道中的数据已经发生变化,然后再根据新的数据做进一步操作,而不是循环不断地去读取并判断当前读取到的值是否和之前读取的旧值相同。
watch通道已经提供了这种功能:Receiver端可以标记通道中的数据,记录该数据是否已经被读取过。Receiver端的changed()方法用于等待通道中的数据发生变化,其内部判断过程是:如果通道中的数据已经被标记为已读取过,那么changed()将等待数据更新,如果数据未标记过已读取,那么changed()认为当前数据就是新数据,changed()会立即返回。
Receiver端的borrow()方法不会标记数据已经读取,所以borrow()之后调用的changed()会立即返回。但是changed()等待到新值之后,会立即将该值标记为已读取,使得下次调用changed()时会进行等待。
此外,Receiver端还有一个borrow_and_update()方法,它会读取数据并标记数据已经被读取,因此随后调用chagned()将进入等待。
最后再强调一次,无论是Sender端还是Receiver端,访问数据的时候都会申请读锁,要尽量快地释放读锁,以免Sender长时间无法发送数据。
tokio task的通信和同步(3): 同步
tokio task的通信和同步(3): 同步
tokio::sync模块提供了几种状态同步的机制:
- Mutex: 互斥锁
- RwLock: 读写锁
- Notify: 通知唤醒机制
- Barrier: 屏障
- Semaphore: 信号量
因为tokio是跨线程执行任务的,因此通常会使用Arc来封装这些同步原语,以使其能够跨线程。例如:
#![allow(unused)]
fn main() {
let mutex = Arc::new(Mutex::new());
let rwlock = Arc::new(RwLock::new());
}Mutex互斥锁
当多个并发任务(tokio task或线程)可能会修改同一个数据时,就会出现数据竞争现象(竞态),具体表现为:某个任务对该数据的修改不生效或被覆盖。
互斥锁的作用,就是保护并发情况下可能会出现竞态的代码,这部分代码称为临界区。当某个任务要执行临界区中的代码时,必须先申请锁,申请成功,则可以执行这部分代码,执行完成这部分代码后释放锁。释放锁之前,其它任务无法再申请锁,它们必须等待锁被释放。
假如某个任务一直持有锁,其它任务将一直等待。因此,互斥锁应当尽量快地释放,这样可以提高并发量。
简单介绍完互斥锁之后,再看tokio提供的互斥锁。
tokio::sync::Mutex使用new()来创建互斥锁,使用lock()来申请锁,申请锁成功时将返回MutexGuard,并通过drop的方式来释放锁。
例如:
use std::sync::Arc;
use tokio::{self, sync, runtime::Runtime, time::{self, Duration}};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let mutex = Arc::new(sync::Mutex::new(0));
for i in 0..10 {
let lock = Arc::clone(&mutex);
tokio::spawn(async move {
let mut data = lock.lock().await;
*data += 1;
println!("task: {}, data: {}", i, data);
});
}
time::sleep(Duration::from_secs(1)).await;
});
}输出结果:
task: 0, data: 1
task: 2, data: 2
task: 3, data: 3
task: 4, data: 4
task: 1, data: 5
task: 7, data: 6
task: 9, data: 7
task: 6, data: 8
task: 5, data: 9
task: 8, data: 10
可以看到,任务的调度顺序是随机的,但是数据加1的操作是依次完成的。
需特别说明的是,tokio::sync::Mutex其内部使用了标准库的互斥锁,即std::sync::Mutex,而标准库的互斥锁是针对线程的,因此,使用tokio的互斥锁时也会锁住整个线程。此外,tokio::sync::Mutex是对标准库的Mutex的封装,性能相对要更差一些。也因此,官方文档中建议,如非必须,应使用标准库的Mutex或性能更高的parking_lot提供的互斥锁,而不是tokio的Mutex。
例如,将上面的示例该成标准库的Mutex锁。
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let mutex = Arc::new(std::sync::Mutex::new(0));
for i in 0..10 {
let lock = mutex.clone();
tokio::spawn(async move {
let mut data = lock.lock().unwrap();
*data += 1;
println!("task: {}, data: {}", i, data);
});
}
time::sleep(Duration::from_secs(1)).await;
});
}什么情况下可以选择使用tokio的Mutex?当跨await的时候,可以考虑使用tokio Mutex,因为这时使用标准库的Mutex将编译错误。当然,也有相应的解决方案。
什么是跨await?每个await都代表一个异步任务,跨await即表示该异步任务中出现了至少一个子任务。而每个异步任务都可能会被tokio内部偷到不同的线程上执行,因此跨await时要求其父任务实现Send Trait,这是因为子任务中可能会引用父任务中的数据。
例如,下面定义的async函数中使用了标准库的Mutex,且有子任务,这会编译错误:
use std::sync::{Arc, Mutex, MutexGuard};
use tokio::{self, runtime::Runtime, time::{self, Duration}};
async fn add_1(mutex: &Mutex<u64>) {
let mut lock = mutex.lock().unwrap();
*lock += 1;
// 子任务,跨await,且引用了父任务中的数据
time::sleep(Duration::from_millis(*lock)).await;
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let mutex = Arc::new(Mutex::new(0));
for i in 0..10 {
let lock = mutex.clone();
tokio::spawn(async move {
add_1(&lock).await;
});
}
time::sleep(Duration::from_secs(1)).await;
});
}std::sync::MutexGuard未实现Send,因此父任务async move{}语句块是非Send的,于是编译报错。但如果上面的示例中没有子任务sleep().await子任务,则编译无错,因为已经可以明确知道该Mutex所在的任务是在当前线程执行的。
对于上面的错误,可简单地使用tokio::sync::Mutex来修复。
use std::sync::Arc;
use tokio::{ self, runtime::Runtime, sync::{Mutex, MutexGuard}, time::{self, Duration} };
async fn add_1(mutex: &Mutex<u64>) {
let mut lock = mutex.lock().await;
*lock += 1;
time::sleep(Duration::from_millis(*lock)).await;
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let mutex = Arc::new(Mutex::new(0));
for i in 0..10 {
let lock = mutex.clone();
tokio::spawn(async move {
add_1(&lock).await;
});
}
time::sleep(Duration::from_secs(1)).await;
});
}前面已经说过,tokio的Mutex性能相对较差一些,因此可以不使用tokio Mutex的情况下,尽量不使用它。对于上面的需求,仍然可以继续使用标准库的Mutex,但需要做一些调整。
例如,可以在子任务await之前,把所有未实现Send的数据都drop掉,保证子任务无法引用父任务中的任何非Send数据。
#![allow(unused)]
fn main() {
use std::sync::{Arc, Mutex, MutexGuard};
async fn add_1(mutex: &Mutex<u64>) {
{
let mut lock = mutex.lock().unwrap();
*lock += 1;
}
// 子任务,跨await,不引用父任务中的数据
time::sleep(Duration::from_millis(10)).await;
}
}这种方案的主要思想是让子任务和父任务不要出现不安全的数据交叉。如果可以的话,应尽量隔离子任务和非Send数据所在的任务。上面的例子已经实现了这一点,但更好的方式是将子任务sleep().await从这个函数中移走。
use std::sync::{Arc, Mutex};
#[allow(unused_imports)]
use tokio::{ self, runtime::Runtime, sync, time::{self, Duration}};
async fn add_1(mutex: &Mutex<u64>) -> u64 {
let mut lock = mutex.lock().unwrap();
*lock += 1;
*lock
} // 申请的互斥锁在此被释放
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let mutex = Arc::new(Mutex::new(0));
for i in 0..100 {
let lock = mutex.clone();
tokio::spawn(async move {
let n = add_1(&lock).await;
time::sleep(Duration::from_millis(n)).await;
});
}
time::sleep(Duration::from_secs(1)).await;
println!("data: {}", mutex.lock().unwrap());
});
}另外注意,标准库的Mutex存在毒锁问题。所谓毒锁,即某个持有互斥锁的线程panic了,那么这个锁有可能永远得不到释放(除非线程panic之前已经释放),也称为被污染的锁。毒锁问题可能很严重,因为出现毒锁有可能意味着数据将从此开始不再准确,所以多数时候是直接让毒锁的panic向上传播或单独处理。但出现毒锁并不总是危险的,所以标准库也提供了对应的方案。
但tokio Mutex不存在毒锁问题,在持有Mutex的线程panic时,tokio的做法是直接释放锁。
RwLock读写锁
相比Mutex互斥锁,读写锁区分读操作和写操作,读写锁允许多个读锁共存,但写锁独占。因此,在并发能力上它比Mutex要更好一些。
下面是官方文档中的一个示例:
use tokio::sync::RwLock;
#[tokio::main]
async fn main() {
let lock = RwLock::new(5);
// 多个读锁共存
{
// read()返回RwLockReadGuard
let r1 = lock.read().await;
let r2 = lock.read().await;
assert_eq!(*r1, 5); // 对Guard解引用,即可得到其内部的值
assert_eq!(*r2, 5);
} // 读锁(r1, r2)在此释放
// 只允许一个写锁存在
{
// write()返回RwLockWriteGuard
let mut w = lock.write().await;
*w += 1;
assert_eq!(*w, 6);
} // 写锁(w)被释放
}需注意,读写锁有几种不同的设计方式:
- 读锁优先: 只要有读操作申请锁,优先将锁分配给读操作。这种方式可以提供非常好的并发能力,但是大量的读操作可能会长时间阻挡写操作
- 写锁优先: 只要有写操作申请锁,优先将锁分配给写操作。这种方式可以保证写操作不会被饿死,但会严重影响并发能力
tokio RwLock实现的是写锁优先,它的具体规则如下:
- 每次申请锁时都将等待,申请锁的异步任务被切换,CPU交还给调度器
- 如果申请的是读锁,并且此时没有写锁存在,则申请成功,对应的任务被唤醒
- 如果申请的是读锁,但此时有写锁(包括写锁申请)的存在,那么将等待所有的写锁释放(因为写锁总是优先)
- 如果申请的是写锁,如果此时没有读锁的存在,则申请成功
- 如果申请的是写锁,但此时有读锁的存在,那么将等待当前正在持有的读锁释放
注意,RwLock的写锁优先会很容易产生死锁。例如,下面的代码会产生死锁:
use std::sync::Arc;
use tokio::{self, runtime::Runtime, sync::RwLock, time::{self, Duration}};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let lock = Arc::new(RwLock::new(0));
let lock1 = lock.clone();
tokio::spawn(async move {
let n = lock1.read().await;
time::sleep(Duration::from_secs(2)).await;
let nn = lock1.read().await;
});
time::sleep(Duration::from_secs(1)).await;
let mut wn = lock.write().await;
*wn = 2;
});
}上面示例中,按照时间的流程,首先会在子任务中申请读锁,1秒后在当前任务中申请写锁,再1秒后子任务申请读锁。
申请第一把读锁时,因为此时无锁,所以读锁(即变量n)申请成功。1秒后申请写锁时,由于此时读锁n尚未释放,因此写锁申请失败,将等待。再1秒之后,继续在子任务中申请读锁,但是此时有写锁申请存在,因此第二次申请读锁将等待,于是读锁写锁互相等待,死锁出现了。
当要使用写锁时,如果要避免死锁,一定要保证同一个任务中的任意两次锁申请之间,前面已经无锁,并且写锁尽早释放。
对于上面的示例,同一个子任务中申请两次读锁,但是第二次申请读锁时,第一把读锁仍未释放,这就产生了死锁的可能。只需在第二次申请读锁前,将第一把读锁释放即可。更完整一点,在写锁写完数据后也手动释放写锁(上面的示例中写完就退出,写锁会自动释放,因此无需手动释放)。
use std::sync::Arc;
use tokio::{self, runtime::Runtime, sync::RwLock, time::{self, Duration}};
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let lock = Arc::new(RwLock::new(0));
let lock1 = lock.clone();
tokio::spawn(async move {
let n = lock1.read().await;
drop(n); // 在申请第二把读锁前,先释放第一把读锁
time::sleep(Duration::from_secs(2)).await;
let nn = lock1.read().await;
drop(nn);
});
time::sleep(Duration::from_secs(1)).await;
let mut wn = lock.write().await;
*wn = 2;
drop(wn);
});
}RwLock还有一些其它的方法,在理解了RwLock申请锁的规则之后,这些方法都很容易理解,可以自行去查看官方手册。
Notify通知唤醒
Notify提供了一种简单的通知唤醒功能,它类似于只有一个信号灯的信号量。
下面是官方文档中的示例:
use tokio::sync::Notify;
use std::sync::Arc;
#[tokio::main]
async fn main() {
let notify = Arc::new(Notify::new());
let notify2 = notify.clone();
tokio::spawn(async move {
notify2.notified().await;
println!("received notification");
});
println!("sending notification");
notify.notify_one();
}Notify::new()创建Notify实例,Notify实例初始时没有permit位,permit可认为是执行权。
每当调用notified().await时,将判断此时是否有执行权,如果有,则可直接执行,否则将进入等待。因此,初始化之后立即调用notified().await将会等待。
每当调用notify_one()时,将产生一个执行权,但多次调用也最多只有一个执行权。因此,调用notify_one()之后再调用notified().await则并无需等待。
如果同时有多个等待执行权的等候者,释放一个执行权,在其它环境中可能会产生惊群现象,即大量等候者被一次性同时唤醒去争抢一个资源,抢到的可以继续执行,而未抢到的等候者又重新被阻塞。好在,tokio Notify没有这种问题,tokio使用队列方式让等候者进行排队,先等待的总是先获取到执行权,因此不会一次性唤醒所有等候者,而是只唤醒队列头部的那个等候者。
Notify还有一个notify_waiters()方法,它不会释放执行权,但是它会一次性唤醒所有正在等待的等候者。严格来说,是让当前已经注册的等候者(即已经调用notified(),但是还未await)在下次等待的时候,可以直接通过。
官方手册给了一个示例:
use tokio::sync::Notify;
use std::sync::Arc;
#[tokio::main]
async fn main() {
let notify = Arc::new(Notify::new());
let notify2 = notify.clone();
// 注册两个等候者
let notified1 = notify.notified();
let notified2 = notify.notified();
let handle = tokio::spawn(async move {
println!("sending notifications");
notify2.notify_waiters();
});
// 两个等候者的await都会直接通过
notified1.await;
notified2.await;
println!("received notifications");
}Barrier屏障
Barrier是一种让多个并发任务在某种程度上保持进度同步的手段。
例如,一个任务分两步,有很多个这种任务并发执行,但每个任务中的第二步都要求所有任务的第一步已经完成。这时可以在第二步之前使用屏障,这样可以保证所有任务在开始第二步之前的进度是同步的。
当然,也不一定要等待所有任务的进度都同步,可以设置等待一部分任务的进度同步。也就是说,让并发任务的进度按批次进行同步。第一批的任务进度都同步后,这一批任务将通过屏障,但是该屏障依然会阻挡下一批任务,直到下一批任务的进度都同步之后才放行。
官方文档给了一个示例,不算经典,但有助于理解:
#![allow(unused)]
fn main() {
use tokio::sync::Barrier;
use std::sync::Arc;
let mut handles = Vec::with_capacity(10);
// 参数10表示屏障宽度为10,只等待10个任务达到屏障点就放行这一批任务
// 也就是说,某时刻已经有9个任务在等待,当第10个任务调用wait的时候,屏障将放行这一批
let barrier = Arc::new(Barrier::new(10));
for _ in 0..10 {
let c = barrier.clone();
handles.push(tokio::spawn(async move {
println!("before wait");
// 在此设置屏障,保证10个任务都已输出before wait才继续向下执行
let wait_result = c.wait().await;
println!("after wait");
wait_result
}));
}
let mut num_leaders = 0;
for handle in handles {
let wait_result = handle.await.unwrap();
if wait_result.is_leader() {
num_leaders += 1;
}
}
assert_eq!(num_leaders, 1);
}Barrier调用wait()方法时,返回BarrierWaitResult,该结构有一个is_leader()方法,可以用来判断某个任务是否是该批次任务中的第一个任务。每一批通过屏障的任务都只有一个leader,其余非leader任务调用is_leader()都将返回false。
使用屏障时,一定要保证可以到达屏障点的并发任务数量是屏障宽度的整数倍,否则多出来的任务将一直等待。例如,将屏障的宽度设置为10(即10个任务一批),但是有15个并发任务,多出来的5个任务无法凑成完整的一批,这5个任务将一直等待。
use std::sync::Arc;
use tokio::sync::Barrier;
use tokio::{ self, runtime::Runtime, time::{self, Duration} };
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
let barrier = Arc::new(Barrier::new(10));
for i in 1..=15 {
let b = barrier.clone();
tokio::spawn(async move {
println!("data before: {}", i);
b.wait().await; // 15个任务中,多出5个任务将一直在此等待
time::sleep(Duration::from_millis(10)).await;
println!("data after: {}", i);
});
}
time::sleep(Duration::from_secs(5)).await;
});
}Semaphore信号量
信号量可以保证在某一时刻最多运行指定数量的并发任务。
使用信号量时,需在初始化时指定信号灯(tokio中的SemaphorePermit)的数量,每当任务要执行时,将从中取走一个信号灯,当任务完成时(信号灯被drop)会归还信号灯。当某个任务要执行时,如果此时信号灯数量为0,则该任务将等待,直到有信号灯被归还。因此,信号量通常用来提供类似于限量的功能。
例如,信号灯数量为1,表示所有并发任务必须串行运行,这种模式和互斥锁是类似的。再例如,信号灯数量设置为2,表示最多只有两个任务可以并发执行,如果有第三个任务,则必须等前两个任务中的某一个先完成。
例如:
use chrono::Local;
use std::sync::Arc;
use tokio::{ self, runtime::Runtime, sync::Semaphore, time::{self, Duration}};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
fn main() {
let rt = Runtime::new().unwrap();
rt.block_on(async {
// 只有3个信号灯的信号量
let semaphore = Arc::new(Semaphore::new(3));
// 5个并发任务,每个任务执行前都先获取信号灯
// 因此,同一时刻最多只有3个任务进行并发
for i in 1..=5 {
let semaphore = semaphore.clone();
tokio::spawn(async move {
let _permit = semaphore.acquire().await.unwrap();
println!("{}, {}", i, now());
time::sleep(Duration::from_secs(1)).await;
});
}
time::sleep(Duration::from_secs(3)).await;
});
}输出结果:
3, 2021-11-17 17:06:38
1, 2021-11-17 17:06:38
2, 2021-11-17 17:06:38
4, 2021-11-17 17:06:39
5, 2021-11-17 17:06:39
tokio::sync::Semaphore提供了以下一些方法:
- close(): 关闭信号量,关闭信号量时,将唤醒所有的信号灯等待者
- is_closed(): 检查信号量是否已经被关闭
- acquire(): 获取一个信号灯,如果信号量已经被关闭,则返回错误AcquireError
- acquire_many(): 获取指定数量的信号灯,如果信号灯数量不够则等待,如果信号量已经被关闭,则返回AcquireError
- add_permits(): 向信号量中额外添加N个信号灯
- available_permits(): 当前信号量中剩余的信号灯数量
- try_acquire(): 不等待地尝试获取一个信号灯,如果信号量已经关闭,则返回TryAcquireError::Closed,如果目前信号灯数量为0,则返回TryAcquireError::NoPermits
- try_acquire_many(): 尝试获取指定数量的信号灯
- acquire_owned(): 获取一个信号灯并消费掉信号量
- acquire_many_owned(): 获取指定数量的信号灯并消费掉信号量
- try_acquire_owned(): 尝试获取信号灯并消费掉信号量
- try_acquire_many_owned(): 尝试获取指定数量的信号灯并消费掉信号量
对于获取到的信号灯SemaphorePermit,有一个forget()方法,该方法可以将信号灯不归还给信号量,因此信号量中的信号灯将永久性地减少(当然,可使用add_permits()添加额外的信号灯)。
信号量的限量功能,也可以通过sync::mpsc通道来实现。大致逻辑为:设置通道宽度为允许的最大并发任务数量,并先填满通道,当执行一个任务时,先从通道取走一个消息,再执行任务,每次执行完任务后都重新向通道中回补一个消息。
parking_lot
虽然tokio自身提供了Mutex、RwLock等同步原语,但它们的性能并不优秀,如果需要更高效的同步原语,可考虑使用parking_lot提供的同步原语。虽然parking_lot的同步原语在等待时是阻塞整个线程的,但不得不提出的是,如果持有锁的时间非常短,那么阻塞线程的时间非常短,这种情况下对异步调度的影响并不大。实际上前文也说了,tokio所提供的Mutex本身就是阻塞线程的。
使用tokio::net进行网络编程
tokio提供了类似std::net所提供的基本设施以便进行异步网络编程,主要包括tcp、udp和unix domain三方面。
网络编程需要大量的网络编程知识,且和IO编程息息相关,因暂时还未介绍tokio::io,所以本文暂且仅介绍tokio::net的tcp编程相关的基础设施,不涉及具体的网络编程逻辑。(所以本文会比较枯燥,基本上是对官方文档的总结和引用)
要使用tokio::net,需在Cargo.toml文件中开启net特性:
tokio = {version = "1.13", features = ["rt", "net", "rt-multi-thread"]}
开启该特性之后,将可使用以下三个组件:
- TcpSocket: 创建和操作套接字的基础组件
- TcpListener: 对TcpSocket的一些封装,主要提供服务端套接字的相关操作
- TcpStream: 代表已建立的可直接传递数据的连接,对客户端来说代表已经被服务端接收,对服务端来说代表accept后的套接字
通常客户端可直接使用TcpStream,服务端可直接使用TcpListener和TcpStream,如果需要自定义修改套接字的选项或属性,则考虑使用TcpSocket。
IpAddr和SocketAddr
在开始介绍tokio::net之前,需先简单介绍一下与之相关的std::net::IpAddr和std::net::SocketAddr(注意它们来自标准库)。
IpAddr
IpAddr封装了IP地址,包括IP v4地址和IP v6地址:
#![allow(unused)]
fn main() {
pub enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}IpAddr实现了FromStr,可直接将代表IP地址的字符串解析为IpAddr:
#![allow(unused)]
fn main() {
let localhsot: IpAddr = "127.0.0.1".parse().unwrap();
}例如:
#![allow(unused)]
fn main() {
use std::net::{IpAddr, Ipv4Addr, Ipv6Addr};
let localhost = IpAddr::V4(Ipv4Addr::new(127, 0, 0, 1));
assert_eq!("127.0.0.1".parse(), Ok(localhost));
}IpAddr还有一些方法,主要是一些布尔判断方法:
- is_ipv4():是否是一个ipv4地址
- is_ipv6():是否是一个ipv6地址
- is_loopack():是否是一个loopback地址
- is_multicast():是否是一个多播地址
- is_unspecified():是否是一个0.0.0.0地址
IpAddr封装了ip v4地址或ip v6地址,以代表ip v4地址的Ipv4Addr为例。可使用new()并提供4个u8参数来创建ip v4地址:
#![allow(unused)]
fn main() {
use std::net::Ipv4Addr;
let localhost = Ipv4Addr::new(127, 0, 0, 1);
}Ipv4Addr实现了FromStr,也可以很方便地直接将字符串解析为ip地址:
#![allow(unused)]
fn main() {
let localhost = "127.0.0.1".parse().unwrap();
}可使用octets()将一个IP地址转换为u8数组,即new()的反向操作:
#![allow(unused)]
fn main() {
use std::net::Ipv4Addr;
let addr = Ipv4Addr::new(127, 0, 0, 1);
assert_eq!(addr.octets(), [127, 0, 0, 1]);
}Ipv4Addr还有其它一些方法,多数都是布尔判断方法:
- is_broadcast(): 是否是广播地址(255.255.255.255)
- is_multicast(): 是否是多播地址(224.0.0.0/4)
- is_private(): 是否是私有地址(10.0.0.0/8、172.16.0.0/12、192.168.0.0/16)
- is_link_local(): 是否是链路本地地址(169.254.0.0/16)
- is_loopback(): 是否是环回地址(127.0.0.0/8)
- is_unspecified(): 是否是0.0.0.0
此外,可直接对地址进行大小比较和等值比较。
SocketAddr
SocketAddr代表包含了IP地址和端口号的套接字地址,它封装了ipv4套接字地址和ipv6套接字地址:
#![allow(unused)]
fn main() {
pub enum SocketAddr {
V4(SocketAddrV4),
V6(SocketAddrV6),
}
}SocketAddr实现了FromStr,因此可直接将代表套接字地址的字符串解析为SocketAddr:
#![allow(unused)]
fn main() {
use std::net::{IpAddr, Ipv4Addr, SocketAddr};
let socket: SocketAddr = "127.0.0.1:8080".parse().unwrap();
}SocketAddr自身也提供了new()方法,需提供IpAddr和端口号(u16)作为参数:
#![allow(unused)]
fn main() {
use std::net::{IpAddr, Ipv4Addr, SocketAddr};
let ip = IpAddr::V4(Ipv4Addr::new(127, 0, 0, 1));
let socket = SocketAddr::new(ip, 8080);
}此外,还有以下几个方法:
- is_ipv4(): 是否是ip v4套接字地址
- is_ipv6(): 是否是ip v6套接字地址
- ip(): 返回IP地址
- port(): 返回端口号
- set_ip(): 修改IP地址
- set_port(): 修改端口号
SocketAddr封装的代表ipv4套接字的SocketAddrV4也很简单直接,可由代表ipv4套接字的字符串解析得到,也可由new()方法创建,其也具有ip()、port()、set_ip()以及set_port()这几个方法。
#![allow(unused)]
fn main() {
use std::net::{Ipv4Addr, SocketAddrV4};
let socket = SocketAddrV4::new(Ipv4Addr::new(127, 0, 0, 1), 8080);
assert_eq!("127.0.0.1:8080".parse(), Ok(socket));
assert_eq!(socket.ip(), &Ipv4Addr::new(127, 0, 0, 1));
assert_eq!(socket.port(), 8080);
}tokio::net::TcpListener
TcpListener代表服务端套接字,可使用bind()方法指定要绑定的地址,bind()之后再await,即可开始监听。
use tokio::net::TcpListener;
#[tokio::main]
async fn main(){
let listener = TcpListener::bind("127.0.0.1:8888").await.unwrap();
}这里的listener代表的是服务端负责监听的套接字。
注意,TcpListener::bind()默认会开启TCP的地址重用选项(SO_REUSEADDR)。如果想要修改该选项或设置其它TCP选项,应使用TcpSocket来创建套接字并设置选项,然后再调用bind()方法得到监听套接字。
得到监听套接字之后,可使用accept()去接收来自客户端的连接请求。accept()会阻塞(等待),直到有新的客户端发起连接请求。
accept()成功,表示和客户端之间成功建立TCP连接(连接进入Established状态),同时它会返回一个新的套接字(TcpStream)和代表客户端的套接字地址(SocketAddr)。可通过该TcpStream和客户端传输数据,可通过该SocketAddr获取客户端的地址和端口信息。如果要获取本地套接字地址相关的信息,可使用listener的local_addr()方法。
通常来说,会在一个无限循环中去accept(),这样可以保证多次接收客户端的连接请求。此外,一般也会为每一个accept()成功后返回的TcpStream去分配一个独立的线程或异步任务,这样可以异步地和每个客户端进行通信,且不影响监听套接字继续监听更多的客户端连接请求。
因此,tcp编程的服务端最基本的处理模式大致如下:
async fn main(){
let listener = TcpListener::bind("127.0.0.1:8888").await.unwrap();
loop {
let (client, client_sock_addr) = listener.accept().await.unwrap();
tokio::spawn(async move {
// 该任务负责处理client
});
}
}此外,tokio的监听套接字可和标准库的监听套接字(std::TcpListener)来回转换。由于tokio只提供了成品套接字,无法设置很多的套接字选项,因此如果需要修改或设置某些套接字选项,需要先构建标准库的套接字并设置选项,然后使用from_std()将标准库套接字转换为tokio的套接字。与from_std()对应的是into_std()。
tokio::net::TcpSocket
TcpSocket用于创建和设置套接字选项,它是未进行连接的套接字,可通过bind()和listen()操作得到服务端的监听套接字,可通过connect()得到客户端的套接字。
例如,创建监听套接字,下面的操作等价于TcpListener.bind()操作,它将监听127.0.0.1:8080端口:
use tokio::net::TcpSocket;
#[tokio::main]
async fn main() {
let addr = "127.0.0.1:8080".parse().unwrap();
let socket = TcpSocket::new_v4().unwrap();
socket.set_reuseaddr(true).unwrap();
socket.bind(addr).unwrap();
let listener = socket.listen(1024).unwrap();
}下面的操作等价于TcpStream::connect()操作,它将连接127.0.0.1:8080并返回该连接的TcpStream:
use tokio::net::TcpSocket;
#[tokio::main]
async fn main() {
let addr = "127.0.0.1:8080".parse().unwrap();
let socket = TcpSocket::new_v4().unwrap();
let stream = socket.connect(addr).await.unwrap();
}TcpStream
TcpStream代表客户端和服务端之间已经建立的可以进行数据通信的TCP连接。当然,TcpStream也提供了connect()方法来方便地建立和TCP服务端的连接。
#![allow(unused)]
fn main() {
let mut stream = TcpStream::connect("127.0.0.1:8080").await.unwrap();
}TcpStream用于客户端和服务端的通信,因此可对其进行读和写。读操作表示接收来自对端发送过来的数据,写操作表示将数据通过TCP连接发送给对端。但是,通常会使用tokio::io::AsyncReadExt和tokio::io::AsyncWriteExt提供的读写API来读写TcpStream,因尚未介绍tokio::io,因此先跳过相关的读写操作。
TcpStream本身也提供了和读写相关的一些api:
- readable(): 等待TcpStream有数据可读
- writable(): 等待TcpStream可写入数据
- ready(): 类似Linux的select系统调用,注册可读、可写、读写关闭等事件后等待这些事件的出现
- try_read(): 尝试以不等待的方式读取TcpStream
- try_read_buf(): 尝试以不等待的方式读取TcpStream,并将读取成功的数据追加到给定的buf中
- 和try_read()不同的是,try_read()每次读取数据后都会从前向后覆盖buf的字节,而try_read_buf()则是将读取的数据追加到buf的尾部
- try_read_vectored(): 尝试以不等待的方式读取TcpStream,并将读取成功的数据分别填充到给定的一个或多个buf中
- 例如,给定了两个64K大小的buf,读取了100K数据,则前64K填充到第一个buf中,剩余的36K填充到第二个buf中
- try_write(): 尝试以不等待的方式写入TcpStream
- try_write_vectored(): 尝试以不等待的方式写入TcpStream,写入的数据源来自于给定的一个或多个buf
- peek(): 从TcpStream中读取数据,但不消费TcpStream中本次读取的数据。即,peek后还可以再次读取这部分数据
- split(): 将TcpStream的读和写进行分离,得到的读、写两端不可跨线程(或任务)
- into_split(): 将TcpStream的读和写进行分离,得到的读、写两端可跨线程(或任务)
稍后将简单介绍这些和读写相关的API的基本用法。
除了以上和IO相关的API,TcpSteam还提供了几个TCP连接选项设置的API:
- set_linger(): 修改TCP连接的
SO_LINGER选项。在关闭连接时如果仍有未发送数据(比如仍然在缓冲等待着更多数据进入),设置该选项决定是否要等待一段时间(期待后续会将缓冲的数据发送出去)才允许关闭TCP连接。若不设置该选项,则默认不等待 - linger(): 获取linger设置的值
- set_nodelay(): 修改TCP连接的
TCP_NODELAY选项。设置该选项后,写入TcpStream的数据都将立即发送,而不会缓冲并等待凑够数据后才发送 - nodelay(): 是否设置了nodelay选项
再来介绍TcpStream提供的和读写相关的API。
通常,读相关的操作(try_read、peek等)会结合readable()来使用,写相关的操作(try_write)会结合writable()来使用。但是注意,即便readable()、writable()的返回分别代表了可读和可写,但这个可读、可写的就绪事件并不能确保真的可读可写,因此读、写时要做好判断。
例如,readable()结合try_read():
use tokio::net::TcpStream;
use std::io;
#[tokio::main]
async fn main() {
let stream = TcpStream::connect("127.0.0.1:8080").await.unwrap();
let mut msg = vec![0; 1024];
loop {
// 等待可读事件的发生
stream.readable().await.unwrap();
// 即便readable()返回代表可读,但读取时仍然可能返回WouldBlock
match stream.try_read(&mut msg) {
Ok(n) => { // 成功读取了n个字节的数据
msg.truncate(n);
break;
}
Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => {
continue;
}
Err(e) => {
return;
}
}
}
println!("GOT = {:?}", msg);
}当然,读写操作也可以结合ready()来使用,调用ready()时可注册感兴趣的事件,当注册的事件之一发生之后,ready()将返回Ready结构体,Ready结构体有一些布尔判断方法,用来判断某个事件是否发生。
例如:
use tokio::io::Interest;
use tokio::net::TcpStream;
use std::io;
#[tokio::main]
async fn main() {
let stream = TcpStream::connect("127.0.0.1:8080").await.unwrap();
loop {
// 注册可读和可写事件,并等待事件的发生
let ready = stream.ready(Interest::READABLE | Interest::WRITABLE).await.unwrap();
// 如果注册的事件中,发生了可读事件,则执行如下代码
if ready.is_readable() {
let mut data = vec![0; 1024];
match stream.try_read(&mut data) {
Ok(n) => {
println!("read {} bytes", n);
}
Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => {
continue;
}
Err(e) => {
return;
}
}
}
// 如果注册的事件中,发生了可写事件,则执行如下代码
if ready.is_writable() {
match stream.try_write(b"hello world") {
Ok(n) => {
println!("write {} bytes", n);
}
Err(ref e) if e.kind() == io::ErrorKind::WouldBlock => {
continue
}
Err(e) => {
return;
}
}
}
}
}peek()可读取TcpStream中的数据,但是和其它读取操作不同,peek()读取之后不会消费TcpStream中的数据。
use tokio::net::TcpStream;
use tokio::io::AsyncReadExt;
#[tokio::main]
async fn main() {
let mut stream = TcpStream::connect("127.0.0.1:8080").await.unwrap();
let mut b1 = [0; 10];
let mut b2 = [0; 10];
let n = stream.peek(&mut b1).await.unwrap();
let n1 = stream.read(&mut b2[..n]).await.unwrap();
}比较关键的是split()方法。TCP连接是全双工通信的,无论是TCP连接的客户端还是服务端,每一端都可以进行读操作和写操作。为了方便描述,此处将其称为读端和写端。即,客户端有读端和写端,服务端也有读端和写端。
通过TcpStream,可进行读操作,也可以进行写操作,正如前面几个示例代码所示。但是,通过TcpStream同时进行读写有时候会很麻烦,甚至无解。很多时候,需要将TcpStream的读端和写端进行分离,然后将分离的读、写两端放进独立的异步任务中去执行读或写操作(此时需跨线程),即一个线程(或异步任务)负责读,另一个线程(或异步任务)负责写。
split()和into_split()正是用来分离TcpStream的读写两端的。
split()可将TcpStream分离为ReadHalf和WriteHalf,ReadHalf用于读,WriteHalf用于写。
#![allow(unused)]
fn main() {
let mut conn = TcpStream::connect("127.0.0.1:8888").await.unwrap();
let (mut read_half, mut write_half) = conn.split();
}split()并没有真正将TcpStream的读写两端进行分离,仅仅只是引用TcpStream中的读端和写端。因此,split()得到的读写两端只能在当前任务中进行读写操作,不允许跨线程跨任务。
into_split()是split()的owned版,分离后可得到OwnedReadHalf和OwnedWriteHalf。它是真正地分离TcpStream的读写两端,它会消费掉TcpStream。OwnedReadHalf和OwnedWriteHalf可跨任务进行读写操作。
#![allow(unused)]
fn main() {
let conn = TcpStream::connect("127.0.0.1:8888").await.unwrap();
let (mut read_half, mut write_half) = conn.into_split();
}请记住TcpStream的split()和into_split()方法,这两个方法在tokio网络编程时非常常用。
理解并掌握tokio的异步IO
任何一个异步框架的核心目标都是异步IO,更高效率的IO编程也是多数时候我们使用异步框架的初衷。
tokio的异步IO组件封装了std::io中的几乎所有东西的异步版本,同步IO和异步IO的API在使用方法上也类似。例如,下面是异步版本的文件读取操作:
use tokio::io::AsyncReadExt;
use tokio::fs::File;
#[tokio::main]
async fn main() {
let mut f = File::open("foo.txt").await.unwrap();
let mut buffer = [0; 10];
// read up to 10 bytes
let n = f.read(&mut buffer).await.unwrap();
println!("The bytes: {:?}", &buffer[..n]);
}tokio::io提供了不少组件,在写代码时可能也会用到一些额外的组件,我自己在学习的时候对这些组件感觉有点懵,因此我觉得非常有必要去搞清楚各个组件是干什么用的,搞清楚之后再去学习组件的相关用法会轻松许多。我会尽量循序渐进地介绍每一个组件。
另外,本文会先从IO读写示例开始引入Rust异步IO编程的方式,然后再尽量从基础开始解释读和写,这部分基础内容可能会较长较枯燥。我觉得对于贯穿多数应用程序的IO来说,解释的篇幅再长都是合理的,它太重要了。此外,即便没有学习过std::io,阅读本文也会对std::io有系统性的理解。
异步IO示例一:文件IO
tokio也支持异步的文件操作,包括文件的IO读写类操作。
例如,按行读取文件:
#![allow(unused)]
fn main() {
let file = tokio::fs::File::open("/tmp/a.log").await.unwrap();
// 将file转换为BufReader
let mut buf_reader = tokio::io::BufReader::new(file).lines();
// 每次读取一行
while let Some(line) = buf_reader.next_line().await.unwrap() {
// 注意lines()中的行是不带结尾换行符的,因此使用println!()而不是print!()
println!("{}", line);
}
}上面将File转换为BufReader将使得读取更为简便,比如上面可以直接按行读取文件。如果不转换为BufReader,而是直接通过File进行读取,将只能按字节来读取。如果文件中的是字符串数据,那么按字节读取时会比较麻烦。
当然,也可以通过read_line()的方式来按行读取:
#![allow(unused)]
fn main() {
let file = tokio::fs::File::open("/tmp/a.log").await.unwrap();
let mut buf_reader = tokio::io::BufReader::new(file);
let mut buf = String::new();
loop {
match buf_reader.read_line(&mut buf).await {
Err(_e) => panic!("read file error"),
// 遇到了文件结尾,即EOF
Ok(0) => break,
Ok(_n) => {
// read_line()总是保留行尾换行符(如果有的话),因此使用print!()而不是println!()
print!("{}", buf);
// read_line()总是将读取的内容追加到buf,因此每次读取完之后要清空buf
buf.clear();
}
}
}
}异步IO示例二:网络IO
网络IO是最常见的IO方式之一,下面是一个非常简单的Client/Server两端通信中的服务端的示例。该示例中,Client/Server两端协议好以行为单位传输数据。
下面是服务端的代码:
use tokio::{
io::{AsyncBufReadExt, AsyncWriteExt},
net::{
tcp::{OwnedReadHalf, OwnedWriteHalf},
TcpListener, TcpStream,
},
sync::mpsc,
};
#[tokio::main]
async fn main() {
let server = TcpListener::bind("127.0.0.1:8888").await.unwrap();
while let Ok((client_stream, client_addr)) = server.accept().await {
println!("accept client: {}", client_addr);
// 每接入一个客户端的连接请求,都分配一个子任务,
// 如果客户端的并发数量不大,为每个客户端都分配一个thread,
// 然后在thread中创建tokio runtime,处理起来会更方便
tokio::spawn(async move {
process_client(client_stream).await;
});
}
}
async fn process_client(client_stream: TcpStream) {
let (client_reader, client_writer) = client_stream.into_split();
let (msg_tx, msg_rx) = mpsc::channel::<String>(100);
// 从客户端读取的异步子任务
let mut read_task = tokio::spawn(async move {
read_from_client(client_reader, msg_tx).await;
});
// 向客户端写入的异步子任务
let mut write_task = tokio::spawn(async move {
write_to_client(client_writer, msg_rx).await;
});
// 无论是读任务还是写任务的终止,另一个任务都将没有继续存在的意义,因此都将另一个任务也终止
if tokio::try_join!(&mut read_task, &mut write_task).is_err() {
eprintln!("read_task/write_task terminated");
read_task.abort();
write_task.abort();
};
}
/// 从客户端读取
async fn read_from_client(reader: OwnedReadHalf, msg_tx: mpsc::Sender<String>) {
let mut buf_reader = tokio::io::BufReader::new(reader);
let mut buf = String::new();
loop {
match buf_reader.read_line(&mut buf).await {
Err(_e) => {
eprintln!("read from client error");
break;
}
// 遇到了EOF
Ok(0) => {
println!("client closed");
break;
}
Ok(n) => {
// read_line()读取时会包含换行符,因此去除行尾换行符
// 将buf.drain(。。)会将buf清空,下一次read_line读取的内容将从头填充而不是追加
buf.pop();
let content = buf.drain(..).as_str().to_string();
println!("read {} bytes from client. content: {}", n, content);
// 将内容发送给writer,让writer响应给客户端,
// 如果无法发送给writer,继续从客户端读取内容将没有意义,因此break退出
if msg_tx.send(content).await.is_err() {
eprintln!("receiver closed");
break;
}
}
}
}
}
/// 写给客户端
async fn write_to_client(writer: OwnedWriteHalf, mut msg_rx: mpsc::Receiver<String>) {
let mut buf_writer = tokio::io::BufWriter::new(writer);
while let Some(mut str) = msg_rx.recv().await {
str.push('\n');
if let Err(e) = buf_writer.write_all(str.as_bytes()).await {
eprintln!("write to client failed: {}", e);
break;
}
}
}上面的Server代码示例中,通过into_split()将TcpStream分离得到OwnedWriteHalf和OwnedReadHalf,并且将这它们分别放进了负责写和读的异步子任务中。
需要注意的是,在read_from_client函数中,将reader转换成了BufReader,在write_to_client函数中将writer转换成了BufWriter。如果不进行转换,直接通过reader也可以进行异步读操作,直接通过writer也能进行异步写操作,但是它们读写的对象都是字节,且没有缓冲空间,操作起来要稍繁琐啰嗦,并且有可能需要自己实现缓冲空间来提高效率。因此,通常会将它们转换为带有Buffer的BufReader和BufWriter,方便读写操作。例如上面示例中可以通过BufReader按行读取(一次读取一行)。
示例中处理网络IO的方式是比较常见的一种方式,还有更多处理方式,比如使用tokio_util::codec::LinesCodec按行读写时将更方便简洁安全。
AsyncRead和AsyncWrite
通过前面的示例可发现,File、TcpStream、OwnedReadHalf/OwnedWriteHalf都具有异步读和写的能力,它们之所以能进行异步读写,是因为它们实现了AsyncRead Trait、AsyncWrite Trait。但它们只能以字节为读写对象。
AsyncRead Trait和AsyncWrite Trait是tokio::io的最基本组件,它们是标准库中Read和Write这两个Trait的异步版本,它们提供了最基本的异步读、写能力:当需要进行异步读、写的时候,不会像同步的读写一样阻塞线程,而是会等待可读、可写事件的发生,同时切换到调度器使其能在等待事件发生的过程中调度其它异步任务来执行。
AsyncReadExt和AsyncWriteExt
AsyncRead和AsyncWrite只是提供了最基本的异步读写能力,它们并没有提供方便的读写方式。好在,只要实现了AsyncRead或AsyncWrite(例如tokio::fs::File、tokio::net::TcpStream都实现了它们),在开启tokio的io-util特性后,就会自动拥有AsyncReadExt和AsyncWriteExt中定义的一些方便的读写方法,例如read()、read_buf()、write()、write_all()、flush()等。
tokio = {version = "1.13", features = ["rt", "io-util", "rt-multi-thread"]
因此,当需要进行异步读写时,几乎总是会导入这两个扩展包:
#![allow(unused)]
fn main() {
use tokio::io::{AsyncReadExt, AsyncWriteExt}
}AsyncReadExt和AsyncWriteExt都提供了很多方法,但其中的多数是同类不同名的方法。因此,要掌握的方法其实并不多。
AsyncReadExt
AsyncReadExt提供了以下几个方法:
- read(): 读取数据并填充到指定的buf中
- read_buf(): 读取数据并追加到指定的buf中,和read()的区别稍后解释
- read_exact(): 尽可能地读取数据填充满buf,即按照buf长度来读取
- read_to_end(): 一直读取并不断填充到指定的Vec Buf中,直到读取时遇到EOF
- read_to_string(): 一直读取并不断填充到指定的String Buf中,直到读取时遇到EOF,要求所读取的是有效的UTF-8数据
- take(): 消费掉Reader并返回一个Take,Take限制了最多只能读取指定数量的数据
- chain(): 将多个Reader链接起来,读完一个目标的数据之后可以接着读取下一个目标
最基本的是read()方法,它从目标中读取一定量的数据并保存到指定的buf中。这里有一些注意事项需要解释清楚,参考下面示例中的注释。
假设在项目根目录下有一个名为a.log的文件,其中有10个字节的数据abcdefghij(没有换行符)。可以使用tokio::fs::File去读取文件数据,这是因为tokio::fs::File实现了AsyncRead。不过要注意,要先在Cargo.toml中开启tokio的fs特性。
tokio = {version = "1.12", features = ["rt", "rt-multi-thread", "fs", "macros", "io-util"]}
读取文件数据的示例代码如下:
use tokio::{self, runtime, fs::File, io::{self, AsyncReadExt}};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
// 打开文件,用于读取,因读取数据时需要更新文件指针位置,因此要加上mut
let mut f = File::open("a.log").await.unwrap();
// 提供buf,用来存放每次读取的数据,因要写入buf,因此加上mut
// 读取的数据都是字节数据,即u8类型,因此为u8类型的数组或vec(或其它类型)
let mut buf = [0u8; 5];
// 读取数据,可能会等待,也可能立即返回,对于文件读取来说,会立即返回,
// 每次读取数据都从buf的index=0处开始覆盖式写入到buf,
// buf容量为5,因此一次读取最多5个字节。
// 返回值为本次成功读取的字节数。
let n = f.read(&mut buf).await.unwrap();
// 由于只读取了n个字节保存在buf中,如果buf容量大于n,
// 那么index=n和后面的数据不是本次读取的数据
// 因此,截取buf到index=n处,这部分才是本次读取的数据
let str = std::str::from_utf8(&buf[..n]);
println!("first read {} bytes: {:?}", n, str);
// 第二次读取5个字节,本次读取之后,a.log中的10个字节都已经被读取,
let n = f.read(&mut buf).await.unwrap();
// 因每次读取都将所读数据从buf的index=0处开始覆盖保存,
// 因此,仍然是通过`&buf[0..n]`来获取本次读取的数据
println!("second read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]));
// a.log中的数据在第二次read时已被读完,再次读取,将遇到EOF,
// 遇到EOF时,read将返回Ok(0)表示读取的数据长度为0,
// 但返回的长度为0不一定代表遇到了EOF,也可能是buf的容量为0
let n = f.read(&mut buf).await.unwrap();
// 因遇到EOF,没有读取到任何数据保存到buf,
// 因此`&buf[..n]`为空slice,转换为字符串则为空字符串
println!("third read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]));
});
}输出结果:
first read 5 bytes: Ok("abcde")
second read 5 bytes: Ok("fghij")
third read 0 bytes: Ok("")
上面的示例中使用数组作为buf,使用Vec也是可以的。
#![allow(unused)]
fn main() {
let mut buf = vec![0u8; 5];
}read()每次将读取的数据从buf的index=0处开始覆盖时保存到buf。另一个方法read_buf()则是追加式保存,这要求每次读取数据时都会自动维护buf的指针位置,因此直接使用数组和Vec作为buf是不允许的。事实上,read_buf()参数要求了应使用实现了bytes::buf::BufMut Trait的类型,它会在维护内部的位移指针,且在需要时会像vec一样自动扩容。
例如bytes::BytesMut实现了bytes::buf::BufMut。在Cargo.toml中添加bytes:
bytes = "1.1"
假设a.log文件的前4字节为abcd,它后面还有几十个字节的数据。示例代码如下:
use tokio::{self, fs::File, io::{self, AsyncReadExt}, runtime};
use bytes::BytesMut;
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let mut f = File::open("a.log").await.unwrap();
// 初始容量为4
let mut buf = BytesMut::with_capacity(4);
// 第一次读取,读取容量大小的数据,即4字节数据,
// 此时BytesMut内部的位移指针在offset = 3处
let n = f.read_buf(&mut buf).await.unwrap();
println!("first read {} bytes: {:?}", n, std::str::from_utf8(&buf));
// 第二次读取,因buf已满,这次将一次性读取剩余所有数据(只请求一次读系统调用),
// BytesMut也将自动扩容以便存放更多数据,且可能会根据所读数据的多少进行多次扩容,
// 所读数据都将从index=4处开始追加保存
let n = f.read_buf(&mut buf).await.unwrap();
println!("second read {} bytes: {:?}", n, std::str::from_utf8(&buf));
});
}输出结果:
first read 4 bytes: Ok("abcd")
second read 36 bytes: Ok("abcdefghijABCDEFGHIJabcdefghij")
read_exact()方法是根据buf的容量来决定读取多少字节的数据,和read()一样的是,每次读取都会将所读数据从buf的index=0处开始覆盖(到了这里应该可以发现一点,除非是内部自动维护buf位置的,都会从index=0处开始覆盖式存储),和read()不一样的是,read_exact()明确了要读取多少字节的数据后(即buf的容量),如果没有读取到这么多数据,就会报错,比如提前遇到了EOF,将报ErrorKind::UnexpectedEof错误。
例如,a.log文件中只有10个字节的数据,但buf的容量为40字节,在read_exact()时会报错。
use tokio::{ self, fs::File, io::{self, AsyncReadExt}, runtime };
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let mut f = File::open("a.log").await.unwrap();
let mut buf = [0u8; 40];
let n = f.read_exact(&mut buf).await.unwrap();
println!("first read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]));
});
}read_to_end()方法提供了一次性读取所有数据的功能,它会不断读取,直到遇到EOF。在不断读取的过程中,buf可能会进行多次扩容,因此buf不是固定大小的数组,而是Vec。这是非常好用的功能,不过对于文件的读取来说,tokio::fs::read()提供了更简单更高效的一次性读取文件所有内容的方式。
另外需要注意的是,read_to_end()所读取的数据是在现有Vec数据的基础上进行追加的,因此,Vec一定会有至少一次的扩容。
例如,a.log文件有10个字节数据,初始Vec buf容量为5,那么这10个数据将从Vec的index=5处开始追加存储。
use tokio::{ self, fs::File, io::{self, AsyncReadExt}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let mut f = File::open("a.log").await.unwrap();
// buf初始容量为5
let mut buf = vec![0u8; 5];
// read_to_end读取的数据,从buf的index=5处开始追加保存
// 返回成功读取的字节数
let n = f.read_to_end(&mut buf).await.unwrap();
println!("first read {} bytes: {:?}", n, buf);
println!("first read {} bytes: {:?}", n, std::str::from_utf8(&buf[(buf.len() - n)..]));
});
}输出结果:
first read 10 bytes: [0, 0, 0, 0, 0, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106]
first read 10 bytes: Ok("abcdefghij")
read_to_string()方法类似于read_to_end(),不同的是它将读取的字节数据直接解析为UTF-8字符串。因此,该方法需指定String作为buf。同样的,read_to_string()所读取的数据会追加在当前String buf的尾部。
use tokio::{ self, fs::File, io::{self, AsyncReadExt}, runtime };
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let mut f = File::open("a.log").await.unwrap();
let mut buf = "xyz".to_string();
let n = f.read_to_string(&mut buf).await.unwrap();
println!("first read {} bytes: {:?}", n, buf);
});
}输出结果:
first read 10 bytes: "xyzabcdefghij"
take()方法可限制最多只读取几个字节的数据,该方法会消费掉Reader,并返回一个Take类型的实例。Take实例内部会保留原来的Reader,并添加了一个限制接下来最多只能读取多少字节的字段limit_。
#![allow(unused)]
fn main() {
pub struct Take<R> {
#[pin]
inner: R, // Move进来的原始的Reader
// Add '_' to avoid conflicts with `limit` method.
limit_: u64, // 最多只允许从Reader中读取多少个字节
}
}当已读数据量达到了限制的数量后,下次再读,将强制遇到EOF,尽管这时候可能还没有遇到内部Reader的EOF。不过,可以通过Take的set_limit()重新修改接下来可最多读取的字节数,set_limit()会重置已读数量,相当于重新返回了一个新的Take实例。当然,需要的时候可以通过remaining()来确定还可允许读取多少数量的数据。
例如,a.log文件有20字节的数据,先通过take()得到限制最多读取5字节Take,通过Take读取2字节,再读取3字节,将遇到EOF,再通过Take的set_limit()修改限制再最多读取10字节。
use tokio::{ self, fs::File, io::{self, AsyncReadExt}, runtime };
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f = File::open("a.log").await.unwrap();
let mut t = f.take(5);
let mut buf = [0u8; 2];
let n = t.read(&mut buf).await.unwrap();
println!( "first read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]) );
let mut buf = [0u8; 3];
let n = t.read(&mut buf).await.unwrap();
println!( "second read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]) );
let mut buf = [0u8; 15];
t.set_limit(10);
let n = t.read(&mut buf).await.unwrap();
println!( "third read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]) );
let n = t.read(&mut buf).await.unwrap();
println!( "fourth read {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]) );
});
}输出结果:
first read 2 bytes: Ok("ab")
second read 3 bytes: Ok("cde")
third read 10 bytes: Ok("fghij01234")
fourth read 0 bytes: Ok("")
另外一个方法chain(),可将两个Reader串联起来(可多次串联),当第一个Reader遇到EOF时,继续读取将自动读取第二个Reader的数据。实际上,当第一个Reader遇到EOF时,串联后得到的Reader不会因此而遇到EOF,只是简单地将内部的done_first字段设置为true,表示第一个Reader已经处理完。只有第二个Reader遇到EOF时,串联后的Reader才遇到EOF。
多数时候用来读取多个文件的数据,当然,也可以将同一个文件串联多次。
use tokio::{ self, fs::File, io::{self, AsyncReadExt}, runtime };
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f1 = File::open("a.log").await.unwrap();
let f2 = File::open("b.log").await.unwrap();
let mut f = f1.chain(f2);
let mut buf = [0u8; 20];
let n = f.read(&mut buf).await.unwrap();
println!("data {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]));
let n = f.read(&mut buf).await.unwrap();
println!("data {} bytes: {:?}", n, std::str::from_utf8(&buf[..n]));
});
}输出结果:
data 10 bytes: Ok("abcdefghij")
data 10 bytes: Ok("0123456789")
从上面示例的结果可知,虽然读完第一个Reader后chain Reader不会EOF,但是读取却会在此停止,下次读取才会继续读取第二个Reader。
但如果使用read_to_end()或read_to_string()则会一次性读完所有数据,因为这两个方法内部会多次读取直到遇到EOF。例如:
use tokio::{self, fs::File, io::{self, AsyncReadExt}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f1 = File::open("a.log").await.unwrap();
let f2 = File::open("b.log").await.unwrap();
let mut f = f1.chain(f2);
let mut data = String::new();
let n = f.read_to_string(&mut data).await.unwrap();
println!("data {} bytes: {:?}", n, data);
});
}输出结果:
data 20 bytes: "abcdefghij0123456789"
上面介绍了AsyncReadExt提供的各种方法,下面再介绍AsyncWriteExt提供的各种方法。
AsyncWriteExt
AsyncWriteExt提供了以下几个方法:
- write(): 将给定的字节数组中的数据写入到Writer中
- write_all(): 将给定的字节数组中的所有数据写入到Writer中
- write_buf(): 将给定buf的数据写入到Writer,每次写入时,buf会自动维护内部的位移指针
- write_all_buf(): 将给定buf的数据全部写入到Writer
- write_vectored(): 将一个或多个buf的所有数据写入到Writer
- flush(): 将缓冲中的数据刷入目标Writer。适用于BufWriter
- shutdown(): 关闭Writer,关闭时如果(BufWriter的)缓冲中还有数据,则会触发flush保证数据刷入Writer
最基础的是write()方法,它尝试将给定的字节数组(即[u8; N])中的所有字节写入到Writer中,但不一定会全部写入成功。
use tokio::{self, fs::File, io::AsyncWriteExt, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
// 以write-only模式打开文件
// 如果文件不存在,则创建,如果已存在,则截断文件
let mut f = File::create("a.log").await.unwrap();
let n = f.write(b"hello world").await.unwrap();
println!("write {} bytes", n);
});
}和write()类似的是write_all()方法,它要求给定的字节数组的所有数据全部写入成功后才返回,除非遇到错误。
flush()方法适用于使用了BufWriter的场景。当使用了BufWriter,写入的数据首先写入到一个缓冲空间,在适当的时候(比如缓冲空间已满时)才会将缓冲空间中的数据真正写入到目标,使用flush()可强制将缓冲空间的数据写入到目标。
use tokio::io::{BufWriter, AsyncWriteExt};
use tokio::fs::File;
#[tokio::main]
async fn main() {
let f = File::create("foo.txt").await.unwrap();
let mut buffer = BufWriter::new(f);
// 这次写入只是写入到缓冲空间
buffer.write_all(b"some bytes").await.unwrap();
// 将缓冲空间的数据刷入writer
buffer.flush().await.unwrap();
}shutdown()用于关闭Writer,shutdown之后,无法再通过writer写入新数据。但如果在关闭时,BufWriter的缓冲空间中还有数据,则会自动将数据刷入到writer。
带缓冲的读、写
虽然AsyncReadExt和AsyncWriteExt提供了方便的读写方法,但是每次调用其中的读、写方法都会立即向操作系统请求发起一次读、写系统调用,如果需要读、写大量数据,且每次只读、写少量字节(比如对于读来说,给定的buf小,但有大量数据要读时),那么会请求非常多次数的系统调用。而每次请求系统调用都意味着要从用户空间陷入操作系统的内核空间,频繁切换上下文会出现大量CPU时间的浪费,IO效率也会随之降低。
并且,浏览一下AsyncReadExt Trait所提供的方法就会发现,它只提供了按字节数读取或读取所有数据的方法,这种读取方式比较原始,有时候也不太方便。很多时候,特别是对文件或终端的读取来说,需要的是更简便的按行读取的方式,即每次读取一行,而想要按行读取,前提是能够在读取时去识别所读数据中的换行符并返回换行符前面的数据。显然,按字节数量来读取时,是不具备这种能力的。
标准库和tokio::io都提供了带缓冲功能的读写组件。当调用读、写方法时,不一定会立即就执行操作系统上的读写操作,而是先尝试从缓冲中读或先写向缓冲:
- 对于读操作,如果缓冲中已经有数据,则直接返回缓冲中的数据,如果缓冲中没有,则请求操作系统发起读系统调用。向操作系统请求读时,有可能会请求比实际所需更多的数据,多出来的数据将先缓冲在缓冲空间中等待可能的下次读取
- 除了提供缓冲空间,还更进一步地提供了按行读取的方式,一直读取到换行符并返回,缓冲中换行符后面剩余的数据则继续保留在缓冲空间中
- 对于写操作,将先写入缓冲,然后按照缓冲模式决定何时执行真正的写操作(即发起写系统调用),此时会将缓冲中的数据写入操作系统(可能是写入操作系统所维护的缓冲空间)。例如,只有当缓冲中的数据达到了8K时才开始真正写入操作系统,如果没有达到8K,则数据一直保存在缓冲中
tokio::io提供了AsyncBufRead Trait,实现该Trait的结构将能够在读写时使用缓冲空间。当然,所需的缓冲空间由实现者自身提供。
注意,只有AsyncBufRead,没有AsyncBufWrite Triat。实际上并不需要AsyncBufWrite,因为写入数据时只是需要一个写缓冲空间来缓冲写操作,实现AsyncBufRead就可以提供和维护一个缓冲空间。也就是说,在必要时,让某个Writer实现AsyncBufRead就可以提供带缓冲的写能力。
当实现了AsyncBufRead时,将自动实现AsyncBufReadExt并获取其中定义的一些方便的方法,这些方法稍后介绍。
如果某Reader或Writer没有实现AsyncBufRead,那么可以使用tokio::io::BufReader和tokio::io::BufWriter来将其转换为带有缓冲空间的Reader或Writer。tokio::io::BufReader和tokio::io::BufWriter内部带有并维护缓冲空间。
#![allow(unused)]
fn main() {
pub struct BufReader<R> {
#[pin]
pub(super) inner: R,
pub(super) buf: Box<[u8]>,
pub(super) pos: usize,
pub(super) cap: usize,
pub(super) seek_state: SeekState,
}
pub struct BufWriter<W> {
#[pin]
pub(super) inner: W,
pub(super) buf: Vec<u8>,
pub(super) written: usize,
pub(super) seek_state: SeekState,
}
}例如,tokio::fs::File没有实现AsyncBufRead,但是可以转换为BufReader和BufWriter:
#![allow(unused)]
fn main() {
let f1 = File::open("foo.txt").await.unwrap();
let mut reader = tokio::io::BufReader::new(f);
let f2 = File::create("foo.txt").await.unwrap();
let mut writer = tokio::io::BufWriter::new(f);
}此外,BufReader和BufWriter分别为读、写提供缓冲功能,还有一个tokio::io::BufStream则同时提供读、写的缓冲功能,它相当于BufReader和BufWriter的结合体。也就是说,BufStream的实例即可进行带缓冲的读,也可以进行带缓冲的写。
#![allow(unused)]
fn main() {
let f1 = File::open("foo.txt").await.unwrap();
let mut reader = tokio::io::BufStream::new(f);
}需注意的是,带缓冲空间的读、写操作不总是比不带缓冲的读、写操作更高效,只有对于多次且少量的读、写操作来说,带缓冲的读写效率会更高。如果是读、写少量次数或一次性读、写大量数据的操作,不带缓冲空间的读、写操作效率会更高一些。
再来介绍AsyncBufReadExt提供的方法的用法,有以下几个方法:
- lines(): 返回Lines,Lines有一个
next_line()方法,可不断地从BufReader中读取下一行(返回内容不包括换行符),直到遇到EOF - read_line(): 从BufReader中读取下一行(返回内容包含换行符)并追加到指定的String buf的尾部
- read_until(): 一直读取,直到遇到指定的字节(分隔符字节)或EOF(返回内容包含分隔符),读取的内容将追加到buf的尾部
- split(): 根据指定的字节将Reader进行划分,返回Split,Split提供了
next_segment()方法,可不断从BufReader中读取下一个分割片段(返回内容不包含分隔符)直到遇到EOF
lines()可按行进行异步迭代式的读取:
use tokio::{self, fs::File, io::{AsyncBufReadExt, BufReader}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f = File::open("a.log").await.unwrap();
let mut lines = BufReader::new(f).lines();
while let Some(line) = lines.next_line().await.unwrap() {
println!("read line: {}", line);
}
});
}类似的,split()是指定分隔符,而不是默认的换行符作为分隔符。例如,指定换行符作为分隔符。
use tokio::{self, fs::File, io::{AsyncBufReadExt, BufReader}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f = File::open("a.log").await.unwrap();
let mut lines = BufReader::new(f).split(b'\n');
while let Some(line) = lines.next_segment().await.unwrap() {
println!("read line: {}", String::from_utf8(line).unwrap());
}
});
}需注意的是,split()方法只能指定字节作为分隔符,不能指定字符分隔符,另外,Split的next_segment()方法读取的数据会保存到Vec<u8>中,而不是直接返回String。
read_line()方法则是从缓冲空间中读取一行,读取的内容(包含换行符)会追加到指定的String buf中:
use tokio::{self, fs::File, io::{AsyncBufReadExt, BufReader}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f = File::open("a.log").await.unwrap();
let mut f = BufReader::new(f);
let mut data = String::new();
f.read_line(&mut data).await.unwrap();
print!("first line: {}", data);
});
}read_until()方法类似于read_line(),只是不是读取到换行符停止,而是读取到指定的分隔符停止。同样的,也只能使用字节分隔符,读取的内容追加到Vec buf中。
use tokio::{self, fs::File, io::{AsyncBufReadExt, BufReader}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let f = File::open("a.log").await.unwrap();
let mut f = BufReader::new(f);
let mut data = Vec::new();
f.read_until(b'\n', &mut data).await.unwrap();
print!("first line: {}", String::from_utf8(data).unwrap());
});
}随机读写Seek
在进行读、写时,会判断从Reader的哪个位置开始读以及从Writer的哪个位置开始写,这个位置称为位置偏移(offset)。
多数情况下,Reader第一次读数据时,是从offset=0处开始读的,即从Reader的第一个字节开始读,读多少字节,偏移指针就向前前进几个字节,下次再读取将从更新后的偏移位置处开始向后读取。
例如,以只读方式打开a.log文件时,第一次读取时,从第一个字节开始读取,如果第一次读取了10个字节,那么偏移指针将更新到文件的index=9处,第二次读取将从index=10处的字节开始读取。一直这样一边读取一边更新位置偏移,直到读完最后一个字节,偏移指针将更新到文件的最尾部,再向后读取将遇到EOF。
同理,写数据时,也会不断递进更新偏移指针。例如从当前位置处写了10个字节,那么偏移指针将向后递增10个字节。
需要注意的是,如果偏移指针的后面还有数据,那么在写数据时,将会逐字节覆盖原本的数据。例如,a.log文件有10个字节的数据,分别是从0到9的数字,当偏移指针位于offset=1处时,写入"ab"两个字节,这两个字节将分别覆盖原来的数字1和2,但3到9保持不变。
此外,可以在代码中轻松修改位置偏移。std::io和tokio::io都提供了操作偏移指针相关的组件:std::io::Seek和tokio::io::AsyncSeek。因为通过它们可以随时修改偏移指针,因此可以从任意位置开始进行读、写操作,这种方式的IO,也常称为随机读写,与通常情况下的顺序读写相对应。
本文介绍tokio相关的随机读写(即如何操作偏移指针),对标准库的随机读写方式完全可以照葫芦画瓢。
tokio::io::AsyncSeek是一个Trait,实现了该Trait的类型可异步操作偏移指针。当实现了该Trait时,将自动实现tokio::io::AsyncSeekExt并从中获取以下几个操作偏移指针的方法:
- seek(): 设置偏移指针的位置并返回新的偏移位置
- rewind(): 将偏移指针设置到offset=0处
- stream_position(): 返回当前偏移指针的位置
例如,tokio::fs::File已经实现了AsyncSeek,当打开a.log文件时,可设置它的偏移指针。假设a.log文件中存放了abcdefghij共10个字节的数据。
use std::io::SeekFrom;
use tokio::{self, fs::File, io::{AsyncReadExt, AsyncSeekExt}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
// 只读方式打开文件时,偏移位置offset = 0
let mut f = File::open("a.log").await.unwrap();
// seek()设置offset = 4,从offset = 4开始读取,即从第5个字节开始读取
// seek()返回设置后的偏移位置
let n = f.seek(SeekFrom::Start(5)).await.unwrap();
println!("set, offset = {}", n);
let mut str = String::new();
f.read_to_string(&mut str).await.unwrap();
// 返回当前的偏移位置
let n = f.stream_position().await.unwrap();
println!("after read, offset = {}, data = {}", n, str);
// 将偏移指针重置于offset = 0处
f.rewind().await.unwrap();
let n = f.stream_position().await.unwrap();
println!("rewind, offset = {}", n);
});
}输出结果:
set, offset = 5
after read, offset = 10, data = fghij
rewind, offset = 0
上面的示例代码中,使用了std::io::SeekFrom,它是一个Enum,用来描述偏移位置。
#![allow(unused)]
fn main() {
pub enum SeekFrom {
Start(u64),
End(i64),
Current(i64),
}
}SeekFrom::Start(u64)描述从最开头(即offset = 0)开始计算的字节数,只能是u64,即可以是0,但不能是负数。例如,SeekFrom::Start(10)表示第10个字节位置处。
SeekFrom::End(i64)描述从最尾部开始计算的字节数,可以是正数、负数或0。例如:
SeekFrom::End(0)表示最尾部的位置,即最后一个字节的后面SeekFrom::End(10)表示最尾部向后的10个字节位置,即最后一个字节的后面10个字节,显然将偏移指针设置到此位置时已经向后超越了边界,但这是允许的。中间的10个字节将成为孔洞。对于文件来说,如果有很多空洞,这样的文件称为稀疏文件SeekFrom::End(-10)表示最尾部向前的10个字节位置,即倒数第10个字节前面、倒数第11个字节的后面。不允许向前超出边界,否则将报错
SeekFfrom::Current(i64)描述从当前偏移指针的位置开始计算的字节数,可以是正数、负数或0。例如:
SeekFrom::Current(0)表示当前偏移指针的位置SeekFrom::Current(10)表示当前偏移指针向后的10个字节位置,允许向后超越边界SeekFrom::Current(-10)表示当前偏移指针向前的10个字节位置,不允许向前超出边界,否则将报错
另外需要了解的是,有以下几个类型实现了AsyncSeek,也就是说它们都能进行随机读写:
tokio::fs::Filetokio::io::BufReadertokio::io::BufWritertokio::io::BufStream
对于带缓冲空间的Reader和Writer需要额外注意,tokio提供的AsyncSeek,只允许在缓冲的底层IO目标中进行seek。也即是说,对BufReader::new(fs::File::open(FILE))进行seek,是对打开的文件进行seek,而不是在缓冲层进行seek。
之所以特地提醒这一点,是因为在某些语言中,允许在缓冲空间中进行seek(也即是说,缓冲空间也维护了一套偏移指针),同时也会提供更底层的方法以便在缓冲的底层IO目标中进行seek。
标准输入、标准输出、标准错误
tokio在开启io-std特性之后,将提供三个函数:
tokio::io::stdin(): 得到tokio::io::Stdin,即标准输入Reader,可从标准输入读取数据tokio::io::stdout(): 得到tokio::io::Stdout,标准输出Writer,可写向标准输出tokio::io::stderr(): 得到tokio::io::Stderr,标准错误Writer,可写向标准错误
例如:
use tokio::{io::{AsyncWriteExt,AsyncReadExt}, runtime};
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let mut stdin = tokio::io::stdin();
let mut stdout = tokio::io::stdout();
// 循环从标准输入中读取数据
loop {
stdout.write(b"entry somethin: ").await.unwrap();
stdout.flush().await.unwrap();
let mut buf = vec![0; 1024];
let n = match stdin.read(&mut buf).await {
Err(_) | Ok(0) => break,
Ok(n) => n,
};
buf.truncate(n);
stdout.write(b"data from stdin: ").await.unwrap();
stdout.write(&buf).await.unwrap();
stdout.flush().await.unwrap();
}
});
}全双工管道DuplexStream
tokio::io::duplex()提供了类似套接字的全双工读写管道:
#![allow(unused)]
fn main() {
// 参数指定管道的容量
fn duplex(max_buf_size: usize) -> (DuplexStream, DuplexStream)
}DuplexStream可读也可写,当管道为空时,读操作会进入等待,当管道空间已满时,写操作会进入等待。
#![allow(unused)]
fn main() {
let (mut client, mut server) = tokio::io::duplex(64);
client.write_all(b"ping").await?;
let mut buf = [0u8; 4];
server.read_exact(&mut buf).await?;
assert_eq!(&buf, b"ping");
server.write_all(b"pong").await?;
client.read_exact(&mut buf).await?;
assert_eq!(&buf, b"pong");
}在两端通信过程中,任意一端的关闭,都会导致写操作报错Err(BrokenPipe),但读操作会继续读取直到管道的内容被读完遇到EOF。
DuplexStream实现了Send和Sync,因此可以跨线程、跨任务进行通信。
下面是模拟一个客户端和服务端,服务端向客户端循环不断地写入当前时间点,客户端不断读取来自服务端的数据并输出。
use chrono::Local;
use tokio::{self, runtime, time};
use tokio::io::{self, AsyncReadExt, AsyncWriteExt, DuplexStream};
fn now() -> String {
Local::now().format("%F %T").to_string()
}
async fn write_duplex(r: &mut DuplexStream) -> io::Result<usize> {
r.write(now().as_bytes()).await
}
async fn read_duplex(mut r: DuplexStream) {
let mut buf = [0u8; 1024];
loop {
match r.read(&mut buf).await {
Ok(0) | Err(_) => break,
Ok(n) => {
if let Ok(data) = std::str::from_utf8(&buf[..n]) {
println!("read from duplex: {}", data);
}
}
};
}
}
fn main() {
let rt = runtime::Runtime::new().unwrap();
rt.block_on(async {
let (client, mut server) = tokio::io::duplex(64);
// client read data from server
tokio::spawn(async move {
read_duplex(client).await;
});
// server write now() to client
loop {
match write_duplex(&mut server).await {
Err(_) | Ok(0) => break,
_ => (),
}
time::sleep(time::Duration::from_secs(1)).await;
}
});
}分离Reader和Writer
tokio::io::split()方法可将可读也可写的目标(Stream)分离为Reader和Writer,Reader专门用于读操作,Writer专门用于写操作。分离得到的Reader和Writer分别称为ReadHalf和WriteHalf。
例如,TcpStream、BufStream、DuplexStream等都是可读也可写的Stream,有时候将它们分离更方便。
例如,上一小节通过DuplexStream模拟客户端和服务端的示例中,服务端只负责写,客户端只负责读,因此,可以将服务端分离为Reader和Writer,并将其Reader关闭,客户端也分离为Reader和Writer,并将其Writer关闭。
注:当然,也可以选择不关闭不用的Reader或Writer。在C语言和其它语言中,几乎总是建议关闭不使用的Reader或Writer,但在Rust中即便不关闭也没有这种担忧。
以修改客户端的读DuplexStream为例,代码如下:
#![allow(unused)]
fn main() {
async fn read_duplex(r: DuplexStream) {
// 将DuplexStream分离为Reader和Writer,
// 不使用Writer,因此关闭Writer
let (mut reader, writer) = tokio::io::split(r);
drop(writer);
let mut buf = [0u8; 1024];
loop {
match reader.read(&mut buf).await {
Ok(0) | Err(_) => break,
Ok(n) => {
if let Ok(data) = std::str::from_utf8(&buf[..n]) {
println!("read from duplex: {}", data);
}
}
};
}
}
}拷贝Reader的数据到Writer
tokio::io::copy()方法可将Reader的所有数据(直到遇到EOF)直接拷贝给Writer。
例如:
#![allow(unused)]
fn main() {
use tokio::io;
let mut reader: &[u8] = b"hello";
let mut writer: Vec<u8> = vec![];
io::copy(&mut reader, &mut writer).await?;
assert_eq!(&b"hello"[..], &writer[..]);
}接下来
本文介绍了tokio提供的IO编程相关的常用组件,对于其他语言来说,通过这些组件,就可以开始上手IO编程了。
但对于Rust语言的编程风格来说还不够,Rust语言充满了抽象,tokio的异步IO也需要一些抽象让某些IO变得更方便。下一篇将介绍Async Stream Sink以及tokio_util::codec按帧(Frame)进行IO的方式。
使用Async Stream和Sink以及codec Framed
在前面介绍异步IO的时候,相关的读写操作都非常底层,要么直接操作字节,要么直接操作更高一层的Buffer,这两种方式都没有明确实际想要读和写的内容是什么,只是最原始的没有意义的字节或字符串。这种原始的操作方式比较底层,也容易出错,更不方便后期扩展和维护。
tokio_util::codec的作用是按照提前制定好的数据格式设计出对应的数据结构,之后直接以该数据结构为读写的操作单位。换句话说,codec其实就是编码和解码的作用,就像serde的角色一样。
而Async Stream和Sink则是相比于直接读写更底层字节字符串而言要更高一层的用来读写有具体意义的数据的工具。codec将AsyncRead和AsyncWrite转换为Stream和Sink,并使得Stream和Sink可以以Frame为读写单位进行读写操作。
tokio、futures、futures_util、futures_core之间的关系
在开始介绍async Stream和Sink之前,有必要先理解清楚这几个库的关系。
在很多地方都看到有人疑惑tokio与futures的关系,大概是因为大家学的第一个Rust异步库是tokio,但却在不少示例和代码中发现引入了futures中的东西,于是产生这种疑惑。看这几个库的文档首页即可找到答案。
这是tokio_stream中的pub use:
#![allow(unused)]
fn main() {
pub use futures_core::Stream;
}这是futures中的pub use:
#![allow(unused)]
fn main() {
pub use futures_core::future::Future;
pub use futures_core::future::TryFuture;
pub use futures_util::future::FutureExt;
pub use futures_util::future::TryFutureExt;
pub use futures_core::stream::Stream;
pub use futures_core::stream::TryStream;
pub use futures_util::stream::StreamExt;
pub use futures_util::stream::TryStreamExt;
pub use futures_sink::Sink;
pub use futures_util::sink::SinkExt;
pub use futures_io::AsyncBufRead;
pub use futures_io::AsyncRead;
pub use futures_io::AsyncSeek;
pub use futures_io::AsyncWrite;
pub use futures_util::AsyncBufReadExt;
pub use futures_util::AsyncReadExt;
pub use futures_util::AsyncSeekExt;
pub use futures_util::AsyncWriteExt;
}这是futures_util中的pub use:
#![allow(unused)]
fn main() {
// 查看futures_util的源码,不难发现Future、Stream、Sink等
// 都是futures_core中对应类型的重新导出
pub use crate::future::Future;
pub use crate::future::FutureExt;
pub use crate::future::TryFuture;
pub use crate::future::TryFutureExt;
pub use crate::stream::Stream;
pub use crate::stream::StreamExt;
pub use crate::stream::TryStream;
pub use crate::stream::TryStreamExt;
pub use crate::sink::Sink;
pub use crate::sink::SinkExt;
pub use crate::io::AsyncBufRead;
pub use crate::io::AsyncBufReadExt;
pub use crate::io::AsyncRead;
pub use crate::io::AsyncReadExt;
pub use crate::io::AsyncSeek;
pub use crate::io::AsyncSeekExt;
pub use crate::io::AsyncWrite;
pub use crate::io::AsyncWriteExt;
}显然,Stream相关的类型和Sink相关的类型,其实都来自于futures_core。因此,在需要使用到Stream相关类型或Sink相关类型的代码文件中,引入以上任意一个库都行。
Async Stream Trait
Stream Trait用于读操作,它模拟Rust标准库的Iterator,可进行迭代式读取和迭代式操作,非常具有Rust的风味。
例如:
use tokio_stream::{self as stream, StreamExt};
#[tokio::main]
async fn main() {
let mut stream = stream::iter(vec![0, 1, 2]);
while let Some(value) = stream.next().await {
println!("Got {}", value);
}
}上面示例中通过tokio_stream::iter()创建了一个Stream,然后通过不断调用Stream的next()方法来读取Stream中的下一个数据。需要注意的是,目前不能对Stream执行for value in stream{}的迭代操作,只能不断显式地调用next()方法来读取。比如可以使用下面两种循环读取的方式。
#![allow(unused)]
fn main() {
while let Some(value) = s.next().await {}
loop {
match s.next().await {
Some(value) => {}
None => break;
}
}
}有很多场景下需要手动提供Stream,上面使用的tokio_stream::iter()是一个很常用的创建Stream的方法,它返回tokio_stream::Iter,该类型实现了Stream。
在tokio_stream::wrappers中还提供了一些对tokio中的类型封装,并将封装后的类型实现了Stream,因此它们都可以直接作为Stream使用。例如,wrappers::ReceiverStream是对tokio::sync::mpsc::Receiver的封装,并实现了Stream。参考https://docs.rs/tokio-stream/latest/tokio_stream/wrappers/index.html。
最后,还有一个比较常用的生成Stream的方式的是使用async-stream crate提供的宏,它可以返回impl Stream类型。
Async Sink Trait
Sink Trait用于写操作。Sink的意思是下沉、沉入,表示可直接通过Sink方便简单地写入有意义的数据,Sink会自动将该数据转换为更底层的字节传输出去(事物放在水面即可,它会自动下沉到底层)。
这就是使用Sink过程中所需要理解的全部啦。
StreamExt和SinkExt
Async Stream和Async Sink都只提供了非常原始的方法,更多时候我们会使用StreamExt和SinkExt中提供的扩展方法来简化读写操作。其中tokio_stream提供了StreamExt,futures和futures_util中提供了StreamExt和SinkExt,因此需要引入相关库才能使用相关的扩展方法。
关于StreamExt提供的用法,可参考官方手册(https://docs.rs/tokio-stream/latest/tokio_stream/trait.StreamExt.html),用法和Iterator没有太大区别,因此不多赘述。
有关SinkExt提供的方法,有必要介绍主要的几个写入方法:
- send():写入Sink并flush
- feed():写入Sink但不flush
- flush():将已经写入Sink的数据flush
- send_all():将给定的Stream中的零或多个数据全部写入Sink并一次或多次flush(自动决定何时flush)
用法示例如下:下面代码中的sink是一个Sink,其传输的有意义的数据格式是字符串,msg类型是字符串。
#![allow(unused)]
fn main() {
// 方式一: feed() + flush()
sink.feed(msg).await.unwrap();
sink.flush().await.unwrap();
// 方式二: send() == feed() + flush()
sink.send(msg).await.unwrap();
// 方式三:send_all(),一次发送一条或多条,但只允许futures::TryStream作为参数,
// 所以要用到futures crates来构建Stream。例如:
// let msgs = vec![Ok("hello world".to_string()), Ok("HELLO WORLD".to_string())];
let msgs = vec!["hello world".to_string(), "HELLO WORLD".to_string()];
let mut ss = futures_util::stream::iter(msgs).map(Ok);
sink.send_all(&mut ss).await.unwrap();
}codec和Framed
tokio_util::codec可以将实现了AsyncRead/AsyncWrite的结果转换为Stream/Sink,得到的Stream和Sink可以以帧Frame为读写单位。
其中:
- 实现了
codec::Decoder的类型可以转换AsyncRead为FramedRead,FramedRead实现了Stream,因此FramedRead可进行按帧读取的操作 - 实现了
codec::Encoder的类型可以转换AsyncWrite为FramedWrite,FramedWrite实现了Sink,因此FramedWrite可进行按帧写入的操作 - 同时实现了Decoder和Encoder的类型可转换为Framed(当然,也可以转换为FramedRead或FramedWrite),Framed既是Stream,也是Sink,可同时进行以帧为单位的读写操作。Framed可通过
split()方法分离出独立的Stream和Sink分别进行读写
codec还提供了几个常用的已经同时实现了Decoder、Encoder的类型:
- LinesCodec:以行为单位的帧
- AnyDelimiterCodec:以指定分隔符为单位的帧
- BytesCodec:以字节为单位的帧
因为它们同时实现了Decoder和Encoder,因此它们可转换为FramedRead、FramedWrite或Framed。
将Decoder、Encoder转换为对应Framed的方式参考如下:
#![allow(unused)]
fn main() {
// T是实现了AsyncRead的类型,例如TcpStream、File等
// D是实现了Decoder的类型,例如LinesCodec、BytesCodec等
let framed_reader = FramedRead::new(T, D);
// T是实现了AsyncWrite的类型,例如TcpStream、File等
// E是实现了Encoder的类型,例如LinesCodec、BytesCodec等
let framed_writer = FramedWrite::new(T, E);
// T是实现了AsyncRead + AsyncWrite的类型,例如TcpStream、File等
// U是实现了Encoder + Decoder的类型,例如LinesCodec、BytesCodec等
let framed = Framed::new(T, U);
// T是实现了AsyncRead + AsyncWrite的类型,例如TcpStream、File等
// 只要实现了Decoder,例如LinesCodec、BytesCodec等,就可以通过它的framed()方法生成Framed
let framed = LinesCodec::new().framed(T);
}例如,通过LinesCodec使TcpStream能够按行进行读写操作,下面是Server端按行读写客户端的一个示例:
use futures_util::stream::{SplitSink, SplitStream};
use futures_util::{SinkExt, StreamExt};
use tokio::net::{TcpListener, TcpStream};
use tokio::sync::mpsc;
use tokio_util::codec::{Framed, LinesCodec};
type LineFramedStream = SplitStream<Framed<TcpStream, LinesCodec>>;
type LineFramedSink = SplitSink<Framed<TcpStream, LinesCodec>, String>;
#[tokio::main]
async fn main() {
let server = TcpListener::bind("127.0.0.1:8888").await.unwrap();
while let Ok((client_stream, _client_addr)) = server.accept().await {
tokio::spawn(async move {
process_client(client_stream).await;
});
}
}
async fn process_client(client_stream: TcpStream) {
// 将TcpStream转换为Framed
let framed = Framed::new(client_stream, LinesCodec::new());
// 将Framed分离,可得到独立的读写端
let (frame_writer, frame_reader) = framed.split::<String>();
// 当Reader从客户端读取到数据后,发送到通道中,
// 另一个异步任务读取该通道,从通道中读取到数据后,将内容按行写给客户端
let (msg_tx, msg_rx) = mpsc::channel::<String>(100);
// 负责读客户端的异步子任务
let mut read_task = tokio::spawn(async move {
read_from_client(frame_reader, msg_tx).await;
});
// 负责向客户端写行数据的异步子任务
let mut write_task = tokio::spawn(async move {
write_to_client(frame_writer, msg_rx).await;
});
// 无论是读任务还是写任务的终止,另一个任务都将没有继续存在的意义,因此都将另一个任务也终止
if tokio::try_join!(&mut read_task, &mut write_task).is_err() {
eprintln!("read_task/write_task terminated");
read_task.abort();
write_task.abort();
};
}
async fn read_from_client(mut reader: LineFramedStream, msg_tx: mpsc::Sender<String>) {
loop {
match reader.next().await {
None => {
println!("client closed");
break;
}
Some(Err(e)) => {
eprintln!("read from client error: {}", e);
break;
}
Some(Ok(str)) => {
println!("read from client. content: {}", str);
// 将内容发送给writer,让writer响应给客户端,
// 如果无法发送给writer,继续从客户端读取内容将没有意义,因此break退出
if msg_tx.send(str).await.is_err() {
eprintln!("receiver closed");
}
}
}
}
}
async fn write_to_client(mut writer: LineFramedSink, mut msg_rx: mpsc::Receiver<String>) {
while let Some(str) = msg_rx.recv().await {
if writer.send(str).await.is_err() {
eprintln!("write to client failed");
break;
}
}
}实现codec的Encoder和Decoder
严格来说,tokio_util::codec已经提供的几种Codec中,只有LinesCodec和AnyDelimiterCodec是比较常用且通用的,而提供的BytesCodec只在某些特殊场景下适合使用。
如果使用二进制数据进行通信(LinesCodec自然是以字符串方式进行通信的),很可能需要自己去实现codec的Decoder和Encoder。
- Encoder:将指定的Rust类型转换为二进制字节数据帧
- Decoder:将二进制字节数据帧转换为指定的Rust类型
一个简单、通用且常用的二进制通信协议格式是| data_len | data |。即:
- 在编码时(Encoder),先计算待发送的二进制数据data的长度,并将长度大小放在帧首,实际数据放在长度的后面,这是一个完整的帧
- 在解码时(Decoder),先读取长度大小,根据读取的长度大小再先后读取指定数量的字节,从而读取一个完整的帧,再将其转换为指定的数据类型
下面是一个完整的示例。
先定义客户端和服务端通信的数据类型:
#![allow(unused)]
fn main() {
/// 请求
#[derive(Debug, Serialize, Deserialize)]
pub struct Request {
pub sym: String,
pub from: u64,
pub to: u64,
}
/// 响应
#[derive(Debug, Serialize, Deserialize)]
pub struct Response(pub Option<Klines>);
/// 对请求和响应的封装,之后客户端和服务端都将通过Sink和Stream来基于该类型通信
#[derive(Debug, Serialize, Deserialize)]
pub enum RstResp {
Request(Request),
Response(Response),
}
}再自定义一个Codec并实现codec::Encoder和codec::Decoder。
#![allow(unused)]
fn main() {
/// 自己定义一个Codec,
/// 并实现Encoder和Decoder,完成 RstResp => &[u8] => RstResp 之间的转换
pub struct RstRespCodec;
impl RstRespCodec {
/// 最多传送1G数据
const MAX_SIZE: usize = 1024 * 1024 * 1024 * 8;
}
/// 实现Encoder,将RstResp转换为字节数据
/// 对于codec而言,直接将二进制数据写入 `dst: &mut BytesMut` 即可
impl codec::Encoder<RstResp> for RstRespCodec {
type Error = bincode::Error;
// 本示例中使用bincode将RstResp转换为&[u8],也可以使用serde_json::to_vec(),前者效率更高一些
fn encode(&mut self, item: RstResp, dst: &mut BytesMut) -> Result<(), Self::Error> {
let data = bincode::serialize(&item)?;
let data = data.as_slice();
// 要传输的实际数据的长度
let data_len = data.len();
if data_len > Self::MAX_SIZE {
return Err(bincode::Error::new(bincode::ErrorKind::Custom(
"frame is too large".to_string(),
)));
}
// 最大传输u32的数据(可最多512G),
// 表示数据长度的u32数值占用4个字节
dst.reserve(data_len + 4);
// 先将长度值写入dst,即帧首,
// 写入的字节序是大端的u32,读取时也要大端格式读取,
// 也有小端的方法`put_u32_le()`,读取时也得小端读取
dst.put_u32(data_len as u32);
// 再将实际数据放入帧尾
dst.extend_from_slice(data);
Ok(())
}
}
/// 实现Decoder,将字节数据转换为RstResp
impl codec::Decoder for RstRespCodec {
type Item = RstResp;
type Error = std::io::Error;
// 从不断被填充的Bytes buf中读取数据,并将其转换到目标类型
fn decode(&mut self, src: &mut BytesMut) -> Result<Option<Self::Item>, Self::Error> {
let buf_len = src.len();
// 如果buf中的数据量连长度声明的大小都不足,则先跳过等待后面更多数据的到来
if buf_len < 4 { return Ok(None); }
// 先读取帧首,获得声明的帧中实际数据大小
let mut length_bytes = [0u8; 4];
length_bytes.copy_from_slice(&src[..4]);
let data_len = u32::from_be_bytes(length_bytes) as usize;
if data_len > Self::MAX_SIZE {
return Err(std::io::Error::new(
std::io::ErrorKind::InvalidData,
format!("Frame of length {} is too large.", data_len),
));
}
// 帧的总长度为 4 + frame_len
let frame_len = data_len + 4;
// buf中数据量不够,跳过,并预先申请足够的空闲空间来存放该帧后续到来的数据
if buf_len < frame_len {
src.reserve(frame_len - buf_len);
return Ok(None);
}
// 数据量足够了,从buf中取出数据转编成帧,并转换为指定类型后返回
// 需同时将buf截断(split_to会截断)
let frame_bytes = src.split_to(frame_len);
match bincode::deserialize::<RstResp>(&frame_bytes[4..]) {
Ok(frame) => Ok(Some(frame)),
Err(e) => Err(std::io::Error::new(std::io::ErrorKind::InvalidData, e)),
}
}
}
}最后,通过使用Sink和Stream,让客户端和服务端基于RstResp来通信。读写RstResp的代码大概如下:
#![allow(unused)]
fn main() {
let framed = Framed::new(client_stream, RstRespCodec);
let (frame_writer, frame_reader) = framed.split::<RstResp>();
// 负责写的
let resp = RstResp::Response(resp);
if frame_writer.send(resp).await.is_err() {
error!("write failed");
}
// 负责读的
loop {
match frame_reader.next().await {
None => {
debug!("peer closed");
break;
}
Some(Err(e)) => {
error!("read peer error: {}", e);
break;
}
Some(Ok(req_resp)) => {
match req_resp {
RstResp::Request(_) => _,
RstResp::Response(_) => _,
};
}
}
}
}客户端和服务端的Codec设计思路
当然,因读取的客户端请求类型(ReqType)和写给客户端的响应类型(RespType)往往是不同的类型,一种处理方式是通过enum合并请求和响应,然后为合并后的类型做Codec的解析。
#![allow(unused)]
fn main() {
#[derive(Serialize, Deserialize)]
enum MyType {
ReqType(Req),
RespType(Resp),
}
pub struct MyTypeCodec;
impl Encoder<MyType> for MyTypeCodec {
type Error = ;
fn encode(&mut self, item: MyType, dst: &mut BytesMut) -> Result<(), Self::Error> {
...
}
}
impl Decoder for MyTypeCodec {
type Item = MyType;
type Error = ;
fn decode(&mut self, src: &mut BytesMut)->Result<Option<Self::Item>,Self::Error> {
...
}
}
}然后将一个TcpStream(以TcpStream为例)构造成MyTypeCodec的FramedRead端和FramedWrite端:
#![allow(unused)]
fn main() {
let framed = Framed::new(tcp_stream, MyTypeCodec::new());
let (frame_writer, mut frame_reader) = framed.split::<MyType>();
}这样处理后,framed_reader端读取时只处理MyType的ReqType分支,RespType端是多余的。
另一种处理方式是,单独为客户端的请求Req和客户端的响应Resp做各自的Codec解析,然后将TcpStream的读端构造为ReqCodec端,将写端构造成RespCodec端。
例如:
/// 为请求类型Req做的Codec解析
pub struct ReqCodec;
impl Encoder<Req> for ReqCodec {
type Error = ;
fn encode(&mut self, item: Req, dst: &mut BytesMut) -> Result<(), Self::Error> {
...
}
}
impl Decoder for ReqCodec {
type Item = Req;
type Error = ;
fn decode(&mut self, src: &mut BytesMut)->Result<Option<Self::Item>,Self::Error> {
...
}
}
/// 为响应类型Resp做的Codec解析
pub struct RespCodec;
impl Encoder<Resp> for RespCodec {
type Error = ;
fn encode(&mut self, item: Resp, dst: &mut BytesMut) -> Result<(), Self::Error> {
...
}
}
impl Decoder for RespCodec {
type Item = Resp;
type Error = ;
fn decode(&mut self, src: &mut BytesMut)->Result<Option<Self::Item>,Self::Error> {
...
}
}
fn main(){
// 将TcpStream的读端和写端分离,分别构造对应的Codec
let (rd, wr) = stream.into_split();
let mut frame_reader = FramedRead::new(rd, ReqCodec);
let frame_writer = FramedWrite::new(wr, RespCodec);
}个人觉得,第二种方式要更清晰一些,后续的处理代码也比第一种方式更简单一些。
Protobuf简介
Protobuf协议简介
Protobuf是类似于json、xml的用于序列化和反序列化的一种更高效的协议。
json和xml是一种编码解码协议,它们用于数据的序列化和反序列化。它们序列化的结果是用户友好的文本格式,人类可直接阅读这类文本,因此也经常用于数据存储、数据展示和文件配置。
Protobuf是一种更为高效的用于序列化和反序列化的协议,它序列化的结果是二进制格式而不是文本(Protobuf文件是用户友好的文本代码,通过编译器文本代码编译成二进制),因此对人类不友好,但对计算机更友好,它序列化的二进制体积比json和xml要小的多,因此在计算机之间传输的效率要高的多。
由于Protobuf序列化的结果是二进制,用户无法直接读取序列化的结果,因此Protobuf只用于序列化和反序列化,而不用于数据展示。当然,也有一些人会用Protobuf来定义配置文件。
Protobuf常配合gRPC使用,客户端将按照Protobuf协议定义的数据进行序列化后发送给对服务端,服务端按照Protobuf协议进行反序列化。
proto3编写和编译示例
本文不介绍protobuf协议的详细内容,只是一个简单的proto文件的示例,protobuf协议的具体语法,参考官方手册https://developers.google.com/protocol-buffers/docs/proto3。
Protobuf有两个协议版本,proto2和proto3,现在主要使用proto3协议。
Protobuf文件以.proto为后缀。
如果使用vscode,建议安装上vscode-proto3插件,同时安装好Protobuf编译器protoc以及格式化程序clang-format工具:
# ubuntu
sudo apt install protobuf-compile libprotobuf-dev clang-format
# windows,据测试,在win下装了clang-format依然无法格式化
# 1.下载win版本的protobuf并解压将bin目录加入到PATH环境变量:
# https://github.com/protocolbuffers/protobuf/releases
# 2.下载完整的llvm,将bin目录加入PATH环境变量,可使用clang-format.exe:
# https://github.com/llvm/llvm-project/releases
# https://github.com/llvm/llvm-project/releases/download/llvmorg-15.0.0/LLVM-15.0.0-win64.exe
然后可编写proto文件。下面是一个.proto文件的内容示例:
// 双斜线和/**/是注释语法
// 指定协议版本,必须写在非注释行的第一行
syntax = "proto3";
// 指定该文件的包名
package voting;
// 定义服务和方法,编译为客户端和服务端代码后,
// 这里面定义的方法名将同时存在于客户端和服务端
service Voting {
rpc Vote(VotingRequest) returns (VotingResponse);
}
// message定义类型,编译后一般转换为对应语言的Struct或某种Class类型
message VotingRequest {
string url = 1;
enum Vote {
UP = 0;
DOWN = 1;
}
Vote vote = 2;
}
message VotingResponse {
string confirmation = 1;
}
写好.proto文件后,接下来是将其进行编译,编译后得到的结果是二进制。但一般不直接编译为二进制,而是将proto中定义的数据结构和服务都转换为各种语言对应的代码,方便在后续的代码中直接使用这些数据结构。
Protobuf官方已经直接支持一些语言,如PHP Python Ruby Java C++等,可以直接使用官方的protoc将proto文件转换为这些语言对应的代码。
# 将voting.proto编译并转换为Python对应的代码,生成的代码文件在当前目录下
$ protoc.exe --python_out=. voting.proto
对于Protobuf官方目前还不支持的语言,比如Rust,需要通过该语言的第三方库进行转换。当然,官方支持的语言也依然有不少编译转换的第三方库,参考https://github.com/protocolbuffers/protobuf/blob/main/docs/third_party.md。
使用Protobuf和tonic
Rust中使用Protobuf
对于Rust语言来说,有quick-protobuf、rust-protobuf、prost等第三方crates可编译Protobuf文件。
目前最流行的是prost,但它需要配合使用prost-build这个crate来进行编译转换。此外,如果protobuf要配合tonic gRPC使用,则可以替换prost-build为tonic-build来编译转换为适配tonic的结构。
以配合tonic使用为例。代码结构:
$ cargo new proto_usage
$ mkdir proto_usage/protos
$ touch proto_usage/protos/voting.proto
$ touch proto_usage/build.rs
$ tree proto_usage
proto_usage
├── Cargo.toml
├── build.rs
├── protos
│ └── voting.proto
└── src
└── main.rs
Cargo.toml的内容:
[dependencies]
prost = "0.11.0"
tokio = { version = "1.21.0", features = ["macros", "rt-multi-thread"] }
tonic = "0.8.1"
[build-dependencies]
tonic-build = "0.8.0"
voting.proto文件内容:
syntax = "proto3";
package voting;
service Voting {
rpc Vote(VotingRequest) returns (VotingResponse);
}
message VotingRequest {
string url = 1;
enum Vote {
UP = 0;
DOWN = 1;
}
Vote vote = 2;
}
message VotingResponse { string confirmation = 1; }
build.rs文件中编写在编译期间编译proto文件的代码:
use std::io::Result;
fn main() -> Result<()> {
tonic_build::compile_protos("protos/voting.proto")?;
Ok(())
}在编译期间,build.rs将会编译voting.proto文件并转换为voting.rs文件,得到voting.rs文件后,就可以在需要的地方导入该文件,导入该文件后就会拥有该文件中定义的数据结构等内容。至于voting.proto文件编译转换后得到的voting.rs文件中到底是什么内容,见后文分析。
例如,在main.rs中导入该文件。src/main.rs文件的内容(此处示例仅导入但并没有使用):
pub mod voting {
tonic::include_proto!("voting");
}
fn main() {}默认情况下,build.rs编译得到的中间文件保存在OUT_DIR环境变量指定的目录中,如果没有明确设置OUT_DIR环境变量,则默认为cargo的构建目录。例如<target_dir>\debug\build\proto_usage-4e6f1dc6a899518f\out\voting.rs。如果没有修改过OUT_DIR环境变量,则可以通过tonic::include_proto!("voting")宏直接导入build.rs编译后得到的voting.rs文件。
如果修改过OUT_DIR环境变量的值,或者tonic_build编译时明确指定了输出路径(稍后给代码),则不能使用tonic::include_proto!宏来导入voting.rs。此时应该用Rust自身提供的宏include!来明确指定导入的路径。参考官方手册说明https://docs.rs/tonic/latest/tonic/macro.include_proto.html。
例如,假设build.rs的输出路径为proto_usage/protos目录:
#![allow(unused)]
fn main() {
pub mod voting {
// tonic::include_proto!("voting");
include!("../protos/voting.rs");
}
}tonic_build提供了方法来修改proto编译后.rs文件的保存路径(注意,修改路径之后需使用include!宏来导入.rs文件):
use std::io::Result;
fn main() -> Result<()> {
//tonic_build::compile_protos("protos/voting.proto")?;
tonic_build::configure()
.build_server(true) // 是否编译生成用于服务端的代码
.build_client(true) // 是否编译生成用于客户端的代码
.out_dir("protos") // 输出的路径,此处指定为项目根目录下的protos目录
// 指定要编译的proto文件路径列表,第二个参数是提供protobuf的扩展路径,
// 因为protobuf官方提供了一些扩展功能,自己也可能会写一些扩展功能,
// 如存在,则指定扩展文件路径,如果没有,则指定为proto文件所在目录即可
.compile(&["protos/voting.proto"], &["protos"])?;
Ok(())
}Protobuf编译成什么样的Rust代码
对于前文的voting.proto文件:
syntax = "proto3";
package voting;
service Voting {
rpc Vote(VotingRequest) returns (VotingResponse);
}
message VotingRequest {
string url = 1;
enum Vote {
UP = 0;
DOWN = 1;
}
Vote vote = 2;
}
message VotingResponse { string confirmation = 1; }
将其编译后得到voting.rs文件,该文件内容并不复杂,可以直接打开看。
更直观的方式在导入它之后,
#![allow(unused)]
fn main() {
pub mod voting {
include!("../protos/voting.rs");
}
}通过文档来了解它包含了什么:
$ cargo doc --open
可以看到,在voting模块下,拥有如下内容:
#![allow(unused)]
fn main() {
voting::{
// 模块部分以及模块中的结构
// 为客户端生成的代码
voting_client::{self, VotingClient},
// 为服务端生成的代码
// Voting是Trait
voting_server::{self, VotingServer, Voting},
// 嵌套在VotingRequest中的Vote类型
voting_request::{self, Vote},
// Structs部分
VotingRequest,
VotingResponse
}
}voting_request、VotingRequest和VotingResponse结构:
#![allow(unused)]
fn main() {
// voting_request中包含了VotingRequest内嵌的enum类型
pub mod voting_request {
#[derive(Clone, Copy, Debug, ...)]
#[repr(i32)]
pub enum Vote {
Up = 0,
Down = 1,
}
}
// 请求类型
#[derive(Clone, PartialEq, ::prost::Message)]
pub struct VotingRequest {
pub url: String,
pub vote: i32,
}
// 内嵌的enum Vote类型和VotingRequest vote字段之间的转换设置
impl VotingRequest {
pub fn vote(&self) -> Vote
pub fn set_vote(&mut self, value: Vote)
}
// 响应类型
#[derive(Clone, PartialEq, ::prost::Message)]
pub struct VotingResponse {
pub confirmation: String,
}
}这些字段都是pub公开的,因此可以直接构建这些类型或直接进行字段赋值。
为客户端生成的voting_client::VotingClient类型,有几个方法需要注意:
#![allow(unused)]
fn main() {
pub fn new(inner: T) -> Self
// 连接服务端并返回VotingClient
pub async fn connect<D>(dst: D) -> Result<Self, Error>
// 在proto文件中通过rpc定义的方法vote,客户端和服务端都有
// 在客户端,它会向服务端发送请求
pub async fn vote(
&mut self,
request: impl IntoRequest<VotingRequest>
) -> Result<Response<VotingResponse>, Status>
}另外注意,VotingClient实现了Clone、Sync以及Send,因此可以跨线程使用。
例如:
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let mut client = VotingClient::connect("http://127.0.0.1:8080").await?;
loop {
......
let url = ...;
let vote = ...;
// 构建请求
let request = tonic::Request::new(VotingRequest {url, vote});
// 发送请求并等待响应
let response = client.vote(request).await?;
println!("Got: '{}' from service", response.get_ref().confirmation);
}
Ok(())
}为服务端生成的voting_server::VotingServer:
#![allow(unused)]
fn main() {
impl<T: Voting> VotingServer<T> {
pub fn new(inner: T) -> Self
pub fn from_arc(inner: Arc<T>) -> Self
}
}其中T: Voting中的Trait Voteing要求实现vote()方法,该方法用于定义服务端接收到客户端请求时要如何处理的逻辑。
例如:
#[derive(Debug, Default)]
pub struct VotingService {}
#[tonic::async_trait]
impl Voting for VotingService {
async fn vote(
&self,
request: Request<VotingRequest>,
) -> Result<Response<VotingResponse>, Status> {
let r: &VotingRequest = request.get_ref();
match r.vote {
0 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("upvoted for {}", r.url) },
})),
1 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("downvoted for {}", r.url) },
})),
_ => Err(Status::new(
tonic::Code::OutOfRange,
"Invalid vote provided",
)),
}
}
}
#[tokio::main]
async fn main() {
let voting_service = VotingService::default();
let server = VotingServer::new(voting_service);
}Rust中使用tonic和Protobuf
将上面的代码综合起来,实现一个通过gRPC通信的客户端和服务端。
$ cargo new tonic_grpc
$ mkdir tonic_grpc/protos
$ touch tonic_grpc/protos/voting.proto
$ touch tonic_grpc/build.rs
$ touch tonic_grpc/src/{client.rs, server.rs}
$ tree tonic_grpc
tonic_grpc/
├── Cargo.toml
├── build.rs
├── protos
│ └── voting.proto
└── src
├── client.rs
├── main.rs
└── server.rs
Cargo.toml内容:
[dependencies]
prost = "0.11.0"
tokio = { version = "1.21.0", features = ["macros", "rt-multi-thread"] }
tonic = "0.8.1"
[build-dependencies]
tonic-build = "0.8.0"
[[bin]]
name = "server"
path = "src/server.rs"
[[bin]]
name = "client"
path = "src/client.rs"
protos/voting.proto内容:
syntax = "proto3";
package voting;
service Voting {
rpc Vote(VotingRequest) returns (VotingResponse);
}
message VotingRequest {
string url = 1;
enum Vote {
UP = 0;
DOWN = 1;
}
Vote vote = 2;
}
message VotingResponse { string confirmation = 1; }
build.rs内容:
use std::io::Result;
fn main() -> Result<()> {
// tonic_build::compile_protos("protos/voting.proto")?;
tonic_build::configure()
.build_server(true)
.build_client(true)
.out_dir("protos")
.compile(&["protos/voting.proto"], &["protos"])?;
Ok(())
}src/server.rs内容:
use tonic::{transport::Server, Request, Response, Status};
use voting::{
voting_server::{Voting, VotingServer},
VotingRequest, VotingResponse,
};
pub mod voting {
// tonic::include_proto!("voting");
include!("../protos/voting.rs");
}
#[derive(Debug, Default)]
pub struct VotingService {}
#[tonic::async_trait]
impl Voting for VotingService {
async fn vote(
&self,
request: Request<VotingRequest>,
) -> Result<Response<VotingResponse>, Status> {
let r: &VotingRequest = request.get_ref();
match r.vote {
0 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("upvoted for {}", r.url) },
})),
1 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("downvoted for {}", r.url) },
})),
_ => Err(Status::new(
tonic::Code::OutOfRange,
"Invalid vote provided",
)),
}
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let address = "[::1]:8080".parse().unwrap();
let voting_service = VotingService::default();
Server::builder()
.add_service(VotingServer::new(voting_service))
.serve(address)
.await?;
Ok(())
}src/client.rs内容:
use std::io::stdin;
use voting::{voting_client::VotingClient, VotingRequest};
use crate::voting::voting_request;
pub mod voting {
// tonic::include_proto!("voting");
include!("../protos/voting.rs");
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let mut client = VotingClient::connect("http://[::1]:8080").await?;
let url = "http://helloworld.com/post1";
loop {
let mut vote: String = String::new();
println!("Voting for <{}>, (d)own or (u)p: ", url);
stdin().read_line(&mut vote).unwrap();
let vote_res = match vote.trim().to_lowercase().chars().next().unwrap() {
'u' => voting_request::Vote::Up,
'd' => voting_request::Vote::Down,
_ => break,
};
// here comes the service invocation
let request = tonic::Request::new(VotingRequest {
url: String::from(url),
vote: vote_res.into(),
});
let response = client.vote(request).await?;
println!("Got: '{}' from service", response.get_ref().confirmation);
}
Ok(())
}运行:
# 终端1,运行server端:
$ cargo run --bin server
# 终端2,运行client端:
$ cargo run --bin client
Voting for <http://helloworld.com/post1>, (d)own or (u)p:
u
Got: 'upvoted for http://helloworld.com/post1' from service
Voting for <http://helloworld.com/post1>, (d)own or (u)p:
d
Got: 'downvoted for http://helloworld.com/post1' from service
Voting for <http://helloworld.com/post1>, (d)own or (u)p:
d
多路复用的grpc
如果某客户端和某服务端之间有多个grpc通信需求,则可以复用连接。
例如,有两个proto文件:protos/voting.proto和protos/hello.proto。内容分别如下:
// voting.proto的内容
syntax = "proto3";
package voting;
service Voting {
rpc Vote(VotingRequest) returns (VotingResponse);
}
message VotingRequest {
string url = 1;
enum Vote {
UP = 0;
DOWN = 1;
}
Vote vote = 2;
}
message VotingResponse { string confirmation = 1; }
// hello.proto的内容
syntax = "proto3";
package hello;
service Greeter {
rpc SayHello(HelloReq) returns(HelloResp);
}
message HelloReq {
string content = 1;
}
message HelloResp {
string content = 1;
}
build.rs文件内容:
use std::io::Result;
fn main() -> Result<()> {
tonic_build::compile_protos("protos/voting.proto")?;
tonic_build::compile_protos("protos/hello.proto")?;
Ok(())
}src/client.rs文件内容:
use greet::{greeter_client::GreeterClient, HelloReq};
use tonic::transport::{Channel, Endpoint};
use voting::{voting_client::VotingClient, VotingRequest};
use crate::voting::voting_request;
pub mod voting { tonic::include_proto!("voting"); }
pub mod greet { tonic::include_proto!("hello"); }
type ThisErr = Box<dyn std::error::Error>;
async fn voting(client: &mut VotingClient<Channel>) -> Result<(), ThisErr> {
let url = "http://helloworld.com/post1";
let mut n = 0;
loop {
let vote_res = if n % 2 == 0 {
voting_request::Vote::Up
} else {
voting_request::Vote::Down
};
let request = tonic::Request::new(VotingRequest {
url: String::from(url),
vote: vote_res.into(),
});
let response = client.vote(request).await?;
println!("voting {}, Got: '{}'", n, response.get_ref().confirmation);
n += 1;
tokio::time::sleep(tokio::time::Duration::from_secs(1)).await;
}
}
async fn greet(client: &mut GreeterClient<Channel>) -> Result<(), ThisErr> {
let mut n = 0;
loop {
let hello_content = format!("hello {}", n);
let req = tonic::Request::new(HelloReq {
content: hello_content,
});
let resp = client.say_hello(req).await?;
println!("greet {}, Got: '{}'", n, resp.get_ref().content);
n += 1;
tokio::time::sleep(tokio::time::Duration::from_secs(1)).await;
}
}
#[tokio::main]
async fn main() -> Result<(), ThisErr> {
// 构建一个transport::channel::Channel
let channel = Endpoint::from_static("http://[::1]:8080").connect().await?;
// 从同一个Channel构建两个客户端
let voting_client = VotingClient::new(channel.clone());
let greet_client = GreeterClient::new(channel);
// 负责投票服务
let task_voting = tokio::spawn(async move {
let mut c = voting_client.clone();
if let Err(e) = voting(&mut c).await {
println!("voting error: {}", e);
}
});
// 负责say hello的服务
let task_greet = tokio::spawn(async move {
let mut c = greet_client.clone();
if let Err(e) = greet(&mut c).await {
println!("greet error: {}", e);
}
});
tokio::try_join!(task_greet, task_voting)?;
Ok(())
}src/server.rs文件内容:
use greet::{
greeter_server::{Greeter, GreeterServer},
HelloReq, HelloResp,
};
use tonic::{transport::Server, Request, Response, Status};
use voting::{
voting_server::{Voting, VotingServer},
VotingRequest, VotingResponse,
};
pub mod voting { tonic::include_proto!("voting"); }
pub mod greet { tonic::include_proto!("hello"); }
#[derive(Debug, Default)]
pub struct VotingService {}
#[tonic::async_trait]
impl Voting for VotingService {
async fn vote(
&self,
request: Request<VotingRequest>,
) -> Result<Response<VotingResponse>, Status> {
let r: &VotingRequest = request.get_ref();
match r.vote {
0 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("upvoted for {}", r.url) },
})),
1 => Ok(Response::new(voting::VotingResponse {
confirmation: { format!("downvoted for {}", r.url) },
})),
_ => Err(Status::new(
tonic::Code::OutOfRange,
"Invalid vote provided",
)),
}
}
}
#[derive(Debug)]
pub struct GreetService;
#[tonic::async_trait]
impl Greeter for GreetService {
async fn say_hello(&self, request: Request<HelloReq>) -> Result<Response<HelloResp>, Status> {
let hello_str = request.into_inner().content;
println!("greet from client: {}", hello_str);
Ok(Response::new(HelloResp { content: hello_str }))
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let address = "[::1]:8080".parse().unwrap();
let voting_service = VotingService::default();
Server::builder()
.add_service(VotingServer::new(voting_service))
.add_service(GreeterServer::new(GreetService))
.serve(address)
.await?;
Ok(())
}更多tonic使用方式
tonic官方给的示例,非常详细:https://github.com/hyperium/tonic/tree/master/examples。例如流式(Stream)的grpc、负载均衡、带tls证书验证等。
如果要编写流式grpc,建议看一遍https://github.com/hyperium/tonic/blob/master/examples/routeguide-tutorial.md。
Rust日志记录
tracing简要说明
- tracing可以记录结构化的日志,可以按区间(span)记录日志,例如一个函数可以作为一个区间单元,也可以自行指定何时进入(span.enter())区间单元
- tracing有
TRACE DEBUG INFO WARN ERROR共5个日志级别,其中TRACE是最详细的级别 - tracing crate提供了最基本的核心功能:
- span:区间单元,具有区间的起始时间和区间的结束位置,是一个有时间跨度的区间
- span!()创建一个span区间,span.enter()表示进入span区间,drop span的时候退出span区间
- event: 每一次事件,都是一条记录,也可以看作是一条日志
- event!()记录某个指定日志级别的日志信息,
event!(Level::INFO, "something happened!"); - trace!() debug!() info!() warn!() error!(),是event!()的语法糖,可以无需再指定日志级别
- 记录日志时,可以记录结构化数据,以
key=value的方式提供和记录。例如:trace!(num = 33, "hello world"),将记录为"num = 33 hello worl"。支持哪些格式,参考https://docs.rs/tracing/latest/tracing/index.html#recording-fields - tracing crate自身不会记录日志,它只是发出event!()或类似宏记录的日志,发出日志后,还需要通过tracing subscriber来收集
- 在可执行程序(例如main函数)中,需要初始化subscriber,而在其它地方(如库或函数中),只需使用那些宏来发出日志即可。发日志和收集记录日志分开,使得日志的处理逻辑非常简洁
- 初始化subscriber的时候,可筛选收集到的日志(例如指定过滤哪些级别的日志)、格式化收集到的日志(例如修改时间格式)、指定日志的输出位置,等等
- 默认清空下,subscribe的默认输出位置是标准输出,但可以在初始化时改变目标位置。如果需要写入文件,可使用tracing_appender crate
- 需注意,使用tracing_appender时,因为是先缓冲日志信息,而不是直接写入文件。他要求必须在main()函数中使用Guard,否则guard被丢弃将不会写入任何信息到文件
示例
Cargo.toml:
[package]
name = "log"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
chrono = "0.4.19"
tracing = "0.1.29"
tracing-appender = "0.2.0"
tracing-subscriber = { version = "0.3.3" }
src/main.rs:
use chrono::Local;
use std::io;
use tracing::*;
use tracing_subscriber::fmt::format::Writer;
use tracing_subscriber::{self, fmt::time::FormatTime};
// 用来格式化日志的输出时间格式
struct LocalTimer;
impl FormatTime for LocalTimer {
fn format_time(&self, w: &mut Writer<'_>) -> std::fmt::Result {
write!(w, "{}", Local::now().format("%FT%T%.3f"))
}
}
// 通过instrument属性,直接让整个函数或方法进入span区间,且适用于异步函数async fn fn_name(){}
// 参考:https://docs.rs/tracing/latest/tracing/attr.instrument.html
// #[tracing::instrument(level = "info")]
#[instrument]
fn test_trace(n: i32) {
// #[instrument]属性表示函数整体在一个span区间内,因此函数内的每一个event信息中都会额外带有函数参数
// 在函数中,只需发出日志即可
event!(Level::TRACE, answer = 42, "trace2: test_trace");
trace!(answer = 42, "trace1: test_trace");
info!(answer = 42, "info1: test_trace");
}
// 在可执行程序中,需初始化tracing subscriber来收集、筛选并按照指定格式来记录日志
fn main() {
// 直接初始化,采用默认的Subscriber,默认只输出INFO、WARN、ERROR级别的日志
// tracing_subscriber::fmt::init();
// 使用tracing_appender,指定日志的输出目标位置
// 参考: https://docs.rs/tracing-appender/0.2.0/tracing_appender/
// 如果不是在main函数中,guard必须返回到main()函数中,否则不输出任何信息到日志文件
let file_appender = tracing_appender::rolling::daily("/tmp", "tracing.log");
let (non_blocking, _guard) = tracing_appender::non_blocking(file_appender);
// 设置日志输出时的格式,例如,是否包含日志级别、是否包含日志来源位置、设置日志的时间格式
// 参考: https://docs.rs/tracing-subscriber/0.3.3/tracing_subscriber/fmt/struct.SubscriberBuilder.html#method.with_timer
let format = tracing_subscriber::fmt::format()
.with_level(true)
.with_target(true)
.with_timer(LocalTimer);
// 初始化并设置日志格式(定制和筛选日志)
tracing_subscriber::fmt()
.with_max_level(Level::TRACE)
.with_writer(io::stdout) // 写入标准输出
.with_writer(non_blocking) // 写入文件,将覆盖上面的标准输出
.with_ansi(false) // 如果日志是写入文件,应将ansi的颜色输出功能关掉
.event_format(format)
.init(); // 初始化并将SubScriber设置为全局SubScriber
test_trace(33);
trace!("tracing-trace");
debug!("tracing-debug");
info!("tracing-info");
warn!("tracing-warn");
error!("tracing-error");
}输出(上面设置了输出到文件/tmp/tracing.log):
// 其中出现的log,是target
2021-12-01T15:09:55.797 TRACE test_trace{n=33}: log: trace1: test_trace answer=42
2021-12-01T15:09:55.797 TRACE test_trace{n=33}: log: trace2: test_trace answer=42
2021-12-01T15:09:55.797 TRACE log: tracing-trace
2021-12-01T15:09:55.797 DEBUG log: tracing-debug
2021-12-01T15:09:55.797 INFO log: tracing-info
2021-12-01T15:09:55.797 WARN log: tracing-warn
2021-12-01T15:09:55.797 ERROR log: tracing-error
不同区域使用不同日志
有时候有需求区分不同的日志,或者不同区域使用不同格式的日志。例如:
#![allow(unused)]
fn main() {
// 先创建一个SubScriber,准备作为默认的全局SubScriber
// finish()将完成SubScriber的构建,返回一个SubScriber
let default_logger = tracing_subscriber::fmt().with_max_level(Level::DEBUG).finish();
// 这段代码不记录任何日志,因为还未开启全局SubScriber
{
info!("nothing will log");
}
// 从此开始,将default_logger设置为全局SubScriber
default_logger.init();
// 创建一个无颜色显示的且只记录ERROR级别的SubScriber
let tmp_logger = tracing_subscriber::fmt()
.with_ansi(false)
.with_max_level(Level::ERROR)
.finish();
// 使用with_default,可将某段代码使用指定的SubScriber而非全局的SubScriber进行日志记录
tracing::subscriber::with_default(tmp_logger, || {
error!("log with tmp_logger, only log ERROR logs");
});
info!("log with Global logger");
}因为init()方法会调用set_global_default(),使得指定的Subscriber被设置为所有线程的全局Subscriber,所有的日志记录都会被该全局Subscriber给接收。如果想要在某个局部位置改变日志记录的目标(Subscriber),甚至在某个位置丢弃所有日志记录,可以参考如下方式:
#![allow(unused)]
fn main() {
// 设置全局Subscriber,从WARN级别开始记录
tracing_subscriber::fmt()
.with_max_level(tracing::Level::WARN)
.init();
// 创建一个不调用init()方法的Subscriber,从TRACE级别开始记录
let sc = tracing_subscriber::fmt()
.with_max_level(Level::TRACE)
.finish();
// 指定局部范围的Subscriber
tracing::subscriber::with_default(sc, || {
// 即便全局Subscriber是WARN级别的,但这条记录仍然会被记录
tracing::info!("This will be logged to stdout");
});
// NoSubscriber是不记录任何日志记录的Subscriber,它会丢弃所有数据
let sc = tracing::subscriber::NoSubscriber::default();
tracing::subscriber::with_default(sc, || {
// 不会被记录
tracing::info!("This will be logged to stdout");
});
}不同crate使用不同级别的日志
有时候我们自己想设置日志级别为debug来调试我们自己的程序,但这也会把其它所引用依赖的crate中的debug的日志输出出来。特别是有些时候其它crate的输出内容非常非常多,这很不友好。
通过开启tracing-subscriber的env-filter特性,可以按crate来设置不同日志级别。
tracing-subscriber = { version = "0.3", features = ["env-filter"] }
然后设置:
#![allow(unused)]
fn main() {
tracing_subscriber::fmt()
.with_env_filter(EnvFilter::from_default_env())
.with_target(false)
.with_file(true)
.with_line_number(true)
.with_ansi(false)
.init();
}使用EnvFilter::from_default_env()后,将读取RUST_LOG环境变量来设置日志级别。
可以是简单的格式,也可以是复杂的格式。假设我们自己的crate名叫crate_a,引用了一个名为crate_b的包。示例如下:
# 我们自己的以及所依赖的所有crate的日志级别都设置为debug
RUST_LOG=debug cargo run --release
# 关闭其它所有crate的输出,只设置自己的crate的级别为debug
RUST_LOG=none,crate_a=debug cargo run --release
# 默认级别为info,但我们自己的crate为debug
RUST_LOG=info,crate_a=debug cargo run --release
# 默认级别为debug,但关闭crate_b的日志
RUST_LOG=debug,crate_b=off cargo run --release
修改日志记录的时区
默认情况下,tracing-subscriber记录的时间是UTC时间,而不会主动输出为本机设置的时区对应的时间。但是对于东八区的我们来说,希望记录的是东八区的时间。
前面示例中提供了一种修改为本地时间的方式,并且是基于chrono crate而不是默认的time crate来设置tracing-subscriber的日志时间的时区和格式:
use tracing_subscriber::{
self,
fmt::{format::Writer, time::FormatTime},
};
// 用来格式化日志的输出时间格式
struct LocalTimer;
impl FormatTime for LocalTimer {
fn format_time(&self, w: &mut Writer<'_>) -> std::fmt::Result {
write!(w, "{}", chrono::Local::now().format("%FT%T%.3f"))
}
}
fn main() {
tracing_subscriber::fmt().with_timer(LocalTimer).init();
tracing::info!("hello world");
}但注意,使用chrono::Local::now()的效率相对会差一些,因为每次获取时间都要探测本机的时区。因此可改进为使用Offset的方式,明确指定时区,无需探测:
#![allow(unused)]
fn main() {
struct LocalTimer;
const fn east8() -> Option<chrono::FixedOffset> {
chrono::FixedOffset::east_opt(8 * 3600)
}
impl FormatTime for LocalTimer {
fn format_time(&self, w: &mut Writer<'_>) -> std::fmt::Result {
let now = chrono::Utc::now().with_timezone(&east8().unwrap());
write!(w, "{}", now.format("%FT%T%.3f"))
}
}
}当然,还有其它一些方式设置tracing-subscriber日志时间的时区和格式。例如可以通过它的fmt::time::OffsetTime指定时区,不过它使用的是time crate,因此如果记录非UTC时区,则先设置Cargo.toml:
tracing-subscriber = {version = "0.3", features = ["time"]}
time = { version = "0.3", features = ["macros"] }
然后设置日志时间的时区和格式:
use time::macros::{format_description, offset};
use tracing_subscriber::fmt::time::OffsetTime;
fn main() {
let time_fmt = format_description!("[year]-[month]-[day]T[hour]:[minute]:[second].[subsecond digits:3]");
let timer = OffsetTime::new(offset!(+8), time_fmt);
tracing_subscriber::fmt().with_timer(timer).init();
tracing::info!("offset: {}, hello world", offset);
}